Repeated incremental writes, SQL jobs, and Tunnel imports each produce a separate output file per task. Over time, partitions accumulate thousands of sub-64 MB files. This degrades query performance and increases load on the Apsara Distributed File System (ADFS). Merging small files consolidates them into fewer, larger files and restores query performance.
MaxCompute handles most merging automatically. Run the merge command manually only when automatic merging cannot keep pace with continuous writes.
How it works
MaxCompute uses two mechanisms to control small-file accumulation:
Automatic merging — After a job completes, MaxCompute allocates a Fuxi task to merge small files when the file count in a partition exceeds the threshold. By default, a Fuxi instance can process a maximum of 100 small files. You can identify automatic merges by the MergeTask entry in the job log. MaxCompute also periodically scans the metadatabase and merges small files in any table or partition with a high file count.
Manual merging — When data is written to a table continuously and automatic merging cannot keep pace, stop the write job and run the MERGE SMALLFILES command manually.
Limitations
Merging small files consumes compute resources. On pay-as-you-go instances, fees are charged at the same rate as SQL pay-as-you-go billing. For pricing details, see Computing pricing (pay-as-you-go).
The
MERGE SMALLFILEScommand does not support transactional tables. To compact a transactional table, use the COMPACTION command instead.
Check the file count in a table
Run DESC EXTENDED to see how many files a table or partition contains.
Syntax
DESC EXTENDED <table_name> [PARTITION (<pt_spec>)];Parameters
| Parameter | Required | Description |
|---|---|---|
table_name | Yes | The name of the table to inspect |
pt_spec | No | The target partition. Format: (partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...) |
Example output

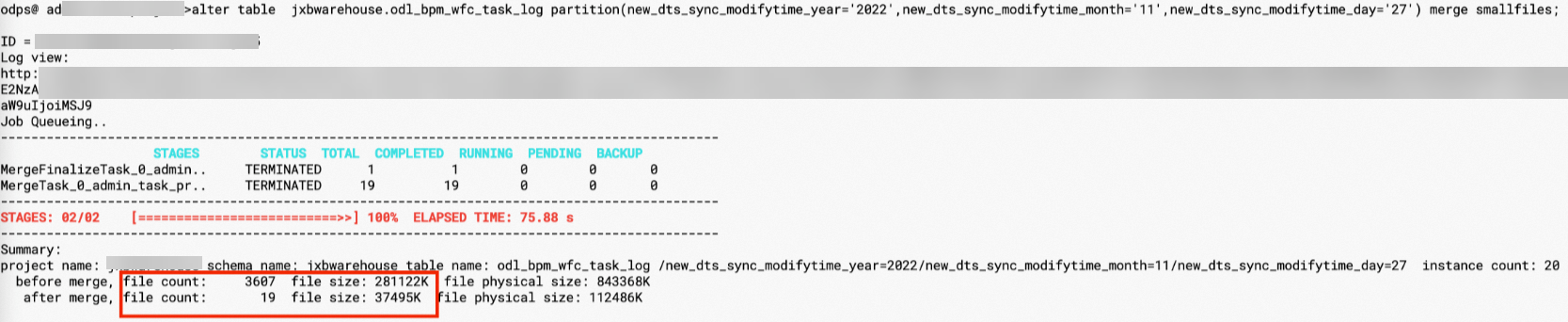
The example above shows the odl_bpm_wfc_task_log table: 3,607 files, total size 274 MB (287,869,658 bytes), average file size ~0.07 MB. This partition is a good candidate for merging.
When to merge: If a partition contains more than 100 files and the average file size is below 64 MB, merge the small files.
Merge small files
Using a SQL command
Run the following command to merge small files on demand:
ALTER TABLE <table_name> [PARTITION (<pt_spec>)] MERGE SMALLFILES;After the merge, the odl_bpm_wfc_task_log table drops from 3,607 files to 19 files, and storage shrinks from 274 MB to 37 MB.
The default parameters work for most cases. Use the following SET parameters to adjust merge behavior when needed:
| Parameter | Description | Default |
|---|---|---|
odps.merge.cross.paths | Whether to merge files across paths. Set to true to merge small files in each path separately without changing the path structure. | — |
odps.merge.smallfile.filesize.threshold | Files at or below this size (in MB) are eligible for merging. If not set, uses the global variable odps_g_merge_filesize_threshold (default: 32 MB). Set to a value greater than 32 when overriding. | 32 MB |
odps.merge.maxmerged.filesize.threshold | Maximum size (in MB) of a single output file after merging. A new output file is created when this limit is reached. If not set, uses the global variable odps_g_max_merged_filesize_threshold (default: 500 MB). Set to a value greater than 500 when overriding. | 500 MB |
odps.merge.max.filenumber.per.instance | Maximum number of files a single merge instance can process. | — |
odps.sql.mapper.merge.limit.size | Maximum total size of files a Fuxi instance reads. | — |
Using PyODPS
Use PyODPS to submit merge tasks asynchronously — useful for merging multiple partitions produced by the previous day's jobs.
All examples use odps.run_merge_files() to submit an asynchronous merge task per partition, then wait for all tasks to complete.
import os
from odps import ODPS
# Load credentials from environment variables.
# Do not hardcode your AccessKey ID or AccessKey secret in your code.
o = ODPS(
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'),
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
project='<your-project>',
endpoint='<your-endpoint>',
)
# Replace <table_name> with the name of your table.
table_name = '<table_name>'
t = o.get_table(table_name)
# Set merge options.
hints = {'odps.merge.maxmerged.filesize.threshold': 256}
# Submit one merge task per partition under the target date.
# Replace <datetime> with the date value to target, e.g., '20240101'.
insts = []
for partition in t.iterate_partitions(spec='ds=<datetime>'):
instance = o.run_merge_files(table_name, str(partition), hints=hints)
# Open this Logview URL and click Waiting Queue to find the merge job log.
print(instance.get_logview_address())
insts.append(instance)
# Wait for all merge tasks to finish.
for inst in insts:
inst.wait_for_completion()Replace the following placeholders before running the script:
| Placeholder | Description | Example |
|---|---|---|
<your-project> | Your MaxCompute project name | my_project |
<your-endpoint> | Your MaxCompute endpoint | <your-region-endpoint> |
<table_name> | The table to merge | my_log_table |
<datetime> | The partition date value to target | 20240101 |
Install PyODPS before running the script. For installation instructions, see the PyODPS documentation.
Example
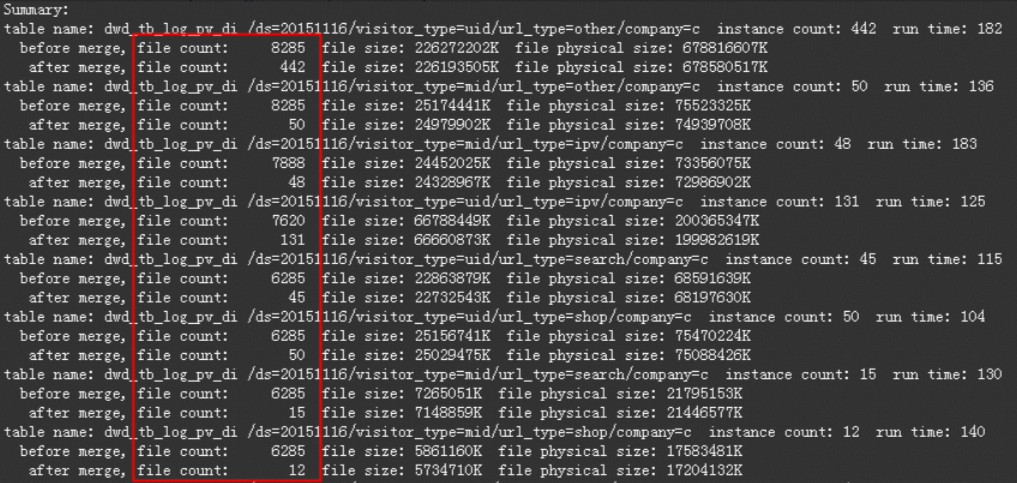
A data stability check identifies that tbcdm.dwd_tb_log_pv_di needs merging. Querying the metadata table tbcdm.dws_rmd_merge_task_1d reveals that most partitions exceed 1,000 files, some exceed 7,000 files, and several partitions have an average file size below 1 MB.

Run the following commands to merge the small files:
SET odps.merge.cross.paths=true;
SET odps.merge.smallfile.filesize.threshold=128;
SET odps.merge.max.filenumber.per.instance = 2000;
ALTER TABLE tbcdm.dwd_tb_log_pv_di PARTITION (ds='20151116') MERGE SMALLFILES;The result after merging:
What's next
COMPACTION — Compact data in transactional tables
Computing pricing (pay-as-you-go) — Understand merge job billing