Aggregator is a common feature in MaxCompute Graph for aggregating and processing global information across all workers in a distributed job. Use it to check whether a global condition is satisfied (such as convergence in machine learning), or to maintain statistics that span multiple workers.
How it works
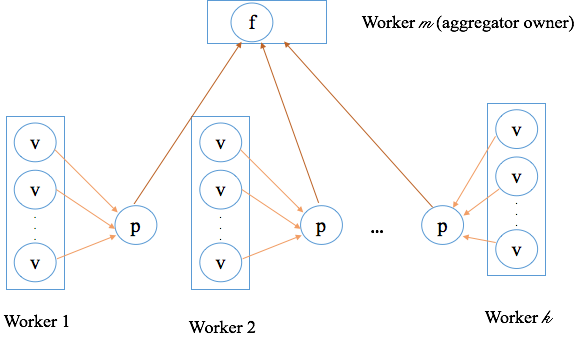
Aggregator logic runs in two places: distributed across all workers for partial aggregation, and on a single designated worker (the Aggregator owner) for global aggregation.
Each superstep follows this sequence:
-
Each worker calls
createStartupValueat startup to create anAggregatorValue. -
At the start of each iteration, each worker calls
createInitialValueto initialize theAggregatorValuefor that iteration. -
During the iteration, each vertex calls
context.aggregate(), which triggersaggregate()to build a partial result on the worker. -
Each worker sends its partial result to the Aggregator owner worker.
-
The Aggregator owner worker calls
mergerepeatedly to combine all partial results into a global aggregation result. -
The Aggregator owner worker calls
terminateto finalize the global result and decide whether to end the iteration.
The global result is then distributed to all workers at the start of the next superstep.
API operations
Aggregator provides five API operations. Three run on all workers and handle partial aggregation; two run only on the Aggregator owner worker and handle global aggregation.
| API | Runs on | Called by | Purpose |
|---|---|---|---|
createStartupValue(context) |
All workers | Framework, once before each superstep | Initialize AggregatorValue |
createInitialValue(context) |
All workers | Framework, once when each superstep starts | Initialize AggregatorValue for the current iteration |
aggregate(value, item) |
All workers | Explicit call via ComputeContext#aggregate(item) |
Partial aggregation |
merge(value, partial) |
Aggregator owner only | Framework | Merge partial results into the global result |
terminate(context, value) |
Aggregator owner only | Framework, after merge() |
Finalize the global result; return true to end iteration |
createStartupValue(context)
Called once on all workers before each superstep starts. Use it to initialize AggregatorValue. In superstep 0, call WorkerContext.getLastAggregatedValue() or ComputeContext.getLastAggregatedValue() to get the initialized object.
createInitialValue(context)
Called once on all workers at the start of each superstep. Use it to initialize AggregatorValue for the current iteration. Typically, call WorkerContext.getLastAggregatedValue() to get the previous iteration's result, then initialize from it.
aggregate(value, item)
Called on all workers. Unlike createStartupValue and createInitialValue, this method is not called automatically — it is triggered when your vertex code calls ComputeContext#aggregate(item).
-
value: the worker's current aggregation result for this superstep, initialized bycreateInitialValue -
item: the value passed in byComputeContext#aggregate(item)
Update value using item to build the partial result. After all aggregate calls complete, the framework sends value to the Aggregator owner worker.
merge(value, partial)
Called on the Aggregator owner worker to combine partial results from all workers.
-
value: the running global aggregation result -
partial: a partial result received from a worker
Use partial to update value. For example, if workers w0, w1, and w2 produce partial results p0, p1, and p2, and they arrive in the order p1, p0, p2:
-
merge(p1, p0)— p1 is updated to include p0 -
merge(p1, p2)— p1 is updated to include p2; p1 is now the global aggregation result
If only one worker exists, merge() is not called.
terminate(context, value)
Called on the Aggregator owner worker after all merge() calls complete. value contains the global aggregation result.
Modify value if needed, then return:
-
true— end the iteration for the entire job -
false— continue to the next iteration
After terminate() returns, the framework distributes the global aggregation object to all workers for the next superstep. Returning true when convergence is complete stops jobs immediately, which is the typical pattern in machine learning scenarios.
K-means clustering example
The following example shows how to implement Aggregator for k-means clustering. The main logic is concentrated in the Aggregator class, which coordinates partial aggregation across workers and drives convergence.
For the complete source code, download Kmeans.gz. The code below is excerpted for reference.
GraphLoader
KmeansReader loads each row of the input table as a vertex. recordNum becomes the vertex ID, and the row data is stored as a DenseVector in the vertex value. (DenseVector is from matrix-toolkits-java.)
public static class KmeansValue implements Writable {
DenseVector sample;
public KmeansValue() {
}
public KmeansValue(DenseVector v) {
this.sample = v;
}
@Override
public void write(DataOutput out) throws IOException {
wirteForDenseVector(out, sample);
}
@Override
public void readFields(DataInput in) throws IOException {
sample = readFieldsForDenseVector(in);
}
}public static class KmeansReader extends
GraphLoader<LongWritable, KmeansValue, NullWritable, NullWritable> {
@Override
public void load(
LongWritable recordNum,
WritableRecord record,
MutationContext<LongWritable, KmeansValue, NullWritable, NullWritable> context)
throws IOException {
KmeansVertex v = new KmeansVertex();
v.setId(recordNum);
int n = record.size();
DenseVector dv = new DenseVector(n);
for (int i = 0; i < n; i++) {
dv.set(i, ((DoubleWritable)record.get(i)).get());
}
v.setValue(new KmeansValue(dv));
context.addVertexRequest(v);
}
}Vertex
Each vertex contributes its sample to the partial aggregation. The entire compute logic is a single context.aggregate() call:
public static class KmeansVertex extends
Vertex<LongWritable, KmeansValue, NullWritable, NullWritable> {
@Override
public void compute(
ComputeContext<LongWritable, KmeansValue, NullWritable, NullWritable> context,
Iterable<NullWritable> messages) throws IOException {
context.aggregate(getValue()); // submit this vertex's sample for partial aggregation
}
}Aggregator
KmeansAggrValue holds the data that is aggregated across workers and distributed back each superstep:
public static class KmeansAggrValue implements Writable {
DenseMatrix centroids; // K x m matrix of current cluster centers
DenseMatrix sums; // running sums per cluster dimension, for recomputing centers
DenseVector counts; // number of samples assigned to each cluster center
@Override
public void write(DataOutput out) throws IOException {
wirteForDenseDenseMatrix(out, centroids);
wirteForDenseDenseMatrix(out, sums);
wirteForDenseVector(out, counts);
}
@Override
public void readFields(DataInput in) throws IOException {
centroids = readFieldsForDenseMatrix(in);
sums = readFieldsForDenseMatrix(in);
counts = readFieldsForDenseVector(in);
}
}sums(i,j) stores the sum of dimension j across all samples closest to center i. Used with counts, it recalculates the new center position each superstep.
createStartupValue — reads initial centers from the centers cache file and initializes sums and counts to zero:
public static class KmeansAggregator extends Aggregator<KmeansAggrValue> {
public KmeansAggrValue createStartupValue(WorkerContext context) throws IOException {
KmeansAggrValue av = new KmeansAggrValue();
byte[] centers = context.readCacheFile("centers"); // load initial cluster centers
String lines[] = new String(centers).split("\n");
int rows = lines.length;
int cols = lines[0].split(",").length; // assumption rows >= 1
av.centroids = new DenseMatrix(rows, cols);
av.sums = new DenseMatrix(rows, cols);
av.sums.zero(); // initialize to zero before first superstep
av.counts = new DenseVector(rows);
av.counts.zero(); // initialize to zero before first superstep
for (int i = 0; i < lines.length; i++) {
String[] ss = lines[i].split(",");
for (int j = 0; j < ss.length; j++) {
av.centroids.set(i, j, Double.valueOf(ss[j]));
}
}
return av;
}
}createInitialValue — resets sums and counts to zero while keeping the previous iteration's centroids:
@Override
public KmeansAggrValue createInitialValue(WorkerContext context)
throws IOException {
KmeansAggrValue av = (KmeansAggrValue)context.getLastAggregatedValue(0);
// reset accumulators; retain centroids from the previous iteration
av.sums.zero();
av.counts.zero();
return av;
}aggregate — finds the nearest centroid for each sample and accumulates sums and counts (partial aggregation on each worker):
@Override
public void aggregate(KmeansAggrValue value, Object item)
throws IOException {
DenseVector sample = ((KmeansValue)item).sample;
int min = findNearestCentroid(value.centroids, sample); // find closest cluster center
for (int i = 0; i < sample.size(); i ++) {
value.sums.add(min, i, sample.get(i)); // accumulate sample dimensions
}
value.counts.add(min, 1.0d); // increment sample count for this cluster
}merge — combines partial results from all workers by summing sums and counts (global aggregation on the Aggregator owner worker):
@Override
public void merge(KmeansAggrValue value, KmeansAggrValue partial)
throws IOException {
value.sums.add(partial.sums); // accumulate sums from this worker
value.counts.add(partial.counts); // accumulate counts from this worker
}terminate — computes new cluster centers, checks convergence using Euclidean distance with a threshold of 0.05, and decides whether to end the iteration:
@Override
public boolean terminate(WorkerContext context, KmeansAggrValue value)
throws IOException {
// Calculate new centers from the aggregated sums and counts
DenseMatrix newCentriods = calculateNewCentroids(value.sums, value.counts, value.centroids);
// print old centroids and new centroids for debugging
System.out.println("\nsuperstep: " + context.getSuperstep() +
"\nold centriod:\n" + value.centroids + " new centriod:\n" + newCentriods);
boolean converged = isConverged(newCentriods, value.centroids, 0.05d); // Euclidean distance threshold
System.out.println("superstep: " + context.getSuperstep() + "/"
+ (context.getMaxIteration() - 1) + " converged: " + converged);
if (converged || context.getSuperstep() == context.getMaxIteration() - 1) {
// converged or reached max iterations — write final centers and stop
for (int i = 0; i < newCentriods.numRows(); i++) {
Writable[] centriod = new Writable[newCentriods.numColumns()];
for (int j = 0; j < newCentriods.numColumns(); j++) {
centriod[j] = new DoubleWritable(newCentriods.get(i, j));
}
context.write(centriod);
}
return true; // end iteration
}
value.centroids.set(newCentriods); // update centers for next iteration
return false; // continue iteration
}main method
The main method constructs GraphJob, configures all component classes, and submits the job. The default maximum number of iterations is 30, configurable via the third argument.
public static void main(String[] args) throws IOException {
if (args.length < 2)
printUsage();
GraphJob job = new GraphJob();
job.setGraphLoaderClass(KmeansReader.class);
job.setRuntimePartitioning(false); // each worker loads and retains its own data partition
job.setVertexClass(KmeansVertex.class);
job.setAggregatorClass(KmeansAggregator.class); // register the Aggregator implementation
job.addInput(TableInfo.builder().tableName(args[0]).build());
job.addOutput(TableInfo.builder().tableName(args[1]).build());
// default max iteration is 30
job.setMaxIteration(30);
if (args.length >= 3)
job.setMaxIteration(Integer.parseInt(args[2]));
long start = System.currentTimeMillis();
job.run();
System.out.println("Job Finished in "
+ (System.currentTimeMillis() - start) / 1000.0 + " seconds");
}Whenjob.setRuntimePartitioningis set tofalse, data loaded by each worker is not partitioned by the partitioner. Each worker loads and maintains its own data.