Applies to asynchronous media processing tasks in ApsaraVideo VOD, Intelligent Media Services (IMS), and ApsaraVideo Media Processing (MPS). This topic provides a general guide to understanding asynchronous task timing and behavior, using transcoding as an example to illustrate task states and processing duration. Status fields, progress indicators, and query methods vary by task type. For details, refer to the documentation for each specific API or service.
Overview
ApsaraVideo VOD, IMS, and MPS provide a range of asynchronous media processing capabilities. An asynchronous task is submitted through an API call and processed in the background. Results become available after processing completes.
A successful task submission means the task has been accepted, not that processing has started or will finish within a fixed time.
Asynchronous tasks are essentially offline processing jobs. Unlike synchronous API calls, the time to produce results depends on multiple factors: task scheduling, workload fluctuations, task complexity, source file characteristics, and parameter configuration. The total completion time can be significantly longer than the actual processing time alone.
As a result, asynchronous tasks should not be used as blocking conditions in latency-sensitive workflows. Do not use the processing speed benchmarks in this document to estimate delivery timelines in production environments.
Scope
This guide applies to media processing tasks submitted and executed asynchronously in ApsaraVideo VOD, IMS, and MPS. These include, but are not limited to:
Media transcoding tasks.
Media editing and compositing tasks.
Snapshot and sprite sheet tasks.
Media analysis tasks.
AI-assisted media processing tasks.
Other media processing tasks that use an asynchronous submission and retrieval model.
Processing pipelines, duration characteristics, status fields, progress indicators, query methods, and notification mechanisms may differ across task types. If the documentation for a specific capability provides separate guidance, follow that documentation.
General timing guidelines
We recommend that you read this section before submitting tasks and design your business logic accordingly.
The total time to complete an asynchronous task typically consists of two parts:
Total completion time = Queue wait time + Actual processing timeWhere:
Queue wait time: The time between task submission and the start of actual processing.
Actual processing time: The time spent executing the task after processing begins.
A returned task ID only confirms that the task was created successfully.
The completion time you experience is the total completion time, not just the processing time.
Processing speed benchmarks describe typical processing characteristics. They do not constitute service commitments, SLA guarantees, delivery assurances, or grounds for compensation.
Even when task specifications closely match the benchmark scenarios, the total completion time can be significantly longer because of increased queue wait time.
If your business has strict timing requirements, build in buffer time and implement asynchronous decoupling, timeout fallbacks, and graceful degradation.
Total completion time vs. processing time
Understanding this distinction is key to working with asynchronous tasks.
Processing speeds, speed multipliers, and time estimates mentioned in this documentation refer only to the processing speed after a task begins actual processing.
The time you actually experience before results are available depends on:
How long the task waited before processing started.
How long the task took to process.
Therefore:
Processing time benchmarks do not equal total completion time.
Processing time benchmarks cannot be used to calculate delivery timelines.
Identical tasks submitted at different times may have noticeably different total completion times.
Queue wait time
After a task is submitted, the service schedules it based on task type, current workload, and processing policies.
Queue wait times may increase under the following conditions:
A large number of tasks are submitted within a short period.
Workload fluctuations occur during the same time window.
A high proportion of complex tasks are in the queue.
A successful submission does not mean the task has entered the processing stage.
Wait times can vary based on submission timing, task type, task volume, and processing pipeline differences.
Do not resubmit the same task during the wait period. Duplicate submissions can cause redundant processing and further increase overall wait times.
Use asynchronous callbacks to receive task results instead of high-frequency polling.
To check the current service status:
Increased wait times alone do not necessarily indicate a service issue. Many factors affect wait times. To confirm the current service status, contact technical support.
If a widespread service disruption occurs, Alibaba Cloud notifies affected users through in-console messages, SMS, or other channels.
Actual processing time
Actual processing time depends on the task type, source file characteristics, and task configuration. Different capabilities have different performance models.
Common factors that affect processing time
Factor | Pattern | Description |
Source file duration | Longer files take longer to process. | A primary factor for most media processing tasks. |
Output specifications | Higher output specifications take longer. | For example, higher resolution or more complex output formats. |
Algorithm complexity | More complex algorithms take longer. | For example, advanced transcoding or complex analysis. |
Custom parameters | More complex parameters take longer. | For example, enhancement parameters or multi-stage processing. |
Source file characteristics | More complex characteristics increase variance. | For example, bitrate, frame rate, container format, and stream structure. |
Task type | Different task types have different performance models. | Transcoding, editing, snapshot, and analysis tasks are not directly comparable. |
Differences across task types
Transcoding tasks: Processing time typically correlates with video duration, resolution, codec, transcoding algorithm, and template parameters.
Editing tasks: Additional factors include the number of segments, whether re-encoding is required, whether cuts cross keyframe boundaries, and multi-segment concatenation.
Snapshot, sprite sheet, and analysis tasks: Duration estimation methods may differ from transcoding. Whether progress fields, status fields, and stage breakdowns exist depends on the specific capability. Refer to the relevant documentation.
Task status and progress
Status fields, progress indicators, query methods, and result delivery mechanisms vary across asynchronous task types.
The status logic described in this document illustrates common processing stages. Not all asynchronous tasks follow the same status model.
From a general perspective, asynchronous tasks typically go through the following stages:
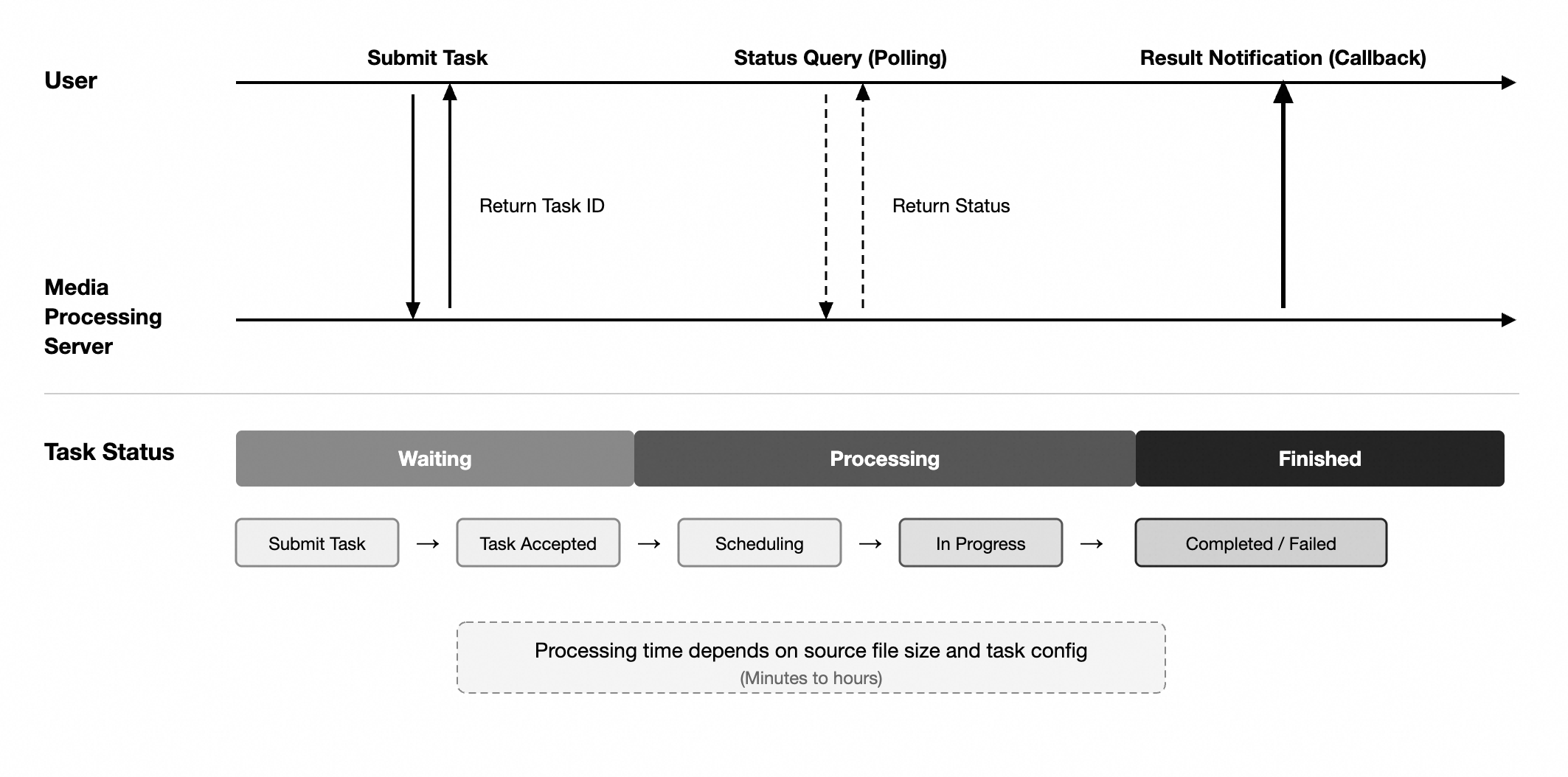
Keep in mind:
Some tasks expose a queryable progress field.
Some tasks return only a limited set of statuses, such as processing, completed, or failed.
For some tasks, the "waiting" state is not a discrete status value. You determine it by combining the status field with other fields.
Refer to the actual API response and the corresponding product documentation for exact status definitions.
Transcoding task example
The following section applies only to transcoding tasks. Other asynchronous tasks may use different mechanisms.
Transcoding task states
When you submit a transcoding task, the status field in the query result may show Transcoding.
Note that Transcoding indicates the task has entered the transcoding pipeline, but it does not necessarily mean that actual transcoding has started.
Combine the TranscodeProgress field to determine the current stage:
Status | TranscodeProgress | Meaning | Interpretation |
Transcoding/Submitted | 0 | The task has not started actual transcoding. | Waiting |
Transcoding/Percent/Running | > 0 | The task is being transcoded. | Processing |
Completed | 100 or task complete | Transcoding finished successfully. | Completed |
Failed | - | Transcoding terminated abnormally. | Failed |
For transcoding tasks, waiting is typically not a discrete status enum value. It is inferred by combining the task status with the transcode progress.
Transcoding speed benchmarks
The following benchmarks describe the processing speed of transcoding tasks under typical test conditions after actual processing begins. They do not include queue wait time, do not represent total completion time, and do not constitute service commitments.
The following table shows processing speed characteristics for different transcoding algorithms, using a typical H.264 720p scenario as a reference:
Algorithm | Processing speed benchmark | Description |
Standard transcoding | Approximately 3x speed | Reflects processing-stage speed under typical conditions only. |
Narrowband HD 1.0 | Approximately 1.5x speed | Actual processing time is typically longer than standard transcoding. |
Narrowband HD 2.0 | Typically well below 1x speed | Processing time usually exceeds source video duration. Actual results vary. |
Speed multiplier explained
Speed multiplier = multiple of video duration processed per unit of processing time
Example:
3x speed means approximately 3 minutes of video content is processed per 1 minute of processing time.
A 30-minute video, excluding queue wait time, would take approximately 10 minutes to process.These benchmarks apply only to the typical H.264 720p transcoding scenario.
They cannot be used to estimate total task completion time.
Higher resolution, more complex codecs, or heavier parameters typically result in lower processing speeds.
Differences in source video bitrate, frame rate, container format, and stream structure can significantly affect processing time.
Narrowband HD 2.0 is typically much more computationally intensive than standard transcoding and Narrowband HD 1.0.
Refer to the task status query or completion notification for actual processing times.
FAQ
1. Will a 10-minute 720p transcoding task always finish in 3-4 minutes?
Not necessarily.
The "approximately 3x speed" benchmark describes the processing speed under typical test conditions after the task enters the actual processing stage. It does not include queue wait time and does not represent total completion time in production environments.
The time you actually experience before results are available is determined by the final completion time. Do not use processing speed benchmarks to estimate delivery timelines.
If the total time exceeds your expectations, refer to the General troubleshooting section, or contact technical support.
2. Why does my transcoding task show Transcoding status with TranscodeProgress stuck at 0?
For transcoding tasks, Transcoding means the task has entered the transcoding pipeline, but it does not mean actual transcoding has started.
When TranscodeProgress = 0, the task is still in the waiting stage. When TranscodeProgress > 0, actual transcoding is in progress.
3. Why is my task taking much longer than the benchmark, even with similar specifications?
Possible reasons include:
The task waited in the queue for an extended period before processing began.
The source file characteristics differ from the typical benchmark scenario.
Task parameters or template configuration is more complex than standard settings.
Workload fluctuations during the same time window increased total completion time.
For further investigation, contact technical support and provide the task ID.
4. Does increased wait time always indicate a service issue?
Not necessarily.
Wait times are affected by multiple factors, including workload and task characteristics. An increase in wait time alone does not indicate a service issue. To confirm the current service status, contact technical support.
5. Can I use processing speed benchmarks to commit to business delivery times?
We do not recommend this approach.
Processing speed benchmarks help you understand task processing characteristics. They should not be used directly as production delivery timelines, business SLAs, or commitments to end users.
For scenarios with strict timing requirements, build buffer time into your architecture and implement timeout fallbacks and graceful degradation mechanisms.
6. Can I use the transcoding status model for other asynchronous tasks?
Not necessarily.
The Transcoding and TranscodeProgress fields in the transcoding example are specific to transcoding tasks.
For editing, snapshot, sprite sheet, analysis, and other asynchronous tasks, status fields, progress indicators, and interpretation methods may differ. Refer to the query API and product documentation for the specific task type.
Key operations
Submit a task
After you submit an asynchronous task through the API, the service returns a task ID.
The task ID is the unique identifier for querying status, correlating result notifications, and troubleshooting issues. Save it securely.
Result notifications
After a task completes, if you have configured a callback URL, the service proactively pushes a result notification. Use callbacks to detect task completion automatically, without continuous polling.
Callback guidelines
Use callbacks as the primary method to receive results in production environments.
If the callback URL is unreachable, the service retries automatically based on a predefined policy.
If delivery fails after multiple retries, use the query API to check the final task status.
Callback notifications may be delayed or delivered more than once because of network fluctuations or client-side issues.
Implement idempotency checks in your callback handler, using the task ID as the key.
The query API response is the authoritative source for the final task status.
For details about callback configuration and retry mechanisms, see Callback configuration.
Query a task
Query the current status and results of a task by its task ID. This applies in the following scenarios:
You have not configured callback notifications.
You have configured callbacks but want to check the current progress proactively.
The task is taking longer than expected.
Callback notifications failed to deliver and you need a fallback method.
Task information queries
The query API primarily returns task status, progress, and result information. If a task takes significantly longer than expected, investigate by reviewing status changes, submission time, and task configuration. If you cannot determine the cause, contact technical support and provide the task ID.
General troubleshooting
When a task takes longer than expected, follow these steps:
Step 1: Check whether the task has completed
Query the task status or result by task ID:
If the task completed, retrieve the result and evaluate the total duration.
If the task failed, review the error code and error message.
If the task is still running, proceed to the next step to determine whether it is in the waiting or processing stage.
Step 2: Determine the current stage based on task type
For transcoding tasks: Combine the Transcoding status with TranscodeProgress to determine whether actual processing has started.
For other asynchronous tasks: Refer to the query API response fields and documentation for the specific task type. Do not apply the transcoding task model directly.
Step 3: Identify possible causes based on task characteristics
Symptom | Possible cause | Recommended action |
No results for an extended period | Workload fluctuations, increased wait time, service disruption, or complex task | Check the service status page. Contact technical support if needed. |
Processing time significantly longer than typical tasks | Complex source file, heavy parameters, or high task complexity | Review the source file and configuration. Contact support if needed. |
Task failed | Source file issues, parameter errors, or processing exceptions | Review the error code description and follow the remediation steps. |
Query returns no results | Incorrect task ID or the task was not submitted successfully | Verify the submission result and task ID. |
Step 4: Information to provide when contacting support
To help technical support investigate the issue, provide the following information:
Task ID.
Task submission time.
Task type (transcoding, editing, snapshot, analysis, or other).
Source file duration, resolution, and codec.
Template configuration or processing parameters.
Whether tasks were submitted in batch.
Observed symptoms and scope of impact.
Recommended integration patterns
Method | Description | Use case |
Asynchronous callbacks (recommended) | The service pushes results after the task completes. | Production environments and live business workflows. |
Polling | Query task status and results on a schedule. | Debugging, testing, and fallback when callbacks fail. |
Integration best practices
Use asynchronous callbacks as the primary method in production environments.
Avoid high-frequency polling to reduce unnecessary requests.
Implement idempotency controls when submitting tasks to prevent duplicate submissions.
Stagger batch submissions to avoid short-term queue buildup.
Set up task timeout monitoring, alerts, and manual intervention mechanisms.
Allow sufficient buffer time for critical business scenarios and design graceful degradation strategies.
Do not use processing speed benchmarks directly for production delivery commitments.
SLA and responsibility boundaries
If you suspect that a service disruption caused task processing delays, contact technical support and provide the task ID and related information.
Service availability, liability determination, and compensation scope are governed by the formal service agreement and SLA.
Task timing descriptions, processing speed benchmarks, examples, and FAQ content in this document help you understand asynchronous task processing. They do not constitute standalone completion time commitments, service compensation grounds, or business liability guarantees.
Tips
To reduce the impact of asynchronous task latency fluctuations on your business:
Use asynchronous decoupling for media processing tasks in your system design.
Use callbacks or status queries to detect task results instead of blocking synchronously.
Allow extra buffer time for peak periods, batch submissions, and complex tasks.
Implement task timeout alerts, manual intervention procedures, and business fallback mechanisms.
For further questions, refer to the relevant product documentation.