Centauri is the predecessor of Proxima CE. This topic presents benchmark data comparing Centauri against Proxima CE (hash sharding and cluster sharding) across three test scenarios of increasing data scale.
Method availability by data scale
At large data scales, not all methods complete successfully. Review this summary before reading the scenario details.
| Data scale | Centauri | Hash sharding of Proxima CE | Cluster sharding of Proxima CE |
|---|---|---|---|
| 100 million records | Completed | Completed | Not tested |
| 1 billion records | Completed | Completed | Completed |
| 1.6 billion records | Failed (out of memory in seek phase) | Failed (output exceeds temporary table limit) | Completed |
At 1.6 billion records, only cluster sharding of Proxima CE completes all phases.
How to read these results
Each test scenario measures up to three pipeline phases. Not all phases apply to every method.
| Phase | Description | Applies to |
|---|---|---|
| K-means | Calculates the cluster centroid table from the doc table | Proxima CE cluster sharding only |
| Autotuning | Calculates optimal parameters for the indexing algorithm | Centauri only |
| Build | Builds the vector index | All methods |
| Seek | Runs the similarity search | All methods |
Scenario 1: 100 million BINARY records, 512 dimensions
Test configuration
| Parameter | Value |
|---|---|
| Doc table records | 100,000,000 |
| Query table records | 100,000,000 |
| Data type | BINARY |
| Dimensions | 512 |
| Search configuration | 50 rows x 4 columns |
| Records per column (index building) | 25,000,000 |
| Search method | graph |
| Distance measure | Hamming |
Conclusion
Hash sharding of Proxima CE is approximately 20% faster than Centauri overall. Centauri achieves a recall rate of 98.061% at top-200.
| Method | Autotuning (s) | Build phase (s) | Seek phase (s) | Total time (min) |
|---|---|---|---|---|
| Centauri | 1,524 | 12,653 | 5,914 | 336 |
| Hash sharding of Proxima CE | — | 9,647 | 6,431 | 268 |
K-means applies to cluster sharding of Proxima CE only. Autotuning applies to Centauri only.
Build phase results
Centauri 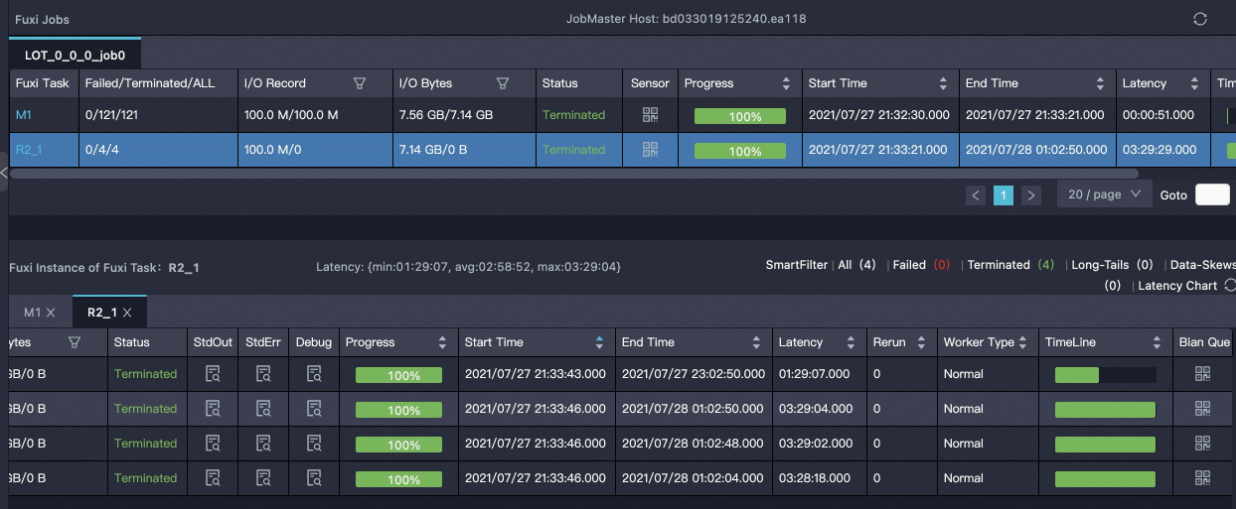
Hash sharding of Proxima CE 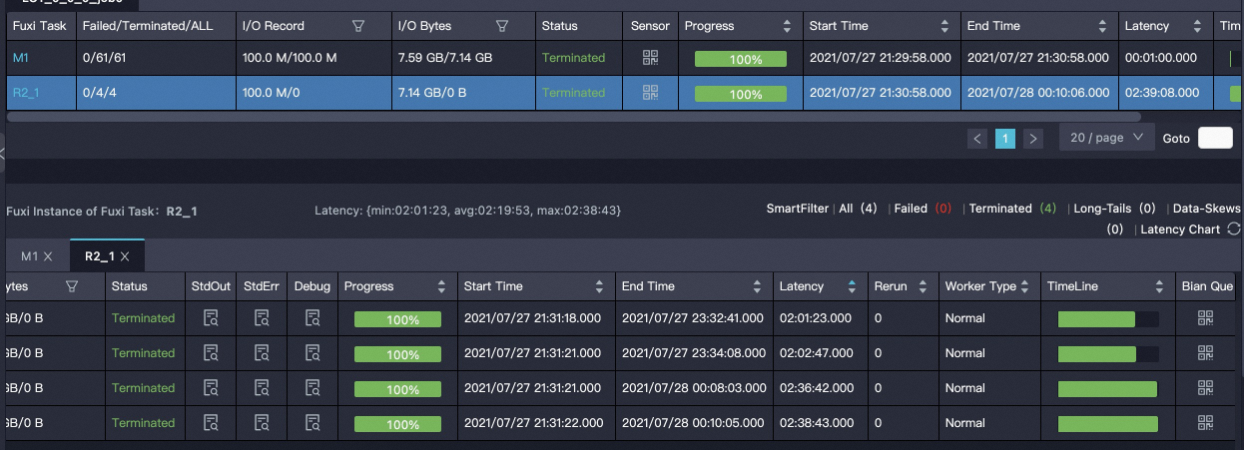
Result analysis: With Centauri, one node builds the index at an exceptionally high speed while the remaining three nodes take approximately equal time. With hash sharding of Proxima CE, two nodes build at high speed and the other two build at a relatively lower speed.
Seek phase results
Centauri 
Hash sharding of Proxima CE 
Result analysis:
Index seeking time per node is comparable between Centauri and hash sharding of Proxima CE.
Result merging takes approximately 12 minutes longer with hash sharding of Proxima CE:
Hash sharding of Proxima CE: fastest node at 8 minutes, slowest at 20 minutes
Centauri: fastest node at 4 minutes, slowest at 9 minutes
Running details
Centauri
Vector search Data type:BINARY , Vector dimension:512 , Search method:graph , Measure:hamming , Building mode:build:seek
Information about the doc table Table name: doc_table_pailitao_binary , Partition:20210712 , Number of data records in the doc table:100000000 , Vector delimiter:~
Information about the query table Table name: doc_table_pailitao_binary , Partition:20210712 , Number of data records in the query table: 100000000 , Vector delimiter:~
Information about the output table Table name: output_table_pailitao_binary_centauri , Partition:20210712
Row and column information Number of rows: 50 , Number of columns:4 , Number of data records in the doc table of each column for index building:25000000
Whether to clear volume indexes:false
Time required for each worker node (seconds):
worker:TmpDataTableJoinWorker , times:0
worker:TmpTableWorker , times:16
worker:CleanUpWorker , times:4
worker:AutotuningFastWorker , times:46
worker:RowColWorker , times:53
worker:SeekJobWorker , times:5914
worker:BuildJobWorker , times:12653
worker:AutotuningNormalWorker , times:1478
Total time required (minutes):336
Top recall rate User setting train:
top200:0.95
Top recall rate normal train:
top200:98.061%
Autotuning Fast Build Params:
proxima.general.builder.memory_quota=0
proxima.graph.common.max_doc_cnt=27500000
proxima.general.builder.thread_count=15
proxima.hnsw.builder.efconstruction=400
proxima.graph.common.neighbor_cnt=100
Autotuning Normal Search Params:
proxima.hnsw.searcher.ef=400
Sample commands:
jar -resources centauri-1.1.5.jar,libcentauri-1.1.5.so -classpath /data/jiliang.ljl/centauri_1.1.5/centauri-1.1.5.jar
com.alibaba.proxima.CentauriRunner
-proxima_version 1.1.5
-doc_table doc_table_pailitao_binary -doc_table_partition 20210712
-query_table doc_table_pailitao_binary -query_table_partition 20210712
-output_table output_table_pailitao_binary_centauri -output_table_partition 20210712
-data_type binary -dimension 512 -app_id 201220 -pk_type int64 -clean_build_volume false -distance_method hamming -binary_to_int true -row_num 50 -column_num 4;Hash sharding of Proxima CE
Vector search Data type:1 , Vector dimension:512 , Search method:hnsw , Measure:Hamming , Building mode:build:build:seek
Information about the doc table Table name: doc_table_pailitao_binary2 , Partition:20210712 , Number of data records in the doc table:100000000 , Vector delimiter:~
Information about the query table Table name: doc_table_pailitao_binary2 , Partition:20210712 , Number of data records in the query table:100000000 , Vector delimiter:~
Information about the output table Table name: output_table_pailitao_binary_ce , Partition:20210712
Row and column information Number of rows: 50 , Number of columns:4 , Number of data records in the doc table of each column for index building:25000000
Whether to clear volume indexes:false
Time required for each worker node (seconds):
SegmentationWorker: 2
TmpTableWorker: 1
KmeansGraphWorker: 0
BuildJobWorker: 9647
SeekJobWorker: 6431
TmpResultJoinWorker: 0
RecallWorker: 0
CleanUpWorker: 3
Total time required (minutes):268
Sample commands:
jar -resources proxima_ce_g.jar -classpath /data/jiliang.ljl/project/proxima2-java/proxima-ce/target/binary/proxima-ce-0.1-SNAPSHOT-jar-with-dependencies.jar com.alibaba.proxima2.ce.ProximaCERunner
-doc_table doc_table_pailitao_binary2 -doc_table_partition 20210712
-query_table doc_table_pailitao_binary2 -query_table_partition 20210712
-output_table output_table_pailitao_binary_ce -output_table_partition 20210712
-data_type binary -dimension 512 -app_id 201220 -pk_type int64 -clean_build_volume false -distance_method Hamming -binary_to_int true -row_num 50 -column_num 4;Scenario 2: 1 billion FLOAT records, 128 dimensions
Test configuration
| Parameter | Value |
|---|---|
| Doc table records | 1,000,000,000 |
| Query table records | 1,000,000,000 |
| Data type | FLOAT |
| Dimensions | 128 |
| Search configuration | 50 rows x 60 columns |
Conclusion
Compared to Centauri:
Hash sharding of Proxima CE is approximately 30% faster overall.
Cluster sharding of Proxima CE delivers approximately 2x overall improvement, with the seek phase approximately 7.5x faster.
INT8 quantization improves the data performance by approximately 10%.
| Method | Autotuning or K-means (s) | Build phase (s) | Seek phase (s) |
|---|---|---|---|
| Centauri | 1,220 | 9,822 | 37,245 |
| Hash sharding of Proxima CE | N/A | 9,841 | 23,462 |
| Hash sharding + INT8 quantization of Proxima CE | N/A | 7,600 | 21,624 |
| Cluster sharding of Proxima CE | 1,247 | 14,404 | 5,028 |
Build phase details
| Method | Mapper | Build reducer | Total time required (seconds) |
|---|---|---|---|
Centauri | - | - | - |
Hash sharding of Proxima CE | 00:01:23.116 Latency:{min:00:00:03, avg:00:00:23, max:00:01:00} | 02:41:43.563 Latency:{min:00:02:40, avg:01:32:33, max:02:41:33} | 9,841 |
Hash sharding and INT8 quantization of Proxima CE | 00:01:36.166 Latency:{min:00:00:09, avg:00:00:25, max:00:01:09} | 02:04:11.440 Latency:{min:00:06:56, avg:01:06:06, max:02:03:53} | 7,600 |
Cluster sharding of Proxima CE | 00:15:33.022 Latency:{min:00:00:03, avg:00:03:24, max:00:15:21} | 03:43:37.529 Latency:{min:00:03:57, avg:01:33:32, max:03:43:35} | 14,404 |
Seek phase details
| Method | Mapper | TopN reducer | Merge reducer | Total time required (seconds) | Remarks |
|---|---|---|---|---|---|
Centauri | 00:15:45.000 From 34 seconds to 11 minutes | 08:33:50.000 From 98 minutes to 489 minutes | 01:30:20.000 From 30 minutes to 70 minutes | 37,245 |
|
Hash sharding of Proxima CE | 00:06:29.791 Latency:{min:00:00:02, avg:00:01:39, max:00:05:56} | 04:50:42.422 Latency:{min:00:01:48, avg:01:54:33, max:03:47:54} | 04:50:42.422 Latency:{min:00:00:35, avg:00:33:39, max:01:32:16} | 23,462 |
|
Hash sharding and INT8 quantization of Proxima CE | 00:06:25.718 Latency:{min:00:00:17, avg:00:01:27, max:00:06:02} | 03:58:00.566 Latency:{min:00:00:25, avg:01:06:41, max:02:40:07} | 01:54:35.620 Latency:{min:00:01:56, avg:00:20:54, max:01:39:55} | 21,624 | N/A. |
Cluster sharding of Proxima CE | 00:23:51.623 Latency:{min:00:00:04, avg:00:03:01, max:00:08:34} | 01:00:38.382 Latency:{min:00:05:15, avg:00:18:00, max:01:00:10} | 00:12:39.341 Latency:{min:00:00:31, avg:00:07:08, max:00:12:33} | 5,028 | N/A. |
Scenario 3: 1.6 billion FLOAT records, cluster sharding
Test configuration
| Parameter | Value |
|---|---|
| Doc table records | 1,600,000,000 |
| Query table records | 1,600,000,000 |
| Data type | FLOAT |
| Dimensions | 128 |
| Row and column configuration | Calculated automatically |
Conclusion
At this data scale, only cluster sharding of Proxima CE completes all phases. Centauri fails with an out of memory (OOM) error in the seek phase, and hash sharding of Proxima CE fails because the output exceeds the temporary table size limit.
| Method | Autotuning or K-means (s) | Build phase (s) | Seek phase (s) |
|---|---|---|---|
| Centauri | 1,127 | 19,962 | Failed — out of memory (OOM) error (2 attempts) |
| Hash sharding of Proxima CE | N/A | 14,637 | Failed — output data exceeds the temporary table limit (1 attempt) |
| Cluster sharding of Proxima CE | 5,478 | 17,911 | 6,801 |