A distributed file system stores data by block. A file whose size is less than the block size 64 MB is called a small file. In most cases, small files are generated in a distributed file system. For example, small files are generated to save the computing results of SQL statements, the computing results of a distributed engine, and data that is collected by using Tunnel commands. You can merge small files to optimize system performance. This topic describes how to merge small files in MaxCompute.
Background information
If excessive small files exist, the following issues may occur:
The overall processing performance is affected because the processing efficiency of MaxCompute on a single large file is higher than the processing efficiency on multiple small files.
Excessive small files increase the workload on the Apsara Distributed File System. This affects the storage usage.
Therefore, small files need to be merged during data computation to help you resolve the preceding issues. The processing capabilities of MaxCompute on small files are improved in the following aspects:
After a job is complete, MaxCompute automatically allocates a Fuxi task to merge small files when specific conditions are met. In this case, MergeTask appears when MaxCompute merges small files.
By default, a Fuxi instance can process a maximum of 100 small files. You can also configure the
odps.sql.mapper.merge.limit.sizeparameter to manage the total size of the files that can be read.MaxCompute periodically scans the metadatabase. During the scanning process, MaxCompute merges small files in tables or partitions that contain a large number of small files. This process is visible to users.
If the metadata indicates that a large number of small files are not merged, you must manually merge these files. For example, if data is continuously written to a table that contains a large number of small files and the small files cannot be automatically merged, you must stop the writing job and manually merge the small files.
Precautions
Computing resources are consumed to merge small files. If you use a pay-as-you-go instance, fees are incurred. The billing rules are consistent with the pay-as-you-go billing rules for SQL statements. For more information, see Computing pricing (pay-as-you-go).
The command used to merge small files does not support transactional tables. For more information about how to merge small files into a transactional table, see COMPACTION.
View the number of files in a table
Syntax
You can run the following command to view the number of files in a table:
desc extended <table_name> [partition (<pt_spec>)];Parameters
table_name: required. The name of the table whose files you want to view.
pt_spec: optional. The partition in the partitioned table that you want to view. The value of this parameter is in the
(partition_col1 = partition_col_value1, partition_col2 = partition_col_value2, ...)format.
Sample result
The following figure shows the sample result. The sample partition of the
odl_bpm_wfc_task_logtable contains 3,607 files. The partition size is 274 MB (287,869,658 bytes). The average file size is approximately 0.07 MB. In this case, small files need to be merged.
Solutions
If the metadata indicates that the partition contains more than 100 files and the average file size is less than 64 MB, you can use one of the following methods to merge the small files:
Merge small files by using a command
Run the following command to merge small files:
ALTER TABLE <table_name> [partition (<pt_spec>)] MERGE SMALLFILES;After the small files in the
odl_bpm_wfc_task_logtable are merged, the number of files is reduced to 19 and the size of the stored data is reduced to 37 MB. This significantly improves the storage efficiency. The following figure shows the details.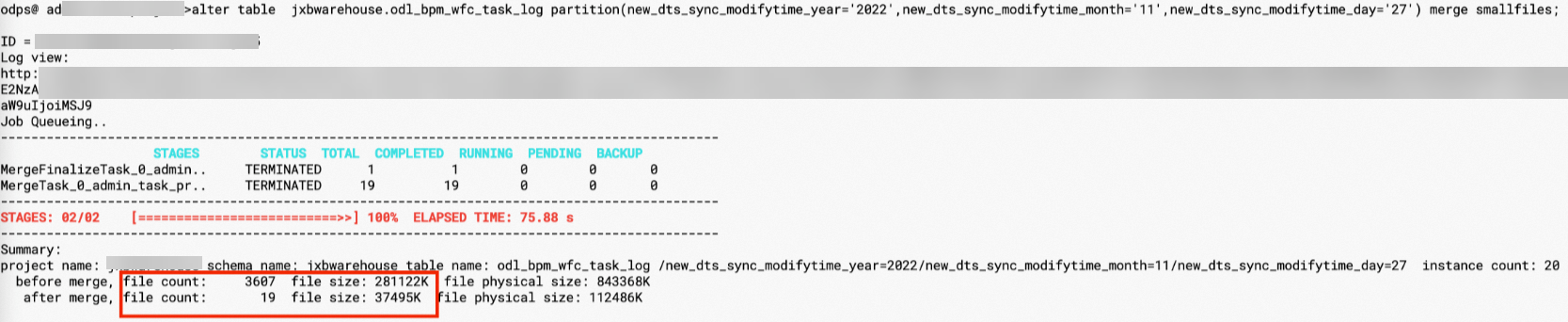
In most cases, you can use the default parameters to merge small files. MaxCompute also provides specific parameters to meet your business requirements. The following configurations are commonly used:
set odps.merge.cross.paths=true|falseSpecifies whether to merge files across paths. If multiple partitions exist in a table, files in the MergeAction processes that are separately generated for each partition are merged during the merge process. If the
odps.merge.cross.pathsparameter is set to true, the number of paths is not changed, but the small files in each path are separately merged.set odps.merge.smallfile.filesize.threshold = 64Specifies the threshold for the size of a small file that can be merged. If the size of a file exceeds this threshold, the file is not merged with other small files. Unit: MB. This parameter is optional. If you do not configure this parameter, you can use the global variable
odps_g_merge_filesize_threshold. The default value of this variable is 32 and the unit is MB. If you configure this variable, specify a value that is greater than 32.set odps.merge.maxmerged.filesize.threshold = 500Specifies the threshold for the size of the output file after merging. If the size of the output file is greater than this threshold, a new output file is created. Unit: MB. This parameter is optional. If you do not configure this parameter, you can configure the global variable
odps_g_max_merged_filesize_threshold. The default value of this variable is 500 and the unit is MB. If you configure this variable, specify a value that is greater than 500.
Merge small files by using a PyODPS script
You can use PyODPS to asynchronously submit a task to merge the small files that are generated by the task on the previous day. Sample script:
import os from odps import ODPS # Set the environment variable ALIBABA_CLOUD_ACCESS_KEY_ID to your AccessKey ID. # Set the environment variable ALIBABA_CLOUD_ACCESS_KEY_SECRET to your AccessKey secret. # We recommend that you do not directly use your AccessKey ID or AccessKey secret. o = ODPS( os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'), os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'), project='your-default-project', endpoint='your-end-point', ) # Replace $table_name with the name of the required table. table_name = $table_name t = odps.get_table(table_name) # Configure the merge option. hints = {'odps.merge.maxmerged.filesize.threshold': 256} #examples for multi partition insts = [] # iterate_partitions is used to list all partitions under ds=$datetime. The partition format may differ for each partition. for partition in t.iterate_partitions(spec="ds=%s" % $datetime): instance=odps.run_merge_files(table_name, str(partition), hints=hints) # Click Waiting Queue in this Logview to find the Logview in which the command is run. print(instance.get_logview_address()) insts.append(instance) # Wait for the partitioning result. for inst in insts: inst.wait_for_completion()You must install PyODPS before you run the preceding script. For more information about how to install PyODPS, see PyODPS.
Example
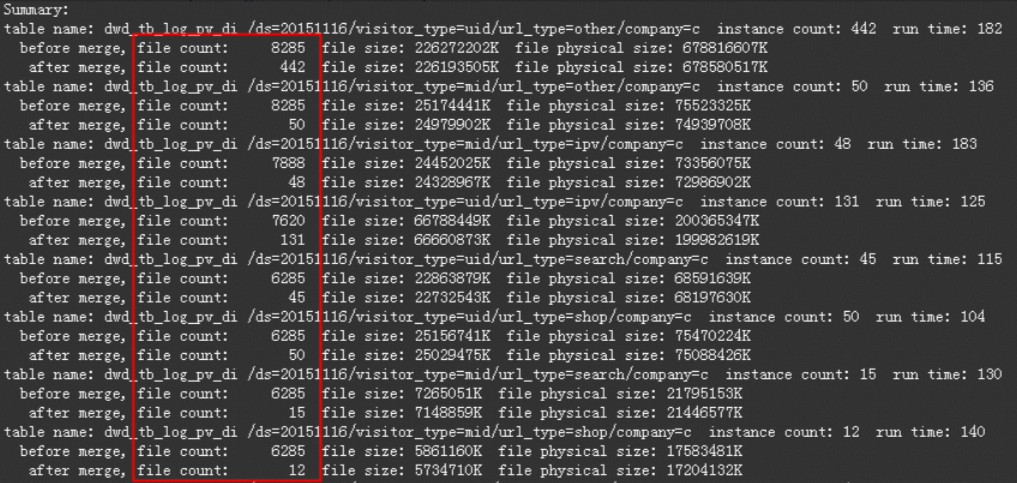
A data stability system determines that the physical table tbcdm.dwd_tb_log_pv_di contains a large number of small files and the small files need to be merged. The metadata table tbcdm.dws_rmd_merge_task_1d indicates that most partitions in the table contain more than 1,000 files and even more than 7,000 files. However, the average file size of some partitions is even less than 1 MB. The following figure shows the information of the metadata table named tbcdm.dws_rmd_merge_task_1d.  Run the following commands to merge the small files:
Run the following commands to merge the small files:
set odps.merge.cross.paths=true;
set odps.merge.smallfile.filesize.threshold=128;
set odps.merge.max.filenumber.per.instance = 2000;
alter table tbcdm.dwd_tb_log_pv_di partition (ds='20151116') merge smallfiles;The following figure shows the result after the small files are merged.