This topic provides answers to frequently asked questions (FAQs) about Tunnel commands.
Does Tunnel Upload support wildcards or regular expressions?
The Tunnel Upload command does not support wildcards or regular expressions.
Tunnel Upload: Limits and compression
There is no limit on file size for a Tunnel Upload, but a single operation is limited to 2 hours. Estimate the maximum uploadable data volume based on your upload speed.
The maximum size for a single record is 200 MB.
Tunnel Upload uses compression by default. If your bandwidth allows, you can use the -cp parameter to disable compression.
Parallel uploads to a table or partition
Yes, you can upload data in parallel.
Concurrent uploads from multiple clients
Yes.
Requirement of pre-existing partitions
You can use the-acp parameter in the Tunnel Upload command to automatically create the destination partition. The default value of this parameter is false. For more information, see Tunnel commands.
Upload to non-partitioned tables
Yes. In the Tunnel Upload command syntax, the[/partition] parameter is optional. To upload data to a non-partitioned table, you do not need to specify partition information. You can use the following command:
tunnel upload <path> <table_name>;For a partitioned table, you must specify the partition information. Otherwise, an error occurs. For more information about the parameters and usage of Tunnel commands, see Tunnel commands.
Billing for compressed data
The billing is based on the data size after compression.
Does Tunnel Upload support rate limiting?
No, rate limiting is not supported.
Handling slow Tunnel uploads
If the data upload is too slow, consider using the -threads parameter to upload the data in slices, for example, by splitting the file into 10 slices. An example command is as follows.
tunnel upload C:\userlog.txt userlog1 -threads 10 -s false -fd "\u0000" -rd "\n";Public vs. classic network endpoint
In the odps_config.ini configuration file for the MaxCompute client, you must configure the Tunnel Endpoint in addition to the standard Endpoint. Refer to Endpoint for the required endpoint values. The Tunnel Endpoint is not required for the China (Shanghai) region.
Tunnel Upload error in DataStudio
-
Symptom
When you run the Tunnel Upload command in DataStudio to upload data to a partition, the following error is returned:
FAILED: error occurred while running tunnel command. -
Cause
DataStudio does not support the Tunnel Upload command.
-
Solution
Use the visual data import feature in DataWorks. For more information, see Upload data.
Handling data with carriage returns or spaces
If your data contains newline characters or spaces, you can set a custom delimiter, and then use -rd and -fd to specify this delimiter to upload the data. If you cannot change the delimiter in the data, you can upload the data as a single line and then use a UDF to parse it.
The following sample data contains carriage returns and can be uploaded successfully by using , as the column delimiter -rd and @ as the row delimiter -fd.
shopx,x_id,100@
shopy,y_id,200@
shopz,z_id,300@The following command is an example of the upload command.
tunnel upload d:\data.txt sale_detail/sale_date=201312,region=hangzhou -s false -fd "," -rd "@";The following code provides an example of the upload result.
+-----------+-------------+-------------+-----------+--------+
| shop_name | customer_id | total_price | sale_date | region |
+-----------+-------------+-------------+-----------+--------+
| shopx | x_id | 100.0 | 201312 | hangzhou |
| shopy | y_id | 200.0 | 201312 | hangzhou |
| shopz | z_id | 300.0 | 201312 | hangzhou |
+-----------+-------------+-------------+-----------+--------+Resolving memory overflow errors
The Tunnel Upload command is designed to handle large amounts of data. A memory overflow error usually indicates that the row and column delimiters are incorrectly set. This can cause the entire text file to be treated as a single record and cached in memory, which leads to the overflow.
In this case, you can first test with a small amount of data. After -td and -fd are successfully debugged, you can upload the entire dataset.
Scripting uploads from a folder
The Tunnel Upload command supports uploading a single file or a directory (first-level directory only). For more information, see Tunnel Usage Guide.
For example, you can run the following command to upload all data from the d:\data folder.
tunnel upload d:\data sale_detail/sale_date=201312,region=hangzhou -s false;Batch upload files to different partitions
You can use a Shell script. The following example shows a Shell script that is used with the MaxCompute client in a Windows environment. The same principle applies to Linux. The content of the Shell script is as follows:
#!/bin/sh
# First, create a partitioned table named user with dt as the partition key. In this example, the MaxCompute client is installed at C:/odpscmd_public/bin/odpscmd.bat. Adjust the path based on your environment.
C:/odpscmd_public/bin/odpscmd.bat -e "create table user(data string) partitioned by (dt int);"
dir=$(ls C:/userlog) # Define the variable dir to store the names of all files in the source folder.
pt=0 # The variable pt is used as the partition value and starts at 0. It increments by 1 after each file is uploaded. This way, each file is stored in a different partition.
for i in $dir # Loop through all files in the C:/userlog folder.
do
let pt=pt+1 # Increment the pt variable by 1 at the end of each loop.
echo $i # Display the file name.
echo $pt # Display the partition name.
# Use odpscmd to first add a partition, and then upload the file to that partition.
C:/odpscmd_public/bin/odpscmd.bat -e "alter table user add partition (dt=$pt);tunnel upload C:/userlog/$i user/dt=$pt -s false -fd "%" -rd "@";"
doneThe following figure shows the result of running the Shell script that uses two files, userlog1 and userlog2, as an example.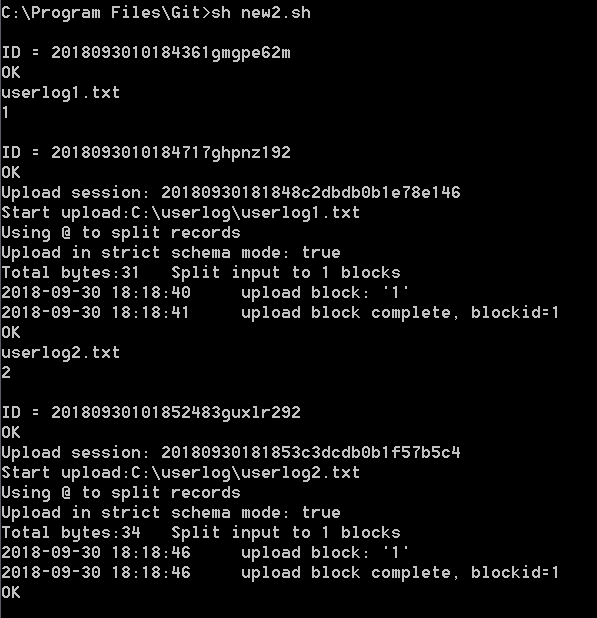
After the upload is complete, you can view the table data in the MaxCompute client.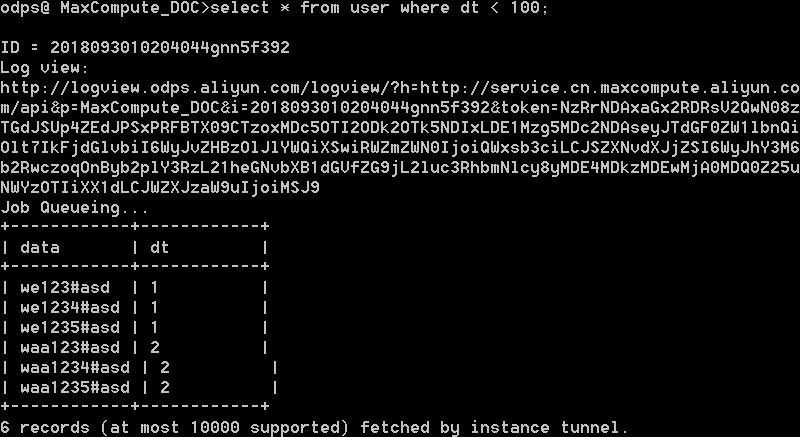
Skipping dirty data during uploads
You can use the -dbr true parameter in the Tunnel Upload command to ignore dirty data, such as rows with extra columns, missing columns, or mismatched column data types. The default value for the -dbr parameter is False, which means that dirty data is not ignored. When the value is set to True, all data that does not conform to the table definition is ignored. For more information, see Upload.
Resolving the status conflict error
-
Symptom
When you use the Tunnel Upload command, the following error is returned:
java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status. at com.aliyun.odps.tunnel.io.TunnelRecordWriter.close(TunnelRecordWriter.java:93) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:92) at com.xgoods.utils.aliyun.maxcompute.OdpsTunnel.upload(OdpsTunnel.java:45) at com.xeshop.task.SaleStatFeedTask.doWork(SaleStatFeedTask.java:119) at com.xgoods.main.AbstractTool.excute(AbstractTool.java:90) at com.xeshop.task.SaleStatFeedTask.main(SaleStatFeedTask.java:305)java.io.IOException: RequestId=XXXXXXXXXXXXXXXXXXXXXXXXX, ErrorCode=StatusConflict, ErrorMessage=You cannot complete the specified operation under the current upload or download status. -
Cause
The file is already being uploaded, and the operation cannot be duplicated.
-
Solution
Do not repeat the upload operation. Wait for the existing upload task to complete.
Resolving the request body error
-
Symptom
When you use the Tunnel Upload command, the following error is returned:
java.io.IOException: Error writing request body to server -
Cause
This exception occurs when data is being written to the server. The exception is usually caused by a network disconnection or timeout during the upload process. The following list describes the causes:
-
When your data source is not a local file and is being fetched from a source such as a database, the writing process may time out while it waits for the data to be fetched. If no data is uploaded for 600 seconds, the operation times out.
-
When you upload data over a public network by using a public endpoint, the upload may time out due to an unstable network connection.
-
-
Solution
-
During the upload process, fetch the data first, and then call the Tunnel SDK to upload the data.
-
A single block can upload from 64 MB to 100 GB of data. We recommend that you keep the number of records per block under 10,000 to avoid timeouts that are caused by retries. A session can have a maximum of 20,000 blocks. If your data is on an ECS instance, see Endpoints for endpoint information.
-
Resolving the no such partition error
-
Symptom
When you upload data by using Tunnel, the following error is returned:
ErrorCode=NoSuchPartition, ErrorMessage=The specified partition does not exist -
Cause
The destination partition for the data insertion does not exist.
-
Solution
You can first run the
show partitions table_name;command to check whether a partition exists, and then runalter table table_name add [if not exists] partition partition_specto create the corresponding partition.
Resolving column mismatch errors
This is usually because the row delimiter in the data source file is incorrect, which causes multiple records to be treated as a single record. You need to check for this issue and reset the -rd parameter.
Resolving ODPS-0110061 error in multi-threading
-
Symptom
When you upload data by using multiple threads, the following error is returned:
FAILED: ODPS-0110061: Failed to run ddltask - Modify DDL meta encounter exception : ODPS-0010000:System internal error - OTS transaction exception - Start of transaction failed. Reached maximum retry times because of OTSStorageTxnLockKeyFail(Inner exception: Transaction timeout because cannot acquire exclusive lock.) -
Cause
This error is caused by frequent concurrent write operations to the same table.
-
Solution
Reduce the number of concurrent threads, add a delay between requests, and implement a retry mechanism for failed operations.
Skipping CSV headers during upload
You can skip the first header row by adding the -h true parameter to the Tunnel Upload command.
Missing data after CSV import
This issue is typically caused by incorrect data encoding or the use of wrong delimiters, which leads to data being uploaded incorrectly. We recommend that you format the raw data correctly before you run the upload operation.
Uploading TXT files with a Shell script
You can run the following command in your system's command-line window to quickly upload data to a MaxCompute table by specifying the required parameters.
...\odpscmd\bin>odpscmd -e "tunnel upload "$FILE" project.table"For more information about how to run the command-line tool, see Connect by using the odpscmd client.
Resolving field mismatch for folder imports
Add the -dbr=false -s true parameters to the Tunnel Upload command to validate the data format.
A column mismatch error usually occurs because of a mismatch in the number of columns. For example, this can happen if the column delimiter is set incorrectly or if there are empty lines at the end of the file, which cause a column count mismatch when they are split by the delimiter.
Silent failure on second file upload
If the --scan parameter is used for an upload with the MaxCompute client, an issue occurs with parameter passing in resumable mode. Remove the --scan=true parameter and retry the operation.
Block skipping on retry after upload failure
Each block corresponds to an HTTP request, and the uploads of multiple blocks can be concurrent and atomic. A synchronous request for a block either succeeds or fails without affecting other blocks.
There is a limit on the number of retries. If the retry limit is exceeded, the upload proceeds to the next Block. After the upload is complete, you can use the select count(*) from table; statement to check for data loss.
Improving slow upload speeds
The Tunnel Upload command itself does not impose a speed limit. Upload speed bottlenecks are typically related to network bandwidth, client performance, and server performance. To improve performance, you can partition your data, use multiple tables, or upload data from multiple ECS instances.
Preventing session timeouts for large uploads
We recommend splitting the source data into multiple smaller tasks.
Slow uploads due to too many sessions
Set the block size to an appropriate value. The maximum block ID is 20,000. Set the session duration based on your business requirements. Data becomes visible only after the session is committed. Avoid creating sessions too frequently. You can create a maximum of one session every 5 minutes. Use a large block size, preferably over 64 MB.
Extra \r character in last column
The newline character is \r\n in Windows and \n in macOS and Linux. The Tunnel command uses the system newline character as the default column delimiter. As a result, when you upload a file that was edited on Windows from a macOS or Linux system, the \r character is imported into the table as data.
Handling commas in data with default delimiter
If a data description field contains commas, you can change the data delimiter to a different character and use the -fd parameter to specify the new delimiter during the upload.
Handling space delimiters or regex filtering
The Tunnel Upload command does not support regular expressions. If your data uses spaces as delimiters or requires regular expression filtering, you can use MaxCompute UDFs.
Assume that your raw data uses spaces as column delimiters and carriage returns as row delimiters, as shown in the following example. You must extract data that is enclosed in quotation marks and filter out specific characters such as "-". Such complex requirements can be handled by using regular expressions.
10.21.17.2 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73477.html" 200 0 81615 81615 "-" "iphone" - HIT - - 0_0_0 001 - - - -
10.17.5.23 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73478.html" 206 0 49369 49369 "-" "huawei" - HIT - - 0_0_0 002 - - - -
10.24.7.16 [24/Jul/2018:00:00:00 +0800] - "GET https://example.com/73479.html" 206 0 83821 83821 "-" "vivo" - HIT - - 0_0_0 003 - - - -Perform the following steps:
-
Upload the data as a single column. First, create a single-column table in your MaxCompute project to receive the data. The following command is an example.
create table userlog1(data string); -
Use a non-existent column delimiter, such as
\u0000, to upload data without splitting the data into columns. The following is an example command.tunnel upload C:\userlog.txt userlog1 -s false -fd "\u0000" -rd "\n"; -
After you upload the raw data, write and register a Python UDF in MaxCompute Studio. You can also use a Java UDF. For more information about how to write and register UDFs, see Develop a Java UDFs or Develop a Python UDFs.
The following code provides an example of the UDF. Assume that the registered function is named ParseAccessLog.
from odps.udf import annotate from odps.udf import BaseUDTF import re # Import the regular expression module. regex = '([(\d\.)]+) \[(.*?)\] - "(.*?)" (\d+) (\d+) (\d+) (\d+) "-" "(.*?)" - (.*?) - - (.*?) (.*?) - - - -' # The regular expression to be used. # line -> ip,date,request,code,c1,c2,c3,ua,q1,q2,q3 @annotate('string -> string,string,string,string,string,string,string,string,string,string,string') # Make sure that the number of strings matches the actual number of data columns. This example has 11 columns. class ParseAccessLog(BaseUDTF): def process(self, line): try: t = re.match(regex, line).groups() self.forward(t[0], t[1], t[2], t[3], t[4], t[5], t[6], t[7], t[8], t[9], t[10]) except: pass -
After you register the function, you can use the UDF to process the raw data in the userlog1 table. Make sure that you use the correct column name, which is data in this example. You can use standard SQL syntax to create a table named userlog2 to store the processed data. The following command is an example.
create table userlog2 as select ParseAccessLog(data) as (ip,date,request,code,c1,c2,c3,ua,q1,q2,q3) from userlog1;After the processing is complete, you can query the userlog2 table. The data is now correctly split into columns.
select * from userlog2; -- The following result is returned. +----+------+---------+------+----+----+----+----+----+----+----+ | ip | date | request | code | c1 | c2 | c3 | ua | q1 | q2 | q3 | +----+------+---------+------+----+----+----+----+----+----+----+ | 10.21.17.2 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73477.html | 200 | 0 | 81615 | 81615 | iphone | HIT | 0_0_0 | 001 | | 10.17.5.23 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73478.html | 206 | 0 | 4936 | 4936 | huawei | HIT | 0_0_0 | 002 | | 10.24.7.16 | 24/Jul/2018:00:00:00 +0800 | GET https://example.com/73479.html | 206 | 0 | 83821 | 83821 | vivo | HIT | 0_0_0 | 003 | +----+------+---------+------+----+----+----+----+----+----+----+
Handling dirty data after upload
We recommend that you write data to a non-partitioned table or a single partition in a single operation. Do not write to the same partition multiple times because this may generate dirty data. You can run the tunnel show bad <sessionid>; command in the MaxCompute client to check for dirty data. If dirty data is generated, you can delete it by using the following methods:
-
Run the
drop table ...;command to delete the entire table or thealter table ... drop partition;command to delete the target partition, and then re-upload the data. -
If the dirty data can be filtered by using a WHERE clause, you can use an INSERT statement with the WHERE clause to import the correct data into a new table or perform an in-place update. The source and destination partition/table names are the same.
Synchronizing geometry data
MaxCompute does not support the geometry data type. You must convert geometry data to the STRING type before you synchronize the data to MaxCompute.
The geometry type is a special data type that is not part of the standard SQL data types. The generic JDBC framework does not support the geometry type. This requires special handling for data import and export.
Supported export formats for Tunnel Download
Data files that are exported by using the Tunnel Download command can be in the TXT or CSV format.
Charges for in-region Tunnel downloads
To download data within the same region without incurring charges for public network traffic, you must configure the Tunnel endpoint for the classic network or a VPC. Otherwise, data might be routed through a public network endpoint in another region, which results in charges.
Resolving recurring download timeouts
This error usually indicates that the Tunnel endpoint is incorrect. Check whether the Tunnel endpoint is correctly configured. A simple way to verify the endpoint is to test the network connectivity by using a tool such as Telnet.
Resolving the no privilege error
-
Symptom
When you use the Tunnel Download command, the following error is returned:
You have NO privilege ‘odps:Select‘ on {acs:odps:*:projects/XXX/tables/XXX}. project ‘XXX‘ is protected. -
Cause
The data protection feature is enabled for the project.
-
Solution
If you want to export data from one project to another, the operation must be performed by the project owner.
Downloading a subset of data
Tunnel does not support data computing or filtering. To download a specific subset of data, you can use one of the following methods:
-
Run a SQL task to save the data that you want to download to a temporary table. After the download is complete, delete the temporary table.
-
If the amount of data that you want is small, you can use a SQL command to query the data directly without the need to download it.
Tunnel history retention period
The retention is not time-based. By default, the last 500 entries are saved.
Tunnel upload workflow
The data upload workflow with Tunnel is as follows:
-
Prepare the source data, such as a source file or data table.
-
Design the table schema and partition definitions, perform data type conversions, and then create the table in MaxCompute.
-
Add partitions to the MaxCompute table. You can skip this step if the table is not partitioned.
-
Upload the data to the specified partition or table.
Support for Chinese characters in paths
Yes, Chinese characters are supported.
Notes on using delimiters
When you use delimiters with Tunnel, take note of the following points:
-
The row delimiter is
rd, and the column delimiter isfd. -
The column delimiter
fdcannot contain the row delimiterrd. -
The default delimiter for a Tunnel is
\r\nfor Windows and\nfor Linux. -
When an upload starts, a message is displayed on the screen that indicates the row delimiter being used for the current upload for you to check and confirm. This feature is available in v0.21.0 and later.
Can Tunnel file paths contain spaces?
Yes. However, the parameter that contains the path must be enclosed in double quotation marks ("").
Support for .dbf files
Tunnel supports only text files and does not support binary files.
Normal upload and download speeds
Tunnel upload and download speeds are heavily influenced by network conditions. Under normal network conditions, the speed ranges from 1 MB/s to 20 MB/s.
Obtaining the Tunnel domain name
The Tunnel domain name is the public Tunnel endpoint. Different regions and networks correspond to different Tunnel domain names. For more information, see Endpoints to obtain the correct public Tunnel endpoint.
Troubleshooting upload and download failures
Obtain the Tunnel domain name from the odps_config.ini file in the ..\odpscmd_public\conf directory of the MaxCompute client installation and run the curl -i <domain name> command (for example, curl -i http://dt.odps.aliyun.com) in a command-line window to test the network connectivity. If the connection fails, check your device's network or use the correct Tunnel domain name.
Resolving Java heap space errors
-
Symptom
When using a Tunnel command to upload or download data, you may receive the following error:
Java heap space FAILED: error occurred while running tunnel command -
Cause
-
Cause 1: When you upload data, a single row of data is too large.
-
Cause 2: The amount of data to be downloaded is too large for the available memory of the client program.
-
-
Solution
-
Solution for Cause 1
-
First, confirm whether the delimiter is incorrect, which could cause all data to be read as a single, large row.
-
If the delimiter is correct and a single line of data in the file is very large, the client program has insufficient memory. You need to adjust the startup parameters for the client process. To do this, edit the odpscmd script in the
bindirectory of the client installation and increase the values of-Xms64m -Xmx512min thejava -Xms64m -Xmx512m -classpath "${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@"command.
-
-
Solution for Reason 2: Edit the odpscmd script in the
bindirectory of the client installation path. Increase the values of-Xms64m -Xmx512min the following command:java -Xms64m -Xmx512m -classpath "${clt_dir}/lib/*:${clt_dir}/conf/"com.aliyun.openservices.odps.console.ODPSConsole "$@".
-
Session lifecycle and expiration
Each session has a lifecycle of 24 hours on the server and can be used at any time within that period. After a session expires, it becomes invalid and you cannot perform any operations with it. You must create a new session and rewrite the data.
Can a session be shared?
A session can be shared across processes and threads. However, you must make sure that the same block ID is not used more than once.
What is the Tunnel routing feature?
If you do not configure a Tunnel endpoint, Tunnel automatically routes traffic to the Tunnel endpoint that corresponds to the network where the MaxCompute service is located. If you configure a Tunnel endpoint, your configuration takes precedence and automatic routing is disabled.
Does Tunnel support concurrency?
Yes. The following command is an example:
tunnel upload E:/1.txt tmp_table_0713 --threads 5;