Learn about how to code with Lingma.
Use keyboard shortcuts
Default keyboard shortcuts
Lingma provides ready-to-use keyboard shortcuts. The following table lists the most common ones:
Action | Windows | macOS |
Trigger completion at any position |
|
|
Replace generated results |
|
|
Accept all generated code |
|
|
Accept generated code line by line |
|
|
Close or open the AI Chat panel |
|
|
Additionally, in the AI Chat panel, press Cmd+Enter (macOS/Linux) or Ctrl+Enter (Windows) to create a line break, and press Enter to submit your question to the model.
Using the keyboard shortcut to replace generated results may yield a higher temperature parameter and sometimes more divergent content.
Custom keyboard shortcuts
JetBrains IDE
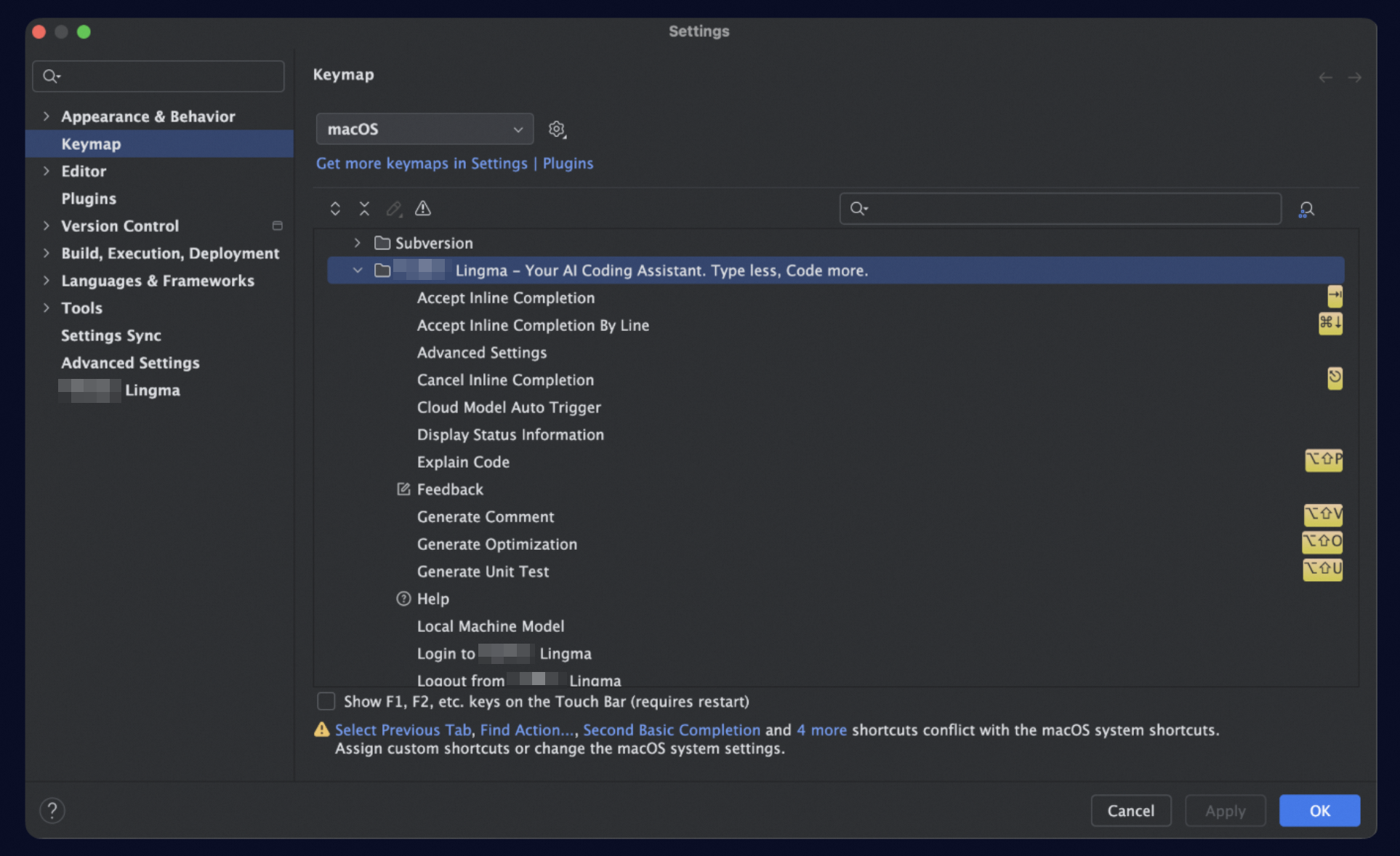
Go to the Settings page.
In the left-side navigation pane, select Keymap. Then, find and expand Lingma under Plugins to view and edit the related keyboard shortcuts
VSCode
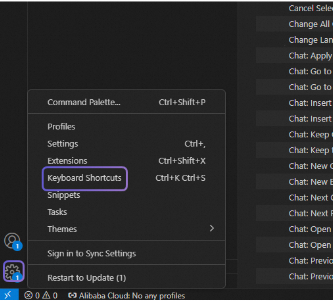
Click the settings icon in the lower-left corner of the IDE, then select Keyboard Shortcuts menu.
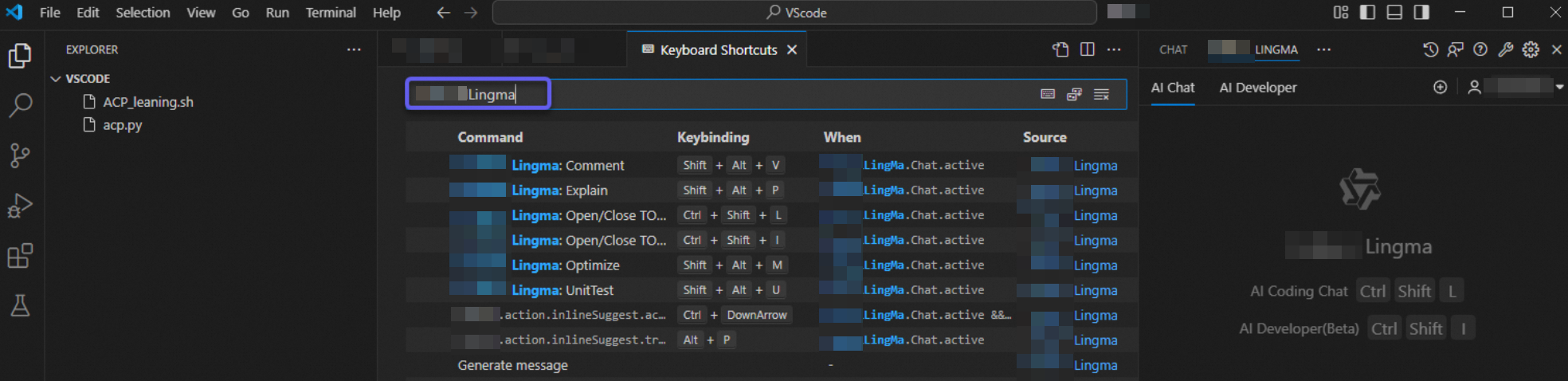
Search for Lingma on the page to view and edit all keyboard shortcuts.
 Note
NoteKeyboard shortcuts in VS Code are mostly named as Lingma to help you easily find them. But keyboard shortcuts for triggering inline suggestions, displaying the previous inline suggestion, and displaying the next inline suggestion follow a different naming convention because they reuse existing feature names.
Configure settings
IDE settings
JetBrains IDE
Go to the top-level menu, and select Settings, or click the Lingma icon in the status bar and select Advanced Settings.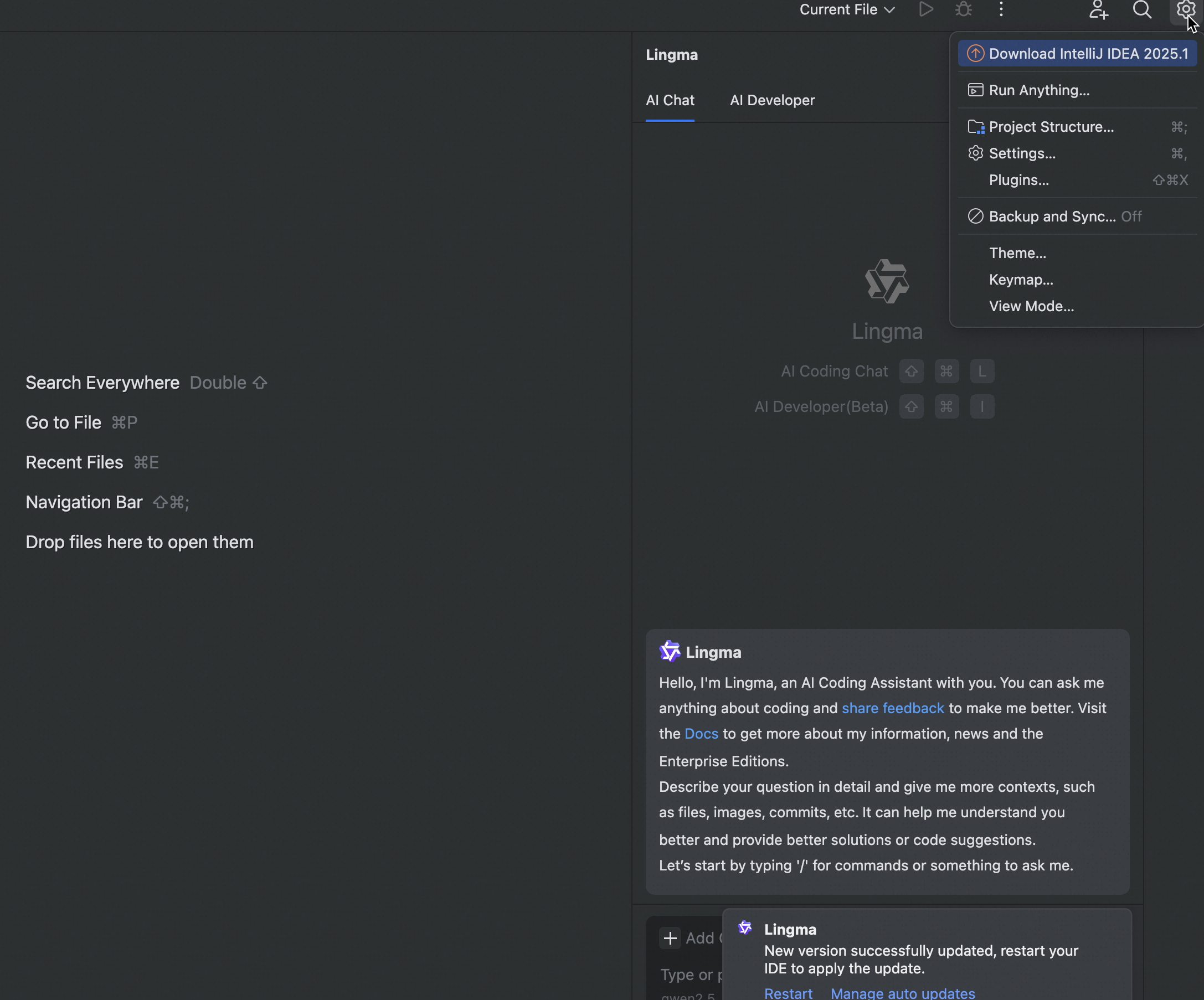
VSCode
Click the Lingma icon in the lower-right corner of the status bar and selecting Advanced Settings, or click the gear icon in the AI Chat panel.
Common configuration items
Disable auto-completion by file type.
If auto-completion creates interference when working with certain types of files, you can add those file extensions to the list. Multiple extensions should be separated by commas (for example: txt,md).
IDE
Configuration
JetBrains IDE

VSCode
 Note
NoteYou can disable auto-completion for specific file types to prevent automatic triggering of auto-completion. If you use the Alt+P keyboard shortcut to manually trigger auto-completion for the files, you can still use LLM-based code generation and completion.
Keep completion results when drop-down suggestions appear.
By default, when the IDE shows syntax-based drop-down completion suggestions, Lingma automatically stops showing large model completions to avoid visual conflicts.
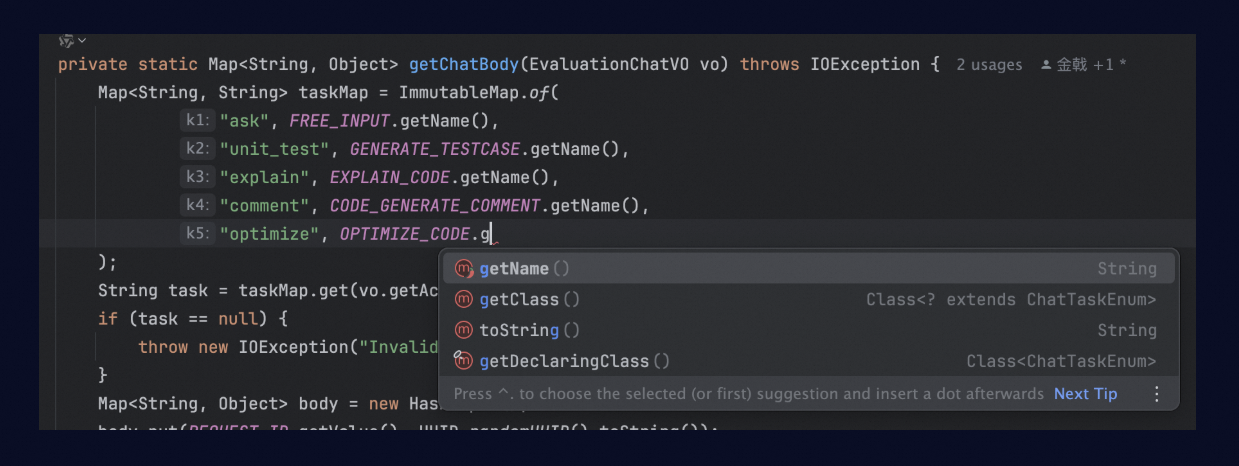
If you want Lingma to always generate LLM completions, you can select this configuration option. As shown in the figure below, pressing the Tab key will accept the large model's generated results.
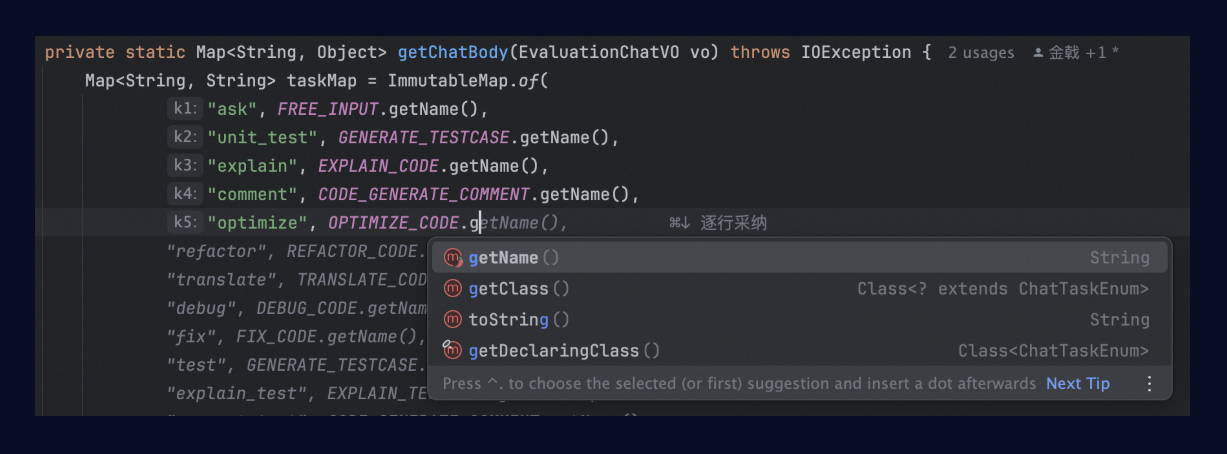
IDE
Configuration
JetBrains IDE

VSCode

Control the maximum length of the generated code.
Lingma supports setting different code completion length parameters for both automatic triggers and manual triggers. It's recommended to set the manual trigger (default shortcut
Alt+P) to generate slightly longer completions than automatic triggers.IDE
Configuration
JetBrains IDE

VSCode
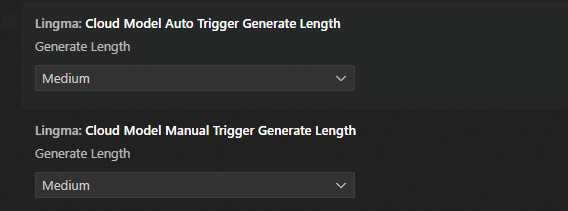 Note
NoteThis configuration option only sets the maximum length that the model is allowed to generate. If the content generated by the model in a completion is naturally shorter, modifying this configuration cannot force the model to generate longer content.
Use code comments
Guide code completion with comments
When there are no guiding comments, the model can only predict upcoming code based on current context and similar code found in project references. When the model's predictions are inaccurate, you can add comments to guide the model towards implementing the desired code.
For example, in the following code, the model first predicts a
CHAT_CONTEXTfield, which is not what we expect.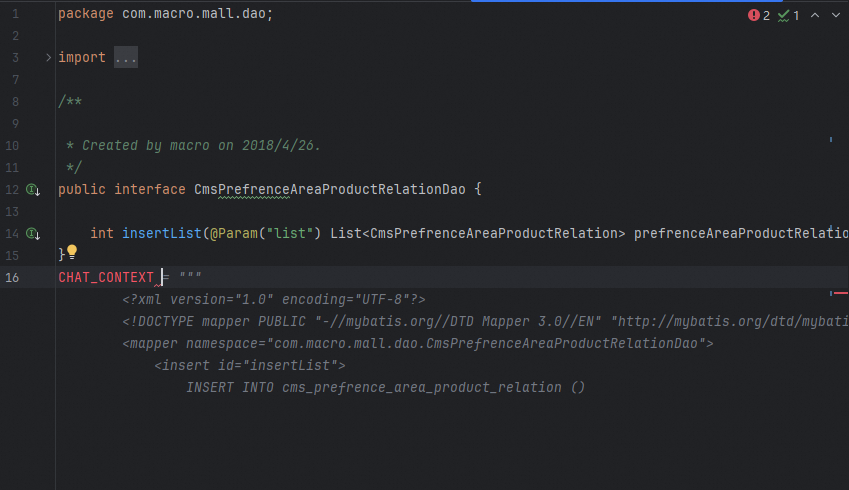
In this case, add a comment to instruct the model to generate a historical record field. Then, the model generates the expected field and its corresponding data code.
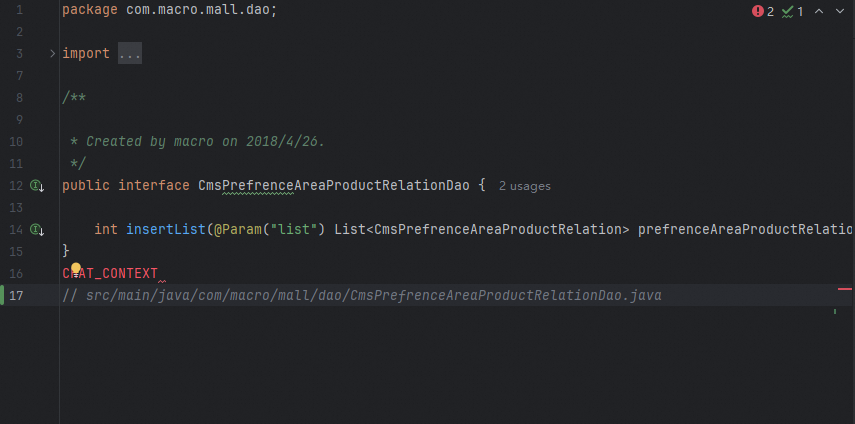
Use descriptions to generate methods
You can generate entire methods based on comments by either Comment to Code in the editor or use the AI Chat panel. Since Lingma's AI Chat typically uses larger model parameters than the code completion model, directly ask your question in the AI Chat panel.
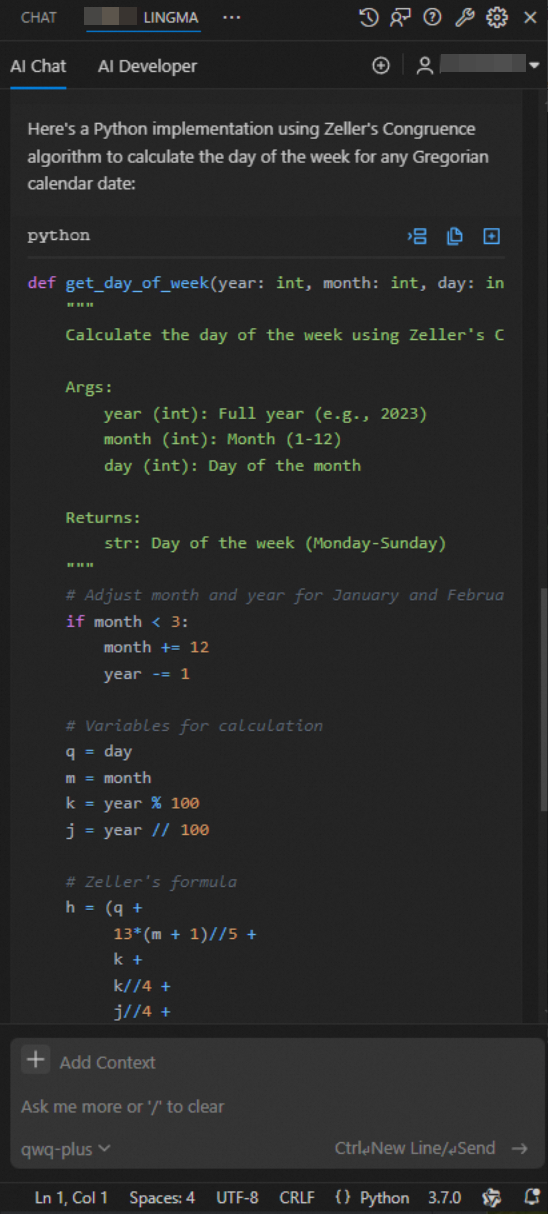
If you have specific requirements for the language or method signature (including method name, parameter types, return value types), describe these details in your prompt.
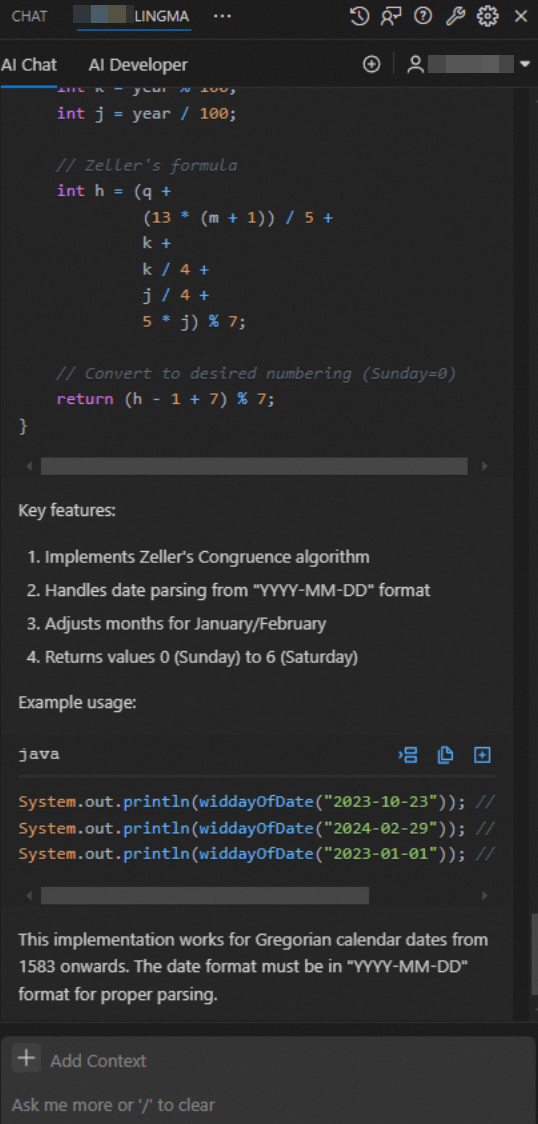
Use cross-file indexes
Save files and update indexes
Lingma's cross-file indexing is a crucial mechanism for preventing code hallucinations. By automatically identifying types and method definitions in the current context, the model can recognize members of types and method parameters from other files in the project. When first opening a new project, Lingma automatically creates the project's file index. Thereafter, each file save triggers an incremental index update for that file.
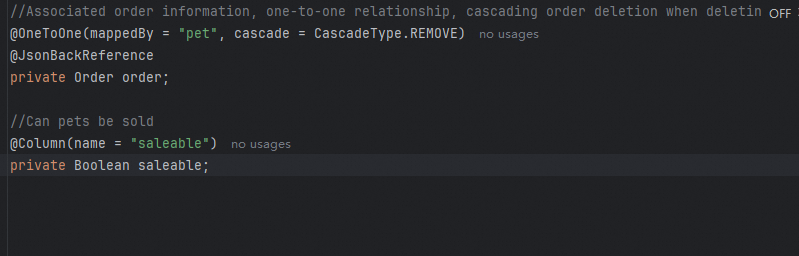 However, due to IDE memory caching, when switching to another file right after editing one, the local index might not have updated to recognize newly added or modified content, causing the model to reason based on the original type structure. For example, in a code project, add a saleable property to the
However, due to IDE memory caching, when switching to another file right after editing one, the local index might not have updated to recognize newly added or modified content, causing the model to reason based on the original type structure. For example, in a code project, add a saleable property to the Petobject.Then, switch to another file and try to let the LLM complete the code, but the model infers logic using another less relevant field.
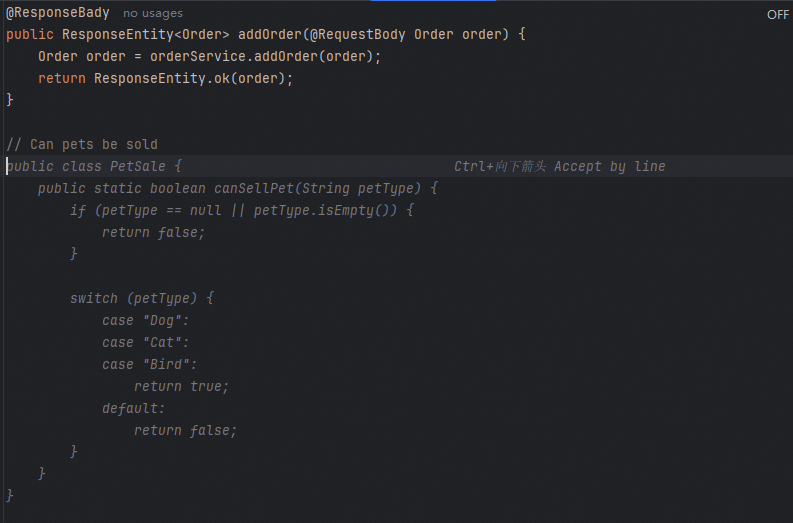
To eliminate such information discrepancy, actively press
Ctrl+S(Cmd+Sfor macOS/Linux) after editing the previous file, before continuing to edit other files. This ensures generated content correctly references the modified object structure.
Optimization solution for MyBatis scenarios
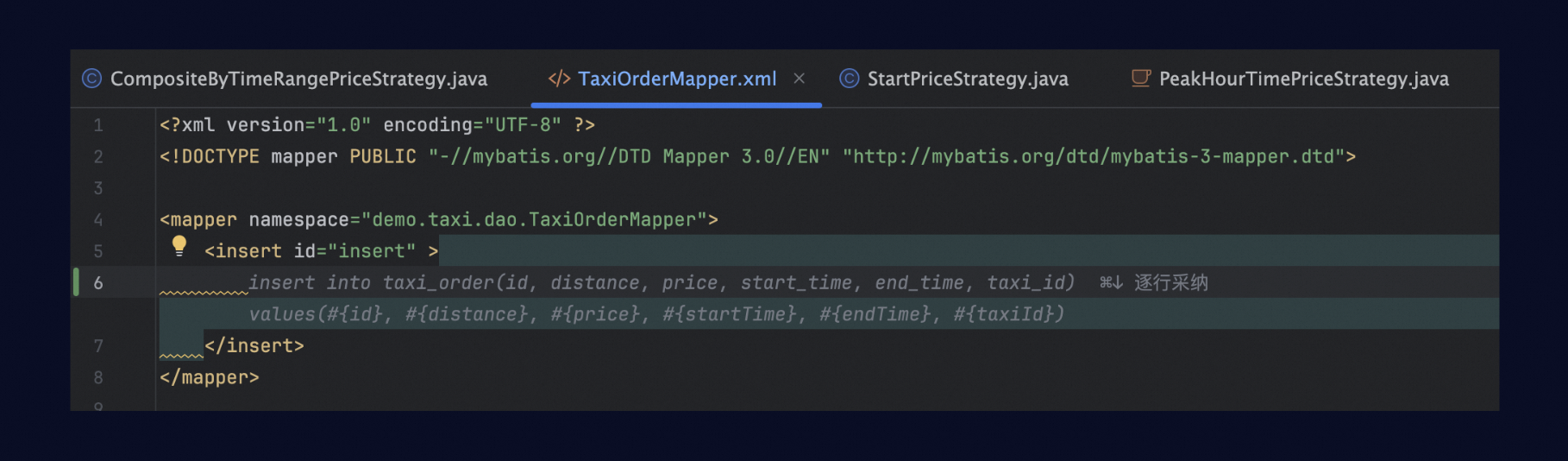
In addition to cross-file reference capabilities for mainstream programming language like Java, Python, and JavaScript, Lingma also supports automatically identifying the table structure types referenced by Mapper objects when writing MyBatis XML files. For example, when writing an insert statement, Lingma will use the TaxiOrder type information in the current project to ensure that each generated field is correct.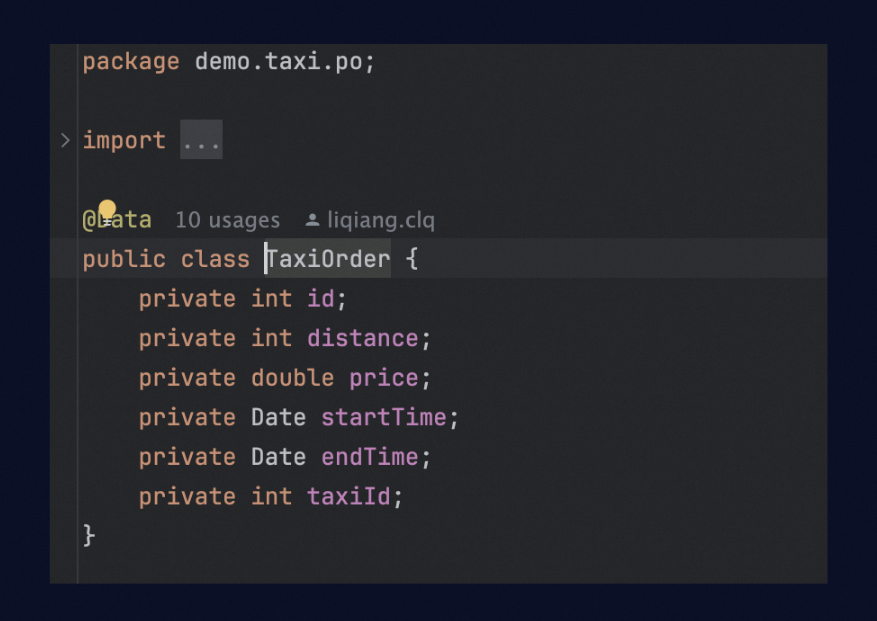
Manage context
Clear context timely
In each chat flow, previous conversation content is automatically provided to the model as context. When you ask a question unrelated to the previous content, this extra information may interfere with the model's response.
Click New Chat at the top of the AI Chat panel to start a new chat flow, or use the /clear context command to existing context without starting a new chat flow.
View chat history
After creating a new chat flow, you can:
Use the chat history feature to return to previous topics.
Continue asking follow-up questions.
Ask about code
General questions
Two ways to ask questions about code:
Paste the code into the chat box area.
Select a piece of code in the code editor, and then ask questions about it, for example:
Built-in code tasks
Lingma has four built-in code tasks:
Explain code
Generate unit tests
Generate code comments
Optimize code
The Lingma LLM has been specially trained for these tasks. For unit test generation, use the required built-in task instead of selecting code and entering a generation method.
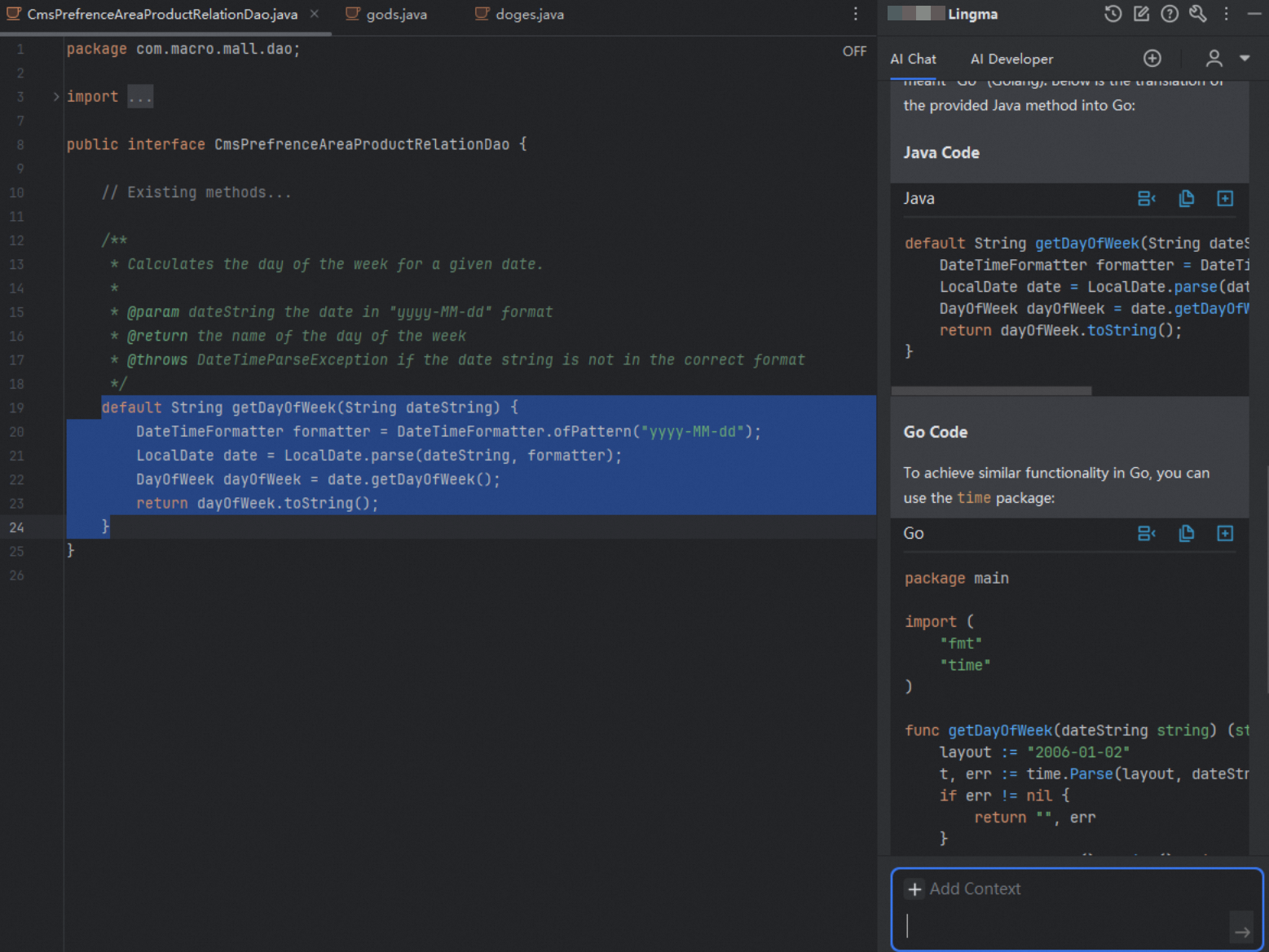
Lingma supports three methods for using the built-in code tasks. The most common method is to click the Lingma icon at the beginning of a method definition and select the task from the drop-down options.
Method 1: Use a drop-down menu in an IDE.
IDE
Configuration
JetBrains IDE
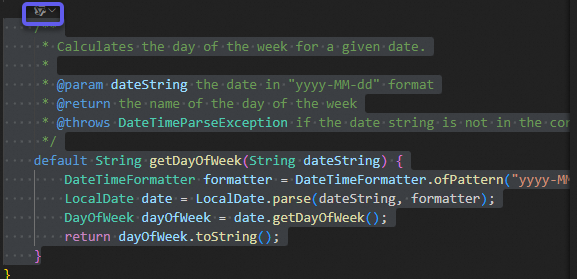
VSCode
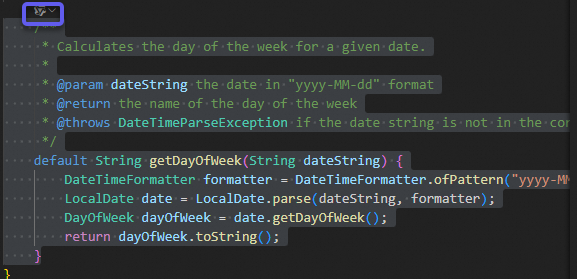
Method 2: Select code, right-click, and select Lingma from the context menu.
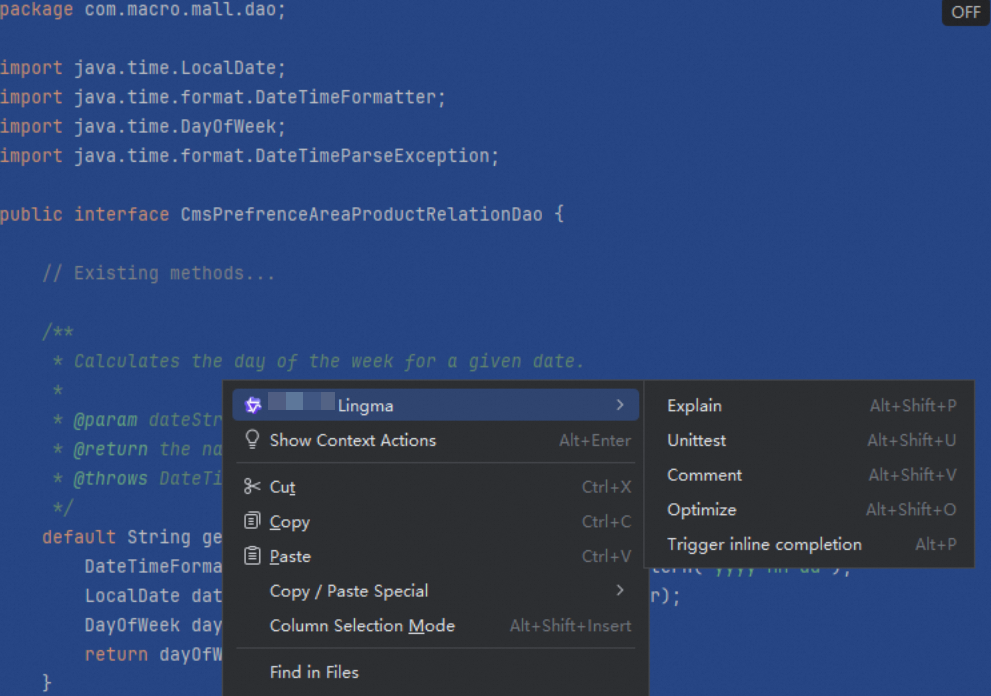
Method 3: Select code, type
/in the AI Chat panel to activate the built-in task menu, and then select the appropriate task.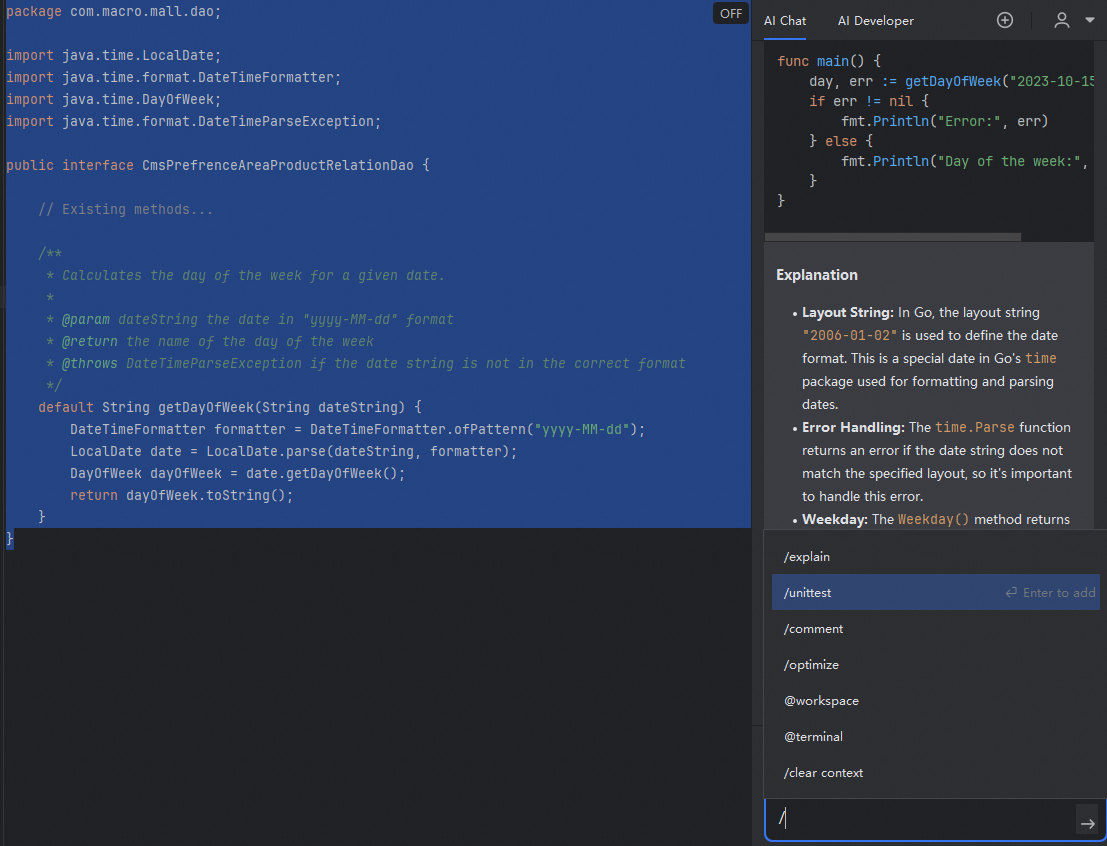
Prompt engineering
Reference code in questions
When asking questions, if you select text or code in the editor, the selection will automatically be appended to your question in Markdown quote format. Therefore, when referring to the selected code in your prompt, use phrases like "the following code" or "this content". For example:
Good example: Check whether the following code has a risk of an index out-of-bounds error.
Bad example: Check whether the selected code has a risk of an index out-of-bounds error. (In this example, the model cannot identify the selected code.)
Add contexts to commands
Add supplementary information to commands to provide richer context for chat, resulting in more accurate responses.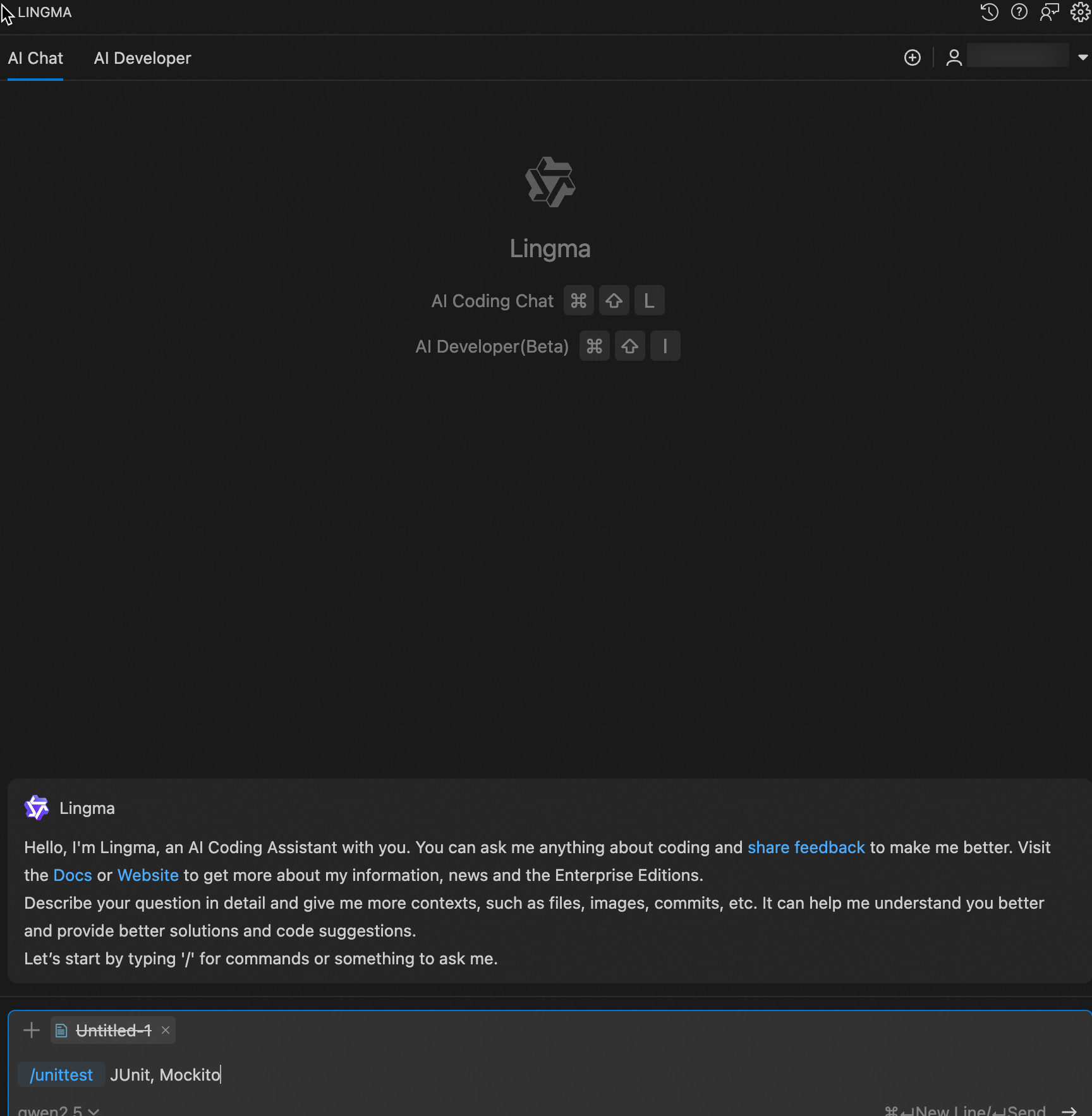
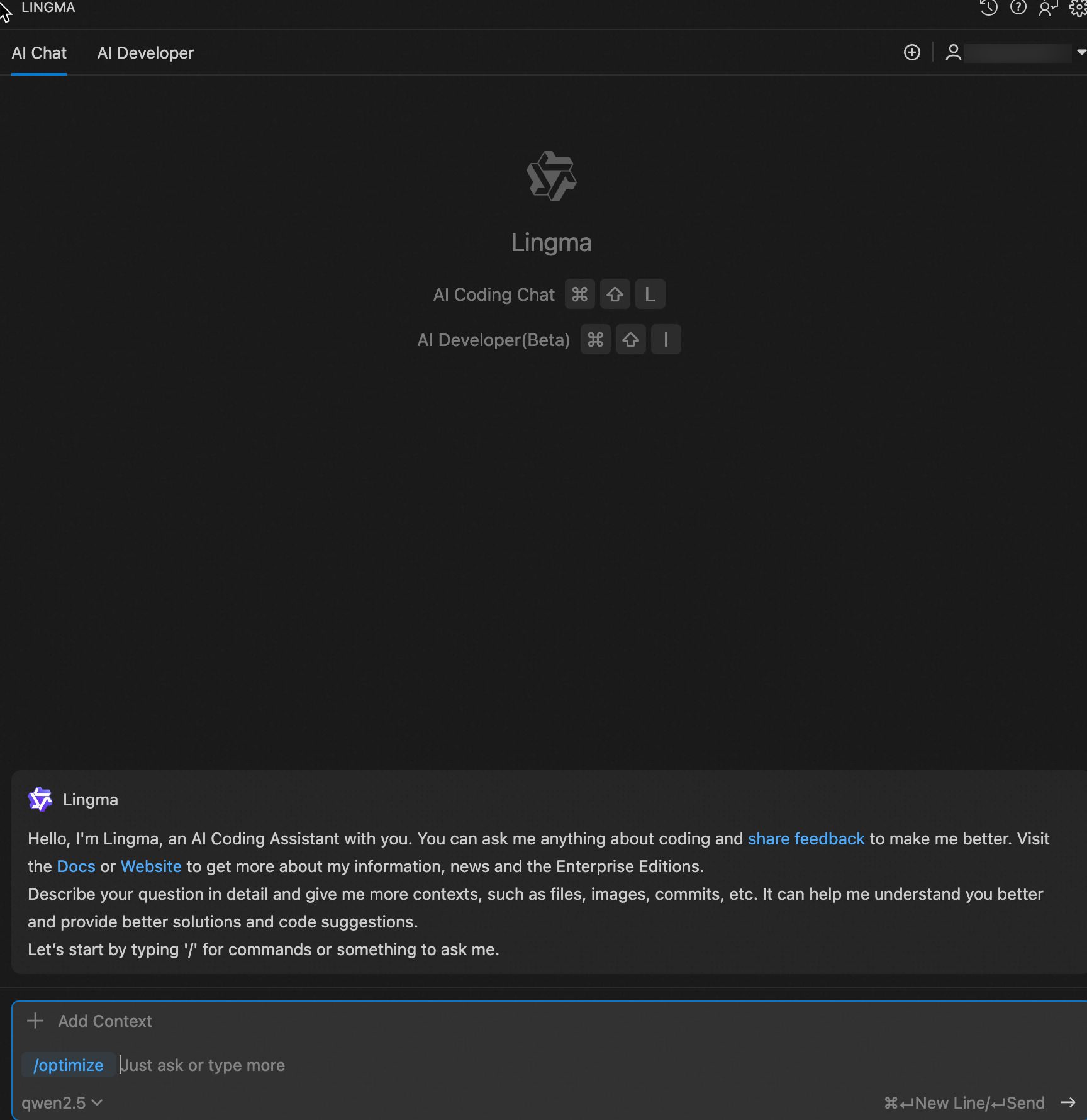
Generate effective code through multi-turn chat
When conversing with large language models, providing richer context leads to more accurate and expected results. You can build upon previous chat turns to add contextual information for subsequent questions, allowing the generated results to better reflect the entire historical context. However, when previous historical information becomes interfering, you should clear context timely.
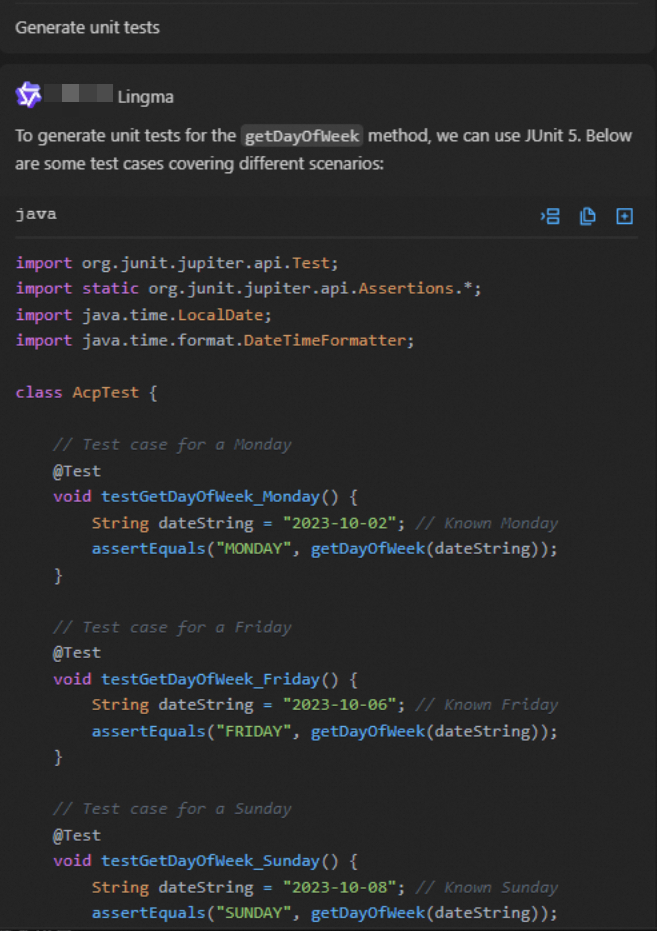 Based on the previous round, you can ask more in-depth follow-up questions.
Based on the previous round, you can ask more in-depth follow-up questions.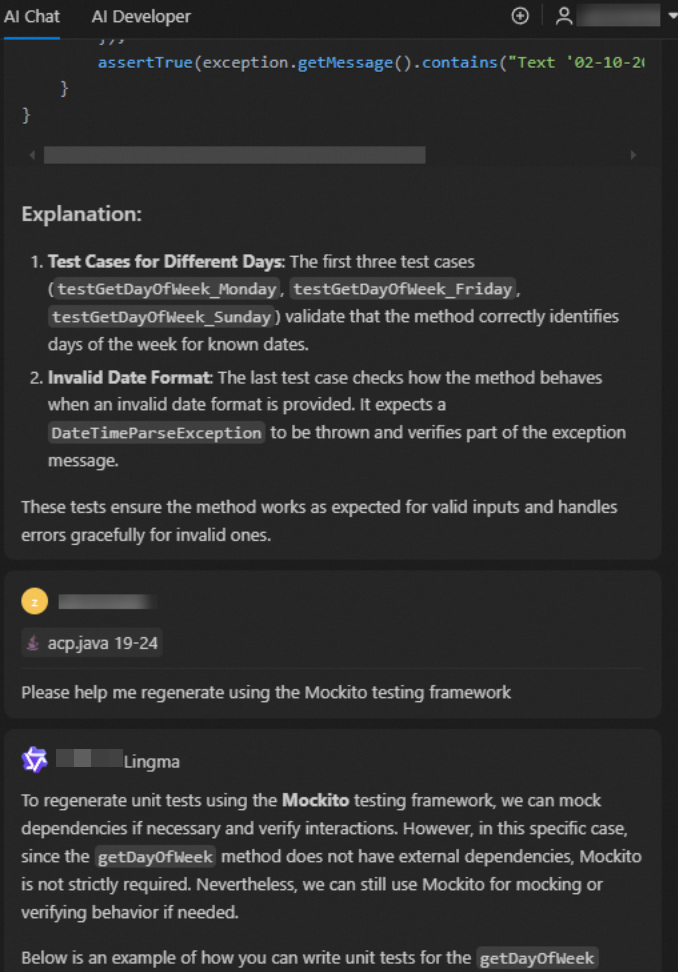
Provide examples for the model
When you need the model to output in a specific format or follow certain rules, providing a reference example often works better than just text descriptions. For instance, when formatting program test results into a specific JSON structure, first open the file, select all content, then ask questions in the chat box.
Compare these two prompts, where the second one produces more consistent output:
Prompt 1 (Less effective): Organize the file into a test report in the JSON format. Make sure that the results of each test case are organized into a JSON structure. Populate the name field with the test case name, the success field with the test case status, the duration field with the running duration in milliseconds, and the coverage field with the test coverage ratio. Make sure that the detail field is in the JSON format and includes the input and output fields for each test case.
Prompt 2 (More effective): Organize the file into a test report in the JSON format.
...Report content omitted...Refer to the following example as an input report.
[ { "name": "If the page number exceeds the valid value range, the system is expected to return an empty list or prompt no-more-data", "duration": 3434, "coverage": 80, "detail": [ { "input": "…", "output": "…" } ] } ]