Real-time materialized views in Hologres pre-aggregate base table data and store the results. Queries read from the view instead of recomputing the aggregation on the fly, which reduces query latency and computational overhead.
Unlike traditional materialized views that require manual refresh, Hologres materialized views update automatically. Changes written to the base table are reflected in the view immediately — no scheduled refresh jobs needed.
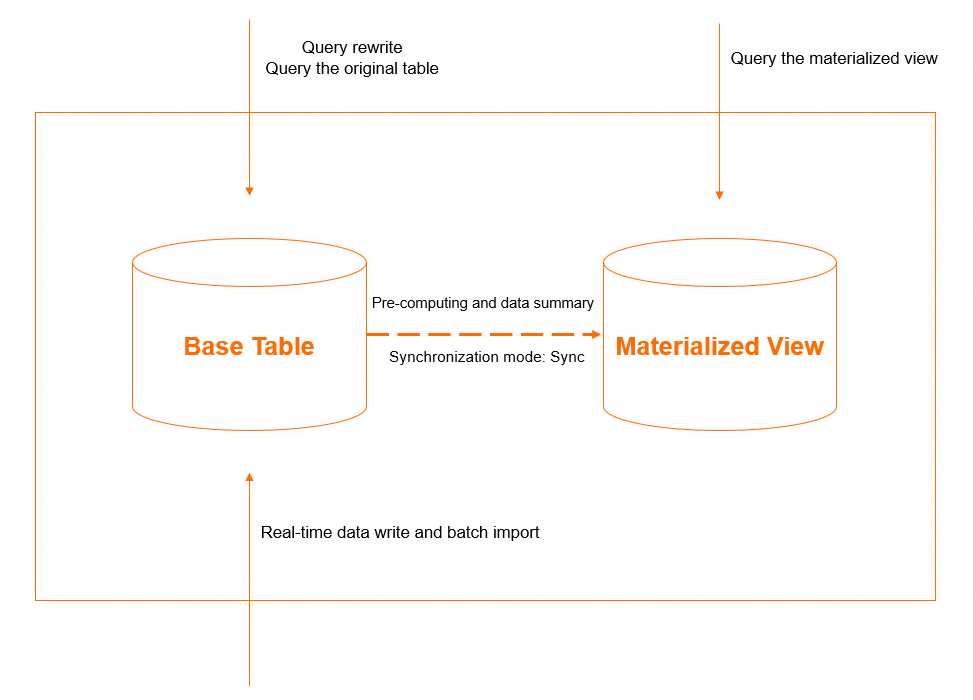
The table that receives real-time writes is called the base table. All INSERT, UPDATE, and DELETE operations target the base table. The materialized view is defined by aggregation rules on the base table and reflects INSERT changes in real time. Support for UPDATE and DELETE change synchronization will be added in a future release.
When to use materialized views
Materialized views are a good fit when:
Queries repeatedly aggregate large volumes of raw data (dashboards, reporting, analytics)
The aggregation result is queried far more often than the base table is written to
Query latency on the base table is a bottleneck — even with indexes
Avoid materialized views when the aggregation result has roughly as many rows as the base table (poor compression ratio), or when the query pattern changes frequently, making the fixed GROUP BY key impractical.
Supported aggregate functions
| Function | Notes |
|---|---|
SUM | |
COUNT | |
AVG | |
MIN | |
MAX | |
RB_BUILD_CARDINALITY_AGG | BIGINT data type only. Requires the roaringbitmap extension. |
Prerequisites
Before you begin, ensure that you have:
A Hologres instance with write access
The
roaringbitmapextension created (only required forRB_BUILD_CARDINALITY_AGG)
Create a real-time materialized view
Create the base table and the materialized view together in a single transaction. The base table must have the appendonly mutate type.
BEGIN;
CREATE TABLE base_sales(
day text NOT NULL,
hour int,
ts timestamptz,
amount float,
pk text NOT NULL PRIMARY KEY
);
CALL SET_TABLE_PROPERTY('base_sales', 'mutate_type', 'appendonly');
-- After dropping the materialized view, remove the appendonly property if needed:
-- CALL SET_TABLE_PROPERTY('base_sales', 'mutate_type', 'none');
CREATE MATERIALIZED VIEW mv_sales AS
SELECT
day,
hour,
avg(amount) AS amount_avg
FROM base_sales
GROUP BY day, hour;
COMMIT;Insert data into the base table. The view reflects the new data immediately.
INSERT INTO base_sales VALUES (to_char(now(),'YYYYMMDD'), '12', now(), 100, 'pk1');
INSERT INTO base_sales VALUES (to_char(now(),'YYYYMMDD'), '12', now(), 200, 'pk2');
INSERT INTO base_sales VALUES (to_char(now(),'YYYYMMDD'), '12', now(), 300, 'pk3');Query a materialized view
Query the view directly using standard SQL.
SELECT * FROM mv_sales WHERE day = to_char(now(),'YYYYMMDD') AND hour = 12;Alternatively, query the base table and let intelligent routing redirect to the view automatically. See Intelligent routing for materialized views.
Create a materialized view for a partitioned table
When the base table is partitioned, the GROUP BY key of the materialized view must include the partition key column. Create the materialized view on the parent table — not on individual child tables.
BEGIN;
CREATE TABLE base_sales_p(
day text NOT NULL,
hour int,
ts timestamptz,
amount float,
pk text NOT NULL,
PRIMARY KEY (day, pk)
) PARTITION BY LIST(day);
CALL SET_TABLE_PROPERTY('base_sales_p', 'mutate_type', 'appendonly');
-- day is the partition key and must appear in the GROUP BY clause
CREATE MATERIALIZED VIEW mv_sales_p AS
SELECT
day,
hour,
avg(amount) AS amount_avg
FROM base_sales_p
GROUP BY day, hour;
COMMIT;
-- Use CREATE TABLE PARTITION OF to add partitions (ATTACH PARTITION is not supported)
CREATE TABLE base_sales_20220101 PARTITION OF base_sales_p FOR VALUES IN ('20220101');More operations
Check storage size
Check the storage size of a single materialized view:
SELECT pg_relation_size('mv_sales');List all materialized views sorted by storage size:
SELECT schemaname || '.' || matviewname AS mv_full_name,
pg_size_pretty(pg_relation_size('"' || schemaname || '"."' || matviewname || '"')) AS mv_size,
pg_relation_size('"' || schemaname || '"."' || matviewname || '"') AS order_size
FROM pg_matviews
ORDER BY order_size DESC;Drop a materialized view
DROP MATERIALIZED VIEW mv_sales;Precise UV calculation with RoaringBitmap
Precise unique visitor (UV) calculation — counting distinct user IDs — is computationally expensive and is a common performance bottleneck. RB_BUILD_CARDINALITY_AGG pre-aggregates BIGINT business ID fields into a RoaringBitmap in the materialized view, enabling real-time deduplication. Only BIGINT fields are supported for this aggregation.
-- The roaringbitmap extension must be created before use
CREATE EXTENSION IF NOT EXISTS roaringbitmap;
BEGIN;
CREATE TABLE base_sales_r(
day text NOT NULL,
hour int,
ts timestamptz,
amount float,
userid bigint,
pk text NOT NULL PRIMARY KEY
);
CALL SET_TABLE_PROPERTY('base_sales_r', 'mutate_type', 'appendonly');
CREATE MATERIALIZED VIEW mv_sales_r AS
SELECT
day,
hour,
avg(amount) AS amount_avg,
rb_build_cardinality_agg(userid) AS user_count
FROM base_sales_r
GROUP BY day, hour;
COMMIT;
INSERT INTO base_sales_r VALUES (to_char(now(),'YYYYMMDD'), '12', now(), 100, 1, 'pk1');
INSERT INTO base_sales_r VALUES (to_char(now(),'YYYYMMDD'), '12', now(), 200, 2, 'pk2');
INSERT INTO base_sales_r VALUES (to_char(now(),'YYYYMMDD'), '12', now(), 300, 3, 'pk3');
-- user_count holds the count of distinct userid values for that day+hour
SELECT user_count AS UV FROM mv_sales_r WHERE day = to_char(now(),'YYYYMMDD') AND hour = 12;Multi-dimensional aggregation with partial functions
Why standard AVG breaks across dimensions
A materialized view stores pre-aggregated results. If you define mv_sales with avg(amount) grouped by (day, hour), querying across just the day dimension produces incorrect results — the average of averages is not the total average.
Given this base data:
| Day | Hour | Amount | PK |
|---|---|---|---|
| 20210101 | 12 | 2 | pk1 |
| 20210101 | 12 | 4 | pk2 |
| 20210101 | 13 | 6 | pk3 |
A direct query on the view returns:
postgres=> SELECT * FROM mv_sales;
day | hour | amount_avg
-----------+------+------------
20210101 | 12 | 3
20210101 | 13 | 6Re-aggregating by day gives an incorrect result:
postgres=> SELECT day, avg(amount_avg) FROM mv_sales GROUP BY day;
day | avg
-----------+------
20210101 | 4.5 -- incorrect: true average is 4Use intermediate aggregation state
Instead of storing the final average, store the intermediate aggregation state using avg_partial. When querying across a different dimension, finalize the result with avg_final.
BEGIN;
CREATE TABLE base_sales(
day text NOT NULL,
hour int,
ts timestamptz,
amount float,
pk text NOT NULL PRIMARY KEY
);
CALL SET_TABLE_PROPERTY('base_sales', 'mutate_type', 'appendonly');
CREATE MATERIALIZED VIEW mv_sales_partial AS
SELECT
day,
hour,
avg(amount) AS avg,
avg_partial(amount) AS amt_avg_partial -- stores intermediate state
FROM base_sales
GROUP BY day, hour;
COMMIT;Query across a different aggregation dimension using avg_final:
postgres=> SELECT day, avg(avg) AS avg_avg, avg_final(amt_avg_partial) AS real_avg
FROM mv_sales_partial
GROUP BY day;
day | avg_avg | real_avg
-----------+---------+----------
20210101 | 4.5 | 4 -- real_avg is correctPartial and final function reference
| Standard function | Partial function | Final function |
|---|---|---|
| AVG | AVG_PARTIAL | AVG_FINAL |
| RB_BUILD_CARDINALITY_AGG | RB_BUILD_AGG | RB_OR_CARDINALITY_AGG |
Intelligent routing for materialized views
Query the base table directly — the optimizer automatically rewrites the query to use a matching materialized view. No changes to query syntax are required.
The optimizer selects a view when all of the following are true:
The view contains all columns referenced in the query (or columns from which the queried values can be derived).
The GROUP BY columns of the view include all GROUP BY columns in the original query.
If multiple views qualify, the optimizer picks the one with the fewest GROUP BY columns.
Aggregate functions supported for intelligent routing: SUM, COUNT, MIN, MAX.
AVG and RB_BUILD_CARDINALITY_AGG do not support intelligent routing.
TTL considerations
The underlying data of a materialized view shares the same time to live (TTL) as its base table. Do not set a separate TTL on the materialized view — inconsistent TTL values cause data inconsistency between the view and the base table.
When the base table's TTL expires and data is reclaimed, a query on the base table and a query on the view can return different results. For example:
Query on the base table after TTL expiration:
postgres=> SELECT day, hour, avg(amount) AS amount_avg FROM base_sales GROUP BY day, hour;
day | hour | amount_avg
-----------+------+------------
20210101 | 12 | 4
20210101 | 13 | 6Query on the view — the reclaimed data was already materialized and remains in the view:
postgres=> SELECT * FROM mv_sales;
day | hour | amount_avg
-----------+------+------------
20210101 | 12 | 3 -- stale; reflects pre-reclamation state
20210101 | 13 | 6To avoid this inconsistency, use one of the following approaches:
Do not set a TTL on the base table.
If a TTL is required, include a time-based field in the GROUP BY key of the view. When querying, avoid time ranges near the TTL expiration boundary.
Use a partitioned table without a TTL. Reclaim old data by dropping child partitions.
Limitations
Creation constraints
Materialized views must be created in the same transaction as the base table. Asynchronous creation is not supported.
A materialized view can reference only a single table. Common table expressions (CTEs), multi-table JOINs, subqueries, and WHERE, ORDER BY, LIMIT, and HAVING clauses are not supported.
The GROUP BY key and aggregate values do not support expressions. For example,
SUM(CASE WHEN cond THEN a ELSE b END),SUM(col1 + col2), andGROUP BY date_trunc('hour', ts)are not supported.A maximum of 10 materialized views per base table. Resource consumption grows proportionally with the number of views.
For partitioned tables: the GROUP BY key must include the partition key column; the view must be created on the parent table.
For partitioned tables:
ATTACH PARTITIONis not supported for adding partitions; useCREATE TABLE PARTITION OFinstead.
Operation constraints
DELETE and UPDATE operations on a base table are not supported. Set the
appendonlyproperty on the base table. Attempting a DELETE or UPDATE returns the errorTable XXX is append-only.When writing to the base table in real time using Flink, set
mutateTypetoInsertOrIgnore.DROP COLUMNon a base table that has a materialized view is not supported.Do not manually set a TTL on a materialized view. The view inherits the TTL of the base table. Setting a different TTL causes data inconsistency.
Best practices
Align GROUP BY key with the distribution key. Set the GROUP BY key of the materialized view to match the distribution key of the base table. This improves both the data compression ratio and query performance.
Put filter columns first in the GROUP BY key. Place columns frequently used in WHERE filters at the beginning of the GROUP BY key. This follows the leftmost matching principle of the clustering key and enables more efficient pruning.