Data bloat occurs when a Fuxi task's output data volume is far larger than its input — for example, 1 GB in and 1 TB out. Processing that volume on a single instance significantly reduces data processing efficiency.
To identify data bloat, check the I/O Record and I/O Bytes attributes of Fuxi tasks on the Logview page.
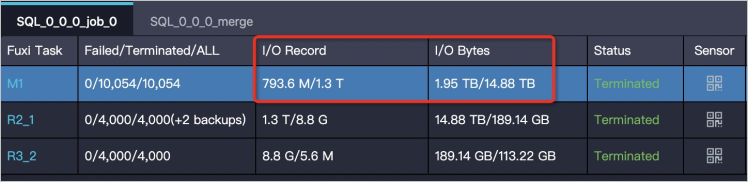
Three patterns cause data bloat: a bug in the code, improper aggregation operations, and improper JOIN operations. The sections below explain how to recognize each pattern and fix it.
Fix bugs that produce a Cartesian product or invalid UDTF output
How to recognize it: Check whether your query contains a JOIN without a valid equality condition, or a user-defined table-valued function (UDTF) that emits far more rows than expected. If output volume is orders of magnitude larger than input and the query logic appears straightforward — no complex grouping, no multi-row dimension table — a code bug is the likely cause.
Why it happens:
-
The
JOINcondition is incorrect and evaluates as a Cartesian product. Every row from the left table is paired with every row from the right table, causing the output to be much greater than the input. -
A UDTF is invalid, causing it to emit far more rows than it should.
Fix: Review the JOIN condition and UDTF logic and correct the bug. The following example shows a common accidental Cartesian product and the corrected version:
-- Incorrect: missing join condition produces a Cartesian product
SELECT l.user_id, r.label
FROM user_data l
JOIN label_table r;
-- Correct: explicit equality condition
SELECT l.user_id, r.label
FROM user_data l
JOIN label_table r ON l.category_id = r.category_id;Avoid aggregation operations that retain all intermediate results
How to recognize it: A query uses collect_list, median, DISTINCT across multiple dimensions, GROUPING SETS, CUBE, or ROLLUP, and output is much larger than input. If removing or replacing one of these operations brings output back to a normal size, the aggregation pattern is the cause.
Why it happens:
Most aggregation operations are recursive — they merge intermediate results as they go, so intermediate data stays small regardless of input size. A few operations break this pattern:
-
collect_listandmedian: These operations must retain all intermediate result data, not just a running aggregate. Combining them with other aggregation operations can cause significant data expansion. -
SELECTwithDISTINCTacross dimensions: Each deduplication pass expands the data before filtering it down, and the expansion compounds across passes. -
GROUPING SETS,CUBE, andROLLUP: These operations generate intermediate result data for every grouping combination. Intermediate size can expand to many times the original data size.
Fix: Avoid combining collect_list or median with other aggregations where possible. Review queries that use GROUPING SETS, CUBE, or ROLLUP to confirm that the intermediate data volume is acceptable.
Aggregate right-table rows before performing a JOIN
How to recognize it: The query performs a JOIN on a low-cardinality key (such as gender or region), and the right table has many rows per key value. Check the number of rows per key value in the right table: if it is in the hundreds or more, this pattern is likely the cause.
Why it happens:
When you join on a low-cardinality key, each row in the left table is matched against every row in the right table that shares the same key value. For example:
-
Left table: a large amount of population data, joined on
gender -
Right table (dimension table): hundreds of rows per gender value
Each left-table row matches hundreds of right-table rows. The left table data may expand to hundreds of times its original size.
Fix: Aggregate the rows in the right table before performing the JOIN. Reduce the right table to one row per join key value first, then join.
-- Before: JOIN on raw dimension table (causes data bloat)
SELECT l.*, r.category
FROM population_data l
JOIN dimension_table r ON l.gender = r.gender;
-- After: aggregate right table first, then JOIN
SELECT l.*, r.category
FROM population_data l
JOIN (
SELECT gender, MAX(category) AS category
FROM dimension_table
GROUP BY gender
) r ON l.gender = r.gender;