Hash clustering stores table data based on hash distribution and sorting at write time, so MaxCompute can skip shuffle and sort operations during queries. This reduces CPU time, job duration, and storage consumption for large tables with repeated join or aggregation patterns.
When to use hash clustering
Hash clustering is most effective when your table meets all of the following conditions:
The table contains a large amount of data
Queries frequently filter, join, or aggregate on the same columns
The same join or aggregation pattern runs repeatedly against the table
The table has a long lifecycle, making storage savings worthwhile
If queries on the table use varied and unpredictable access patterns, hash clustering provides limited benefit.
How it works
In many scenarios, tables need to be joined. MaxCompute provides the following join methods:
Broadcast hash join: If one of the to-be-joined tables is a small table, MaxCompute broadcasts the small table to all join task instances and performs a hash join between the small table and the big table.
Shuffle hash join: If both tables are large, a hash shuffle is performed on both tables based on join keys. Records with the same key values are distributed to the same join task instance, which then performs the join.
Sort merge join: If both tables are very large (memory is insufficient for a hash table), MaxCompute performs a hash shuffle on both tables based on join keys, sorts the results, and merges them. In a job with M mappers and R reducers, this produces M × R I/O operations. This is the most common join method in MaxCompute.
The physical execution plan of a Fuxi job for a sort merge join requires two map stages and one join stage. The shuffle and sort operations are highlighted below. 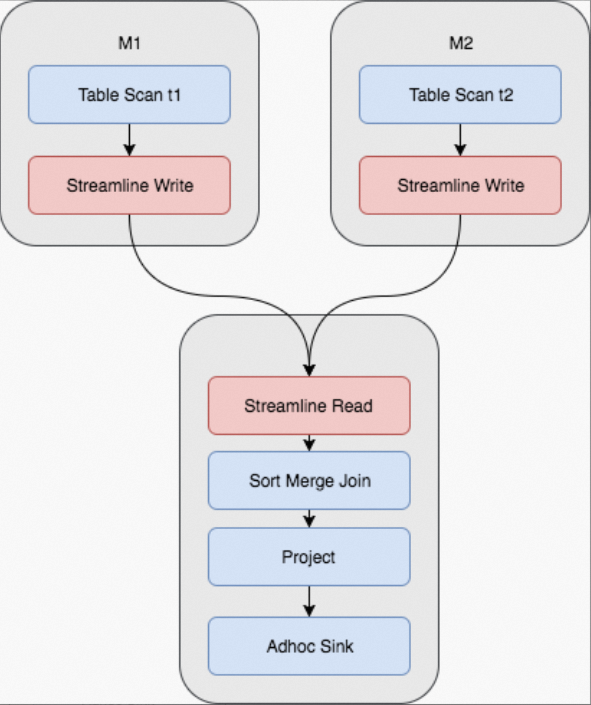
With hash clustering, data is distributed into buckets by hash value and sorted within each bucket at write time. Subsequent queries that join or filter on the cluster key skip the shuffle and sort entirely, reducing a multi-stage Fuxi job to a single stage. 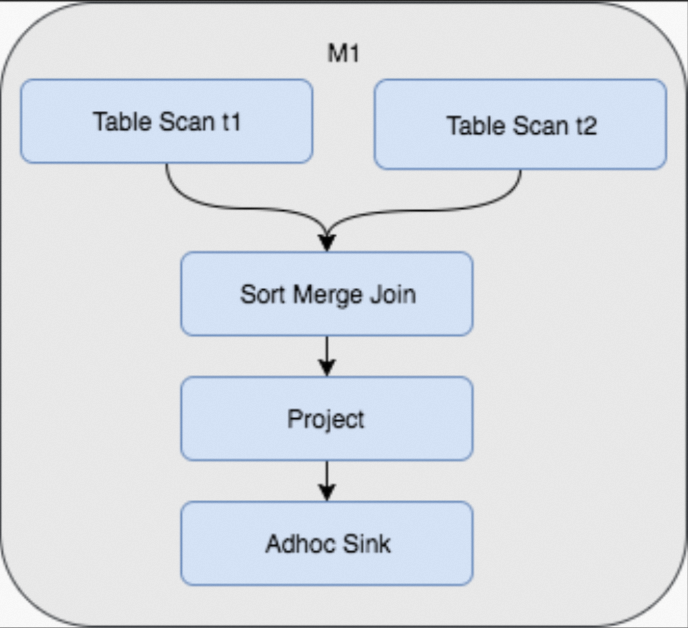
Three specific optimizations apply:
Bucket pruning and index lookup: A query with a WHERE clause on the cluster key reads only the matching bucket instead of all buckets. MaxCompute also builds indexes automatically when SORTED BY is set, allowing index lookup to locate matching records by page. For example, a query that matches 26 records out of 42.7 billion can drop from 1,111 mappers scanning all data to 4 mappers scanning 10,000 records—reducing runtime from 1 minute and 48 seconds to 6 seconds.
Aggregate optimization: A GROUP BY query on the cluster key skips shuffle and sort. MaxCompute performs a stream aggregate directly on the pre-sorted data.
Storage optimization: MaxCompute uses column store at the storage layer. Sorted data compresses significantly better than unsorted data because records with similar key values are stored together. In practice, the same dataset with hash clustering uses about 10% less storage; in extreme cases, the savings can reach 50%.
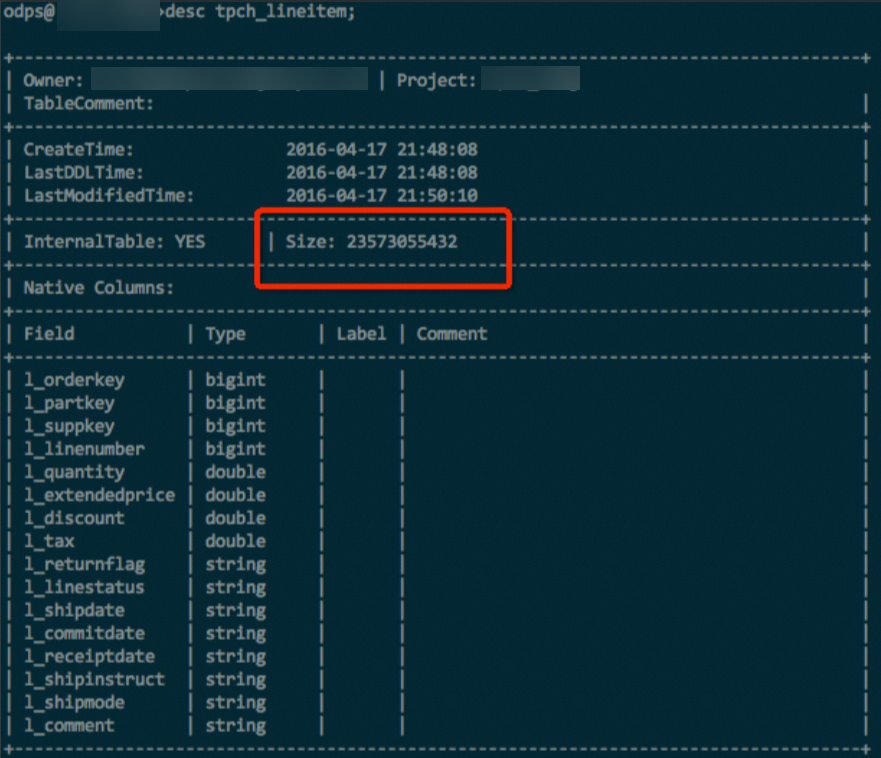
Hash clustering is not used.
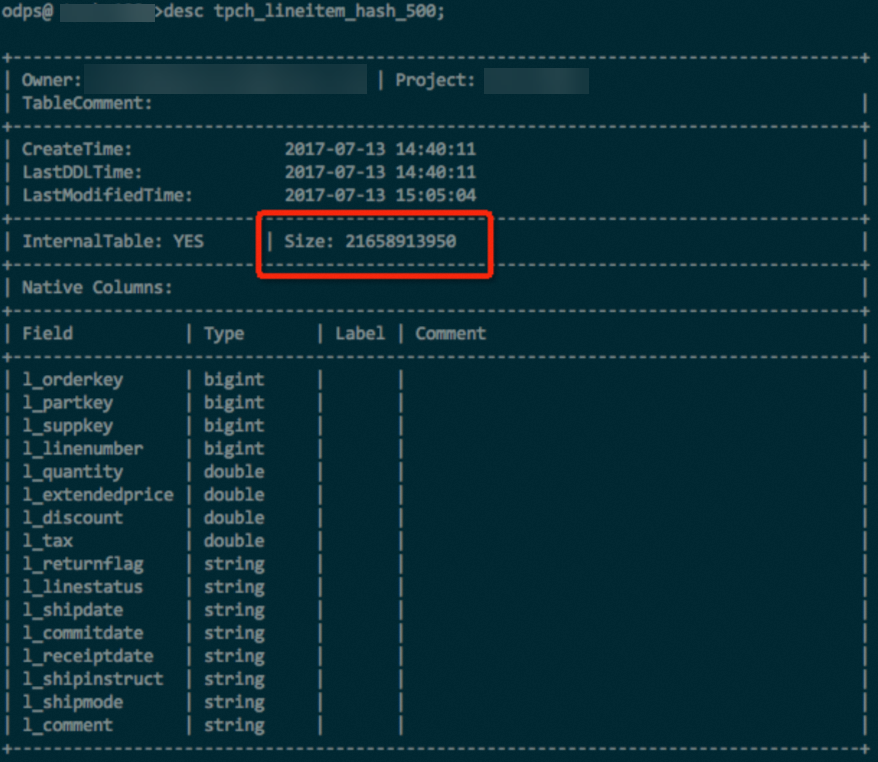
Hash clustering is used.
TPC-H benchmark results: On 1 TB of data across 500 buckets, hash clustering reduced total CPU time by about 17.3% and total job duration by about 12.8%. For queries that use clustering effectively—such as TPC-H Q4, Q12, and Q10—the improvement was 68%, 62%, and 47%, respectively.
The following figure shows the execution plan of a Fuxi job for TPC-H Q4 queries on a common table. 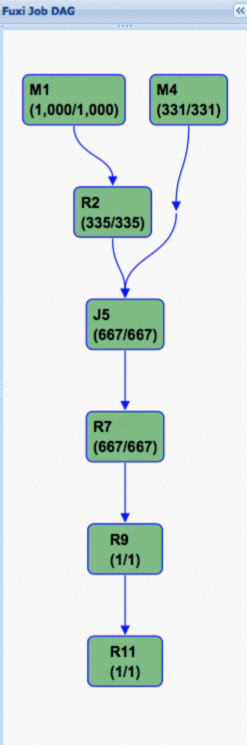 The following figure shows the execution plan after hash clustering is enabled. The directed acyclic graph (DAG) is significantly simplified, which is the key to performance improvement.
The following figure shows the execution plan after hash clustering is enabled. The directed acyclic graph (DAG) is significantly simplified, which is the key to performance improvement. 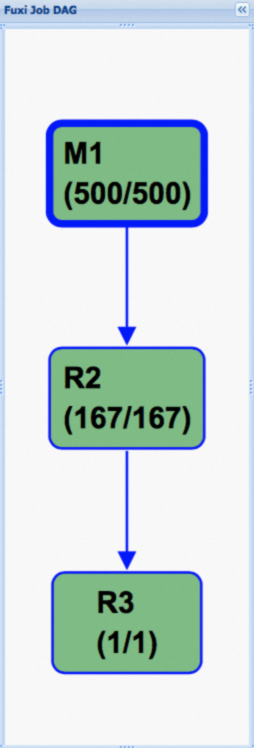
Create a hash-clustered table
Syntax
CREATE TABLE [IF NOT EXISTS] <table_name>
[(<col_name> <data_type> [COMMENT <col_comment>], ...)]
[COMMENT <table_comment>]
[PARTITIONED BY (<col_name> <data_type> [COMMENT <col_comment>], ...)]
[CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS] [AS <select_statement>]Parameters
`CLUSTERED BY` (required)
Specifies the cluster keys—the columns MaxCompute uses to hash and distribute data into buckets. To prevent data skew issues and hot spots and improve concurrent execution efficiency, specify columns with large value ranges and few duplicate values. To optimize join operations, select commonly used join keys or aggregate keys.
`SORTED BY` (optional)
Specifies the sort order within each bucket. Set this to the same columns as CLUSTERED BY to enable index lookup and improve query performance for range and equality filters. MaxCompute automatically generates indexes when SORTED BY is specified.
`INTO <number_of_buckets> BUCKETS` (required)
Specifies the number of buckets. Determine this based on data volume:
Target a bucket size between 500 MB and 1 GB
For very large tables, you can increase the target bucket size
Set the bucket count to a power of 2 (for example, 512, 1,024, 2,048, or 4,096) so MaxCompute can automatically split and merge buckets
For join optimization between two tables, the bucket count in one table must be a multiple of the bucket count in the other (for example, 256 and 512)
Examples
Non-partitioned table:
CREATE TABLE T1 (a string, b string, c bigint)
CLUSTERED BY (c)
SORTED BY (c) INTO 1024 BUCKETS;Partitioned table:
CREATE TABLE T1 (a string, b string, c bigint)
PARTITIONED BY (dt string)
CLUSTERED BY (c)
SORTED BY (c) INTO 1024 BUCKETS;Modify the clustering properties of a table
For partitioned tables, use ALTER TABLE to add or remove hash clustering properties.
-- Add hash clustering to an existing partitioned table
ALTER TABLE <table_name> [CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS];
-- Remove hash clustering from a partitioned table
ALTER TABLE <table_name> NOT CLUSTERED;Usage notes
ALTER TABLEapplies only to partitioned tables. The clustering properties of a non-partitioned table cannot be modified after they are added.ALTER TABLEaffects only new partitions—including partitions written byINSERT OVERWRITE. Existing partitions retain their original storage format.You cannot target a specific partition in an
ALTER TABLEstatement.
Verify hash clustering properties
After creating a hash-clustered table, run DESC EXTENDED to confirm the clustering properties. Look for the hash clustering configuration in Extended Info of the output.
DESC EXTENDED <table_name>;The following figure shows an example of the returned result. 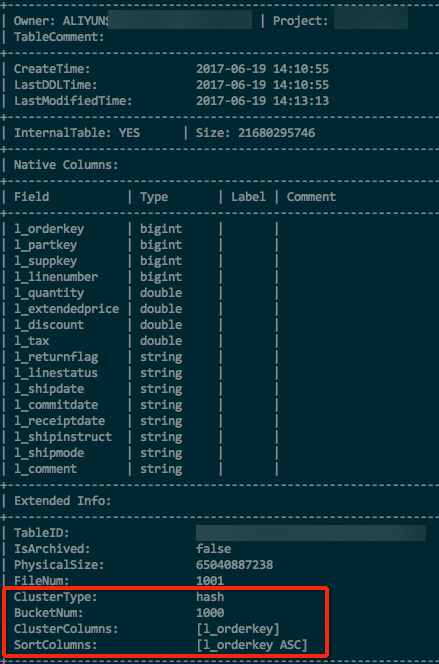
For partitioned tables, also check a specific partition:
DESC EXTENDED <table_name> PARTITION (<pt_spec>);The following figure shows an example of the returned result. 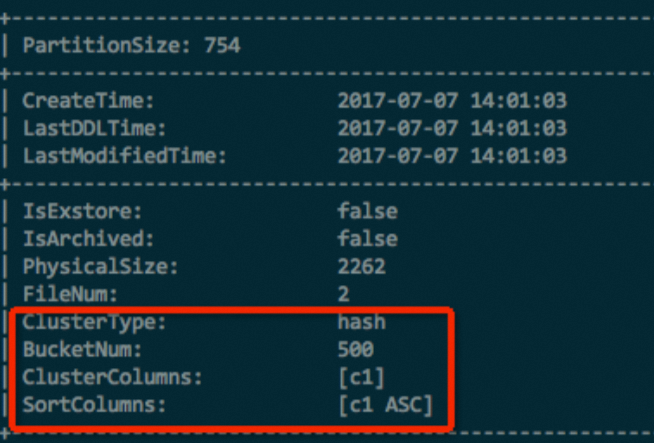
Storage optimization details
A simple experiment was performed using the lineitem table with 100 GB of data from a TPC-H dataset. The table contains data of various types such as INT, DOUBLE, and STRING. With the same data and the same compression method, the hash-clustered table saves about 10% of the storage space. In some extreme testing cases, a sorted table can save up to 50% of the storage space compared with an unsorted table.
What's next
Partition tables — manage table partitions in MaxCompute
Optimize query performance — additional techniques for improving query efficiency