Hologres is a real-time data warehouse that is compatible with PostgreSQL 11. Hologres is seamlessly integrated with the big data ecosystem to support real-time data writes with high concurrency. Data can be queried immediately after it is written. Hologres also supports accelerated queries of offline data and federated analytics on offline and real-time data. This helps you quickly build an enterprise-class real-time data warehouse.
Data synchronization in Hologres
Hologres is integrated with a large big data ecosystem and supports offline and real-time writing of data from multiple heterogeneous data sources.
Open source big data: Hologres supports the most popular open source big data components, such as Flink, Blink, and Spark. You can use the built-in Hologres connector to implement highly concurrent and real-time data writes.
Database data: Hologres is deeply integrated with DataWorks Data Integration (DataX and StreamX). You can use Hologres Writer and Hologres Reader to easily and efficiently synchronize data from a variety of databases to Hologres. Offline synchronization, real-time synchronization, and database-level synchronization are supported. This meets the data synchronization and migration requirements of enterprises.
After you synchronize real-time data or offline data to Hologres, you can use Hologres to analyze the data in multiple dimensions. For example, you can use Java Database Connectivity (JDBC) or Open Database Connectivity (ODBC) to query, analyze, and monitor the data. The results can be directly displayed in a visualized manner based on upstream services. For example, you can view the results in dashboards, reports, or applications. This achieves an end-to-end process of data writes and service analytics. The following figure shows the process.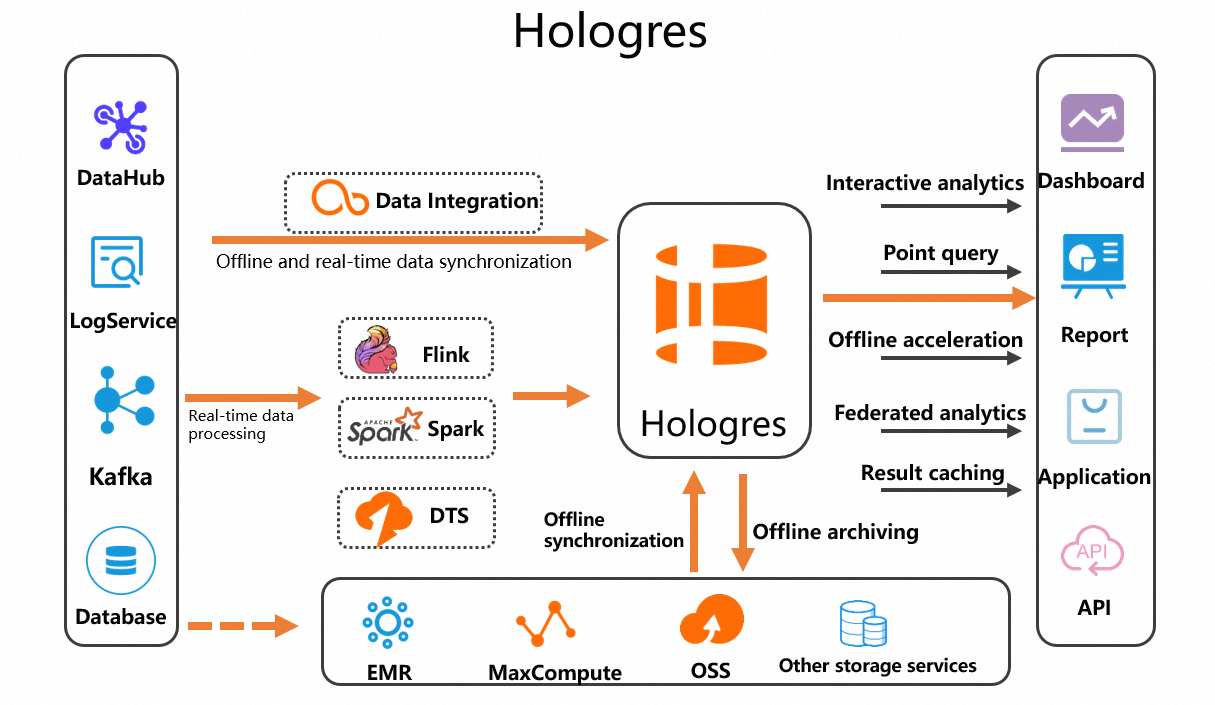
Common synchronization methods
The following table lists the supported methods for synchronizing data from common data sources to Hologres. You can select a synchronization method based on your business requirements.
Common data source | Built-in synchronization method of Hologres | Synchronization based on DataWorks Data Integration | Synchronization based on Flink |
MaxCompute | Supported (recommended, SQL statements) | Supported | Supported |
OSS | Supported (recommended, SQL statements) | Supported | Not supported |
Local file | Supported (COPY statement) | Not supported | Not supported |
Databases such as MySQL databases | Not supported | Supported (recommended) | Supported |
Kafka | Not supported | Supported | Supported |
DataHub | Supported (direct write to Hologres data sources) | Supported | Supported |
Open source connectors
The following table lists the synchronization connectors that are supported by Hologres. These connectors are open source connectors. You can select connectors based on your business conditions.
Connector | Scenario |
Holo Client is suitable for scenarios in which a large amount of data is written to Hologres in offline or real-time mode and scenarios in which point queries with high queries per second (QPS), such as dimension table-associated queries, are performed. Holo Client requires the JDBC driver and provides the C version and Go version. | |
Holo Shipper is used to import or export data in some tables of an instance for backup. It is suitable for instance data migration and database data migration. You can also dump data to an intermediate storage and then restore the data. | |
Holo-datax-writer is compatible with open source DataX and depends on the DataX framework. You can use open source DataX to write data from a variety of data sources to Hologres. Holo-datax-writer provides better performance than PostgreSQL Writer. | |
Holo-flink-connector is connected to open source Flink of 1.11, 1.12, 1.13, and later versions to implement high-performance real-time data writes. Note Realtime Compute for Apache Flink supports Hologres data sources. You can directly write data from Realtime Compute for Apache Flink to Hologres without the need to reference connectors. | |
Holo-Kafka-connector is used to write data from Kafka to Hologres. | |
Holo-Spark-connector is used to write data from Spark 2.x, 3.x, or later to Hologres with high performance. Both Apache Spark and Spark of Alibaba Cloud E-MapReduce (EMR) are supported. | |
Holo-Hive-connector is used to write data from Hive 2.x, 3.x, or later to Hologres with high performance. |