LindormTable provides a new search type named search indexes. This topic describes how to use the open source HBase API and Elasticsearch API to access and use search indexes.
Background information
Search indexes provide a unified access method by integrating the capabilities of LindormTable that supports the open source HBase API and LindormSearch that supports the open source Elasticsearch API. This way, you can use search indexes to perform various types of queries. You can execute Lindorm SQL statements to connect to and use search indexes. In addition to this standard method, you can also use an open source client to use search indexes. For more information about search indexes, see Overview.
If you execute a Lindorm SQL statement to create a table, execute SQL statements to use search indexes.
Prerequisites
Java Development Kit (JDK) V1.8 or later is installed.
The IP address of your client is added to the whitelist of your Lindorm instance. For more information, see Configure whitelists.
Overview

Procedure
Execute SQL statements to create and use a search index (recommended)
If a table is created by using the HBase API, you can use Lindorm SQL to create a search index for the table for better convenience. This method allows you to use open source clients to create and use a search index.
Use Lindorm Shell to connect to LindormTable. For more information, see Use Lindorm Shell to connect to LindormTable.
Create a wide table named
testTable.create 'testTable', {NAME => 'f'}Use Lindorm SQL to map the columns in the wide table to those in the index table.
ALTER TABLE testTable MAP DYNAMIC COLUMN f:name HSTRING;For more information about the mappings between data types, see Data type mappings.
Create a search index named
idx.CREATE INDEX idx USING SEARCH ON testTable (f:name);Insert a row of data to
testTable.put 'testTable', 'row1', 'f:name', 'foo'NoteAfter the status of the created search index becomes
ACTIVE, data that is inserted to the wide table is automatically synchronized to the index table. For more information about how to see the status of an index, see SHOW INDEX. For data that is inserted to the wide table before the search index is created, you need to execute theALTER INDEXstatement to rebuild it. In this example, you can execute theALTER INDEX idx ON test REBUILD;statement to rebuild the data. In the statement,idxis the name of the search index created for the wide table. For more information, see ALTER INDEX.Query indexed data.
Use LindormSearch to query the primary key ID of the search index table.
NoteThe name of a search index table is concatenated in the following format:
<Namespace name>.<Wide table name>.<Index name>.The names of fields in a search index table is concatenated based on the following rules:
If the column family of the wide table is
f, the field name in the search index table is the same as the corresponding column name in the wide table. For example, the name of the field that corresponds to thef:namecolumn in the wide table isname.If the column family of the wide table is not
f, the field name in the search index table is the concatenated in the following format:<Column family name>_<Column name>For example, the name of the field that corresponds to thef1:namecolumn in the wide table isf1_name.
GET /default.testTable.idx/_search { "size": 10, "query": { "match": { "name": "foo" } } }The following result is returned:
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "default.testTable.idx", "_id" : "726f7731", "_score" : 1.0, "_source" : { "update_version_l" : 1720072175536 } } ] } }Obtain the primary key ID that is indicated by the _id field in the returned result.
Run the following command in Lindorm Shell to query data in the wide table: If a search index is created by executing SQL statements, the primary key ID of the search index table is the HEX-encoded primary key ID of the wide table. Therefore, when you use the primary key ID of the search index table to query data in the wide table, specify the primary key ID in the HEX format. For more information, see rowkeyFormatterType.
get 'testTable', "\x72\x6f\x77\x31"The following result is returned:
COLUMN CELL f:name timestamp=1644462597661, value=foo 1 row(s) Took 0.0942 seconds
Use Lindorm Shell to create a search index
Use Lindorm Shell to connect to LindormTable. For more information, see Use Lindorm Shell to connect to LindormTable.
Create a wide table named
testTablein Lindorm Shell.create 'testTable', {NAME => 'f'}Create a search index table named
democollectionin LindormSearch. For more information, see Connect to LindormSearch.NoteIf you do not need to obtain specific field values, you can set
_sourcetofalseto save resources.Map columns in the wide table to those in the index table. For example, map the
f:namecolumn in thetestTabletable to thename_scolumn in thedemocollectionindex table. In the f:name column, f specifies the column family name and name specifies the name of the column.In the
bindirectory of the file that is extracted from the HBase shell package, create a JSON file namedschema. Copy the following sample code to the JSON file:{ "sourceNamespace": "default", "sourceTable": "testTable", "targetIndexName": "democollection", "indexType": "ES", "rowkeyFormatterType": "STRING", "fields": [ { "source": "f:name", "targetField": "name_s", "type": "STRING" } ] }NoteMake sure that all columns specified in the mappings are explicitly defined in LindormSearch and their names and data types are the same as actual columns.
For more information about the parameters in the JSON file, see Configure column mapping.
Run the following command in Lindorm Shell to map columns in the wide table to those in the index table:
alter_external_index 'testTable', 'schema.json'NoteFor more information about how to manage column mappings between a wide table and an index table, see Manage a column mapping relationship.
Write a row of data to
testTable. After column mappings between the wide table and the index table are configured, the data that is written to the wide table is automatically synchronized to the index table in real time. For data that is inserted to the wide table before the mappings are configured, you need to manually create indexes for full data to synchronize it to the index table. For more information, see Create indexes for full data.put 'testTable', 'row1', 'f:name', 'foo'Query indexed data.
Use LindormSearch to query the primary key ID of the search index table.
GET /democollection/_search { "size": 10, "query": { "match": { "name_s": "foo" } } }The following result is returned:
{ "took" : 4, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "democollection", "_id" : "row1", "_score" : 1.0, "_source" : { "update_version_l" : 1720072175536 } } ] } }Obtain the primary key ID that is indicated by the _id field in the returned result.
Convert the primary key ID of the search index table to the primary key
row1of the wide table based on the rowkeyFormatterType parameter defined in the mappings. For more information, see rowkeyFormatterType. In this example, the STRING method is used to convert the primary key ID of the search index table. Therefore, the primary key ID of the search index table are the same as that of the wide table.Run the following command in Lindorm Shell to query data in the wide table:
get 'testTable','row1'The following result is returned:
COLUMN CELL f:name timestamp=1644462597661, value=foo 1 row(s) Took 0.0942 seconds
View the status of real-time data synchronization tasks on the Lindorm Tunnel Service (LTS) web UI. After column mappings between the wide table and the index table are configured, the data that is written to the wide table is automatically synchronized to the index table in real time.
To log on to the LTS web UI, click the instance ID in the Lindorm console. In the left-side navigation pane, choose . In the Data Synchronization Management section, click ClusterManager Internet or ClusterManager VPC.
In the left-side navigation pane, choose .
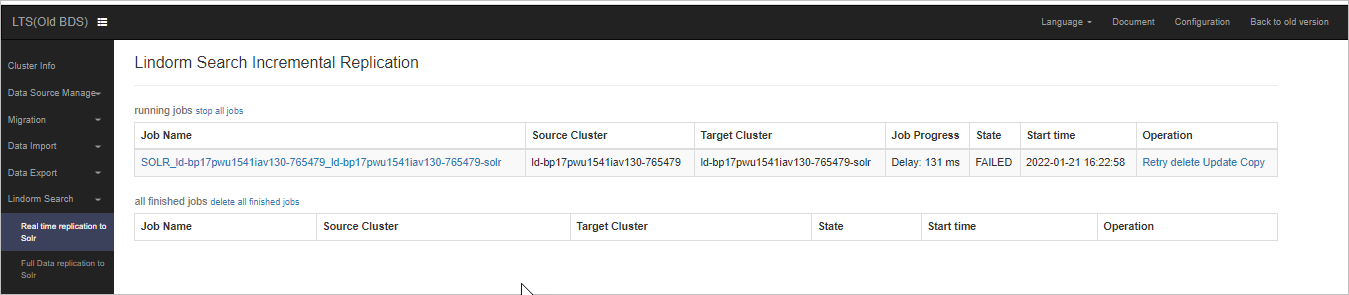 Note
NoteYou can configure the latency metric for real-time data synchronization in the CloudMonitor console. The alert threshold for the maximum task latency can be set to 600,000 milliseconds. For more information, see Cloud service monitoring.