Hologres architecture
Hologres uses a Storage Disaggregation architecture. This page describes the architecture design and the role of each component.
Storage-computing architecture models
Three storage-computing architectures are commonly used in distributed systems.
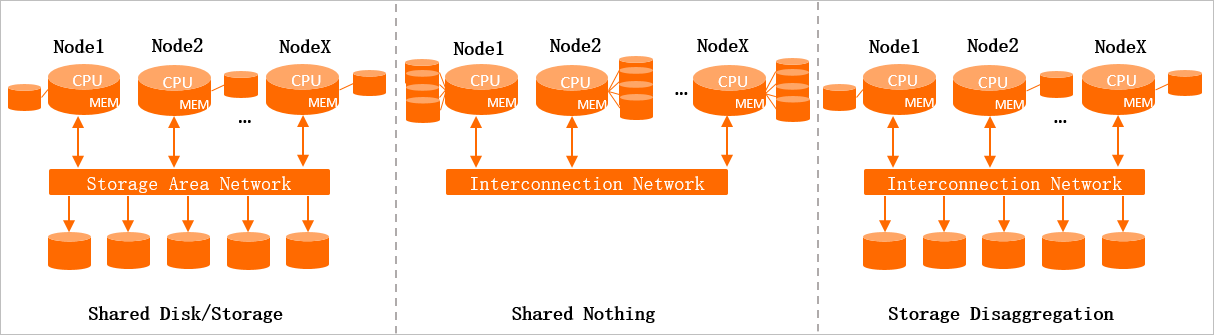
Shared Disk / Shared Storage
A distributed storage cluster is shared across all worker nodes. Each worker node accesses data as if it were local. The storage cluster scales easily, but worker nodes require distributed coordination to maintain consistency, which limits the maximum number of worker nodes.
Shared Nothing
Each worker node mounts its own local storage and processes data from a single shard. Worker nodes communicate with each other, and a dedicated summary node aggregates results. This architecture scales horizontally, but with trade-offs: after a failover, the recovering node must reload data before serving requests, and any scale-out triggers data rebalancing across nodes—a time-consuming process.
Storage Disaggregation
A distributed storage cluster is shared, but each computing node processes data from a dedicated shard—similar to Shared Nothing—and maintains a local cache. This architecture offers:
Effortless data consistency: Only one worker node writes to a shard at a time, eliminating complex coordination.
Flexible scaling: Computing and storage resources scale independently. During traffic peaks, scale out only the computing layer without triggering data rebalancing.
Fast failover recovery: After a failure, a new node pulls data from distributed storage asynchronously and resumes service quickly.
Hologres uses the Storage Disaggregation architecture, which combines the management simplicity of shared storage with the performance and scalability of shard-based computing. The underlying storage is Pangu, Alibaba's distributed file system, which provides a role similar to Hadoop Distributed File System (HDFS).
Components in Hologres architecture
The following figure shows the Hologres architecture.
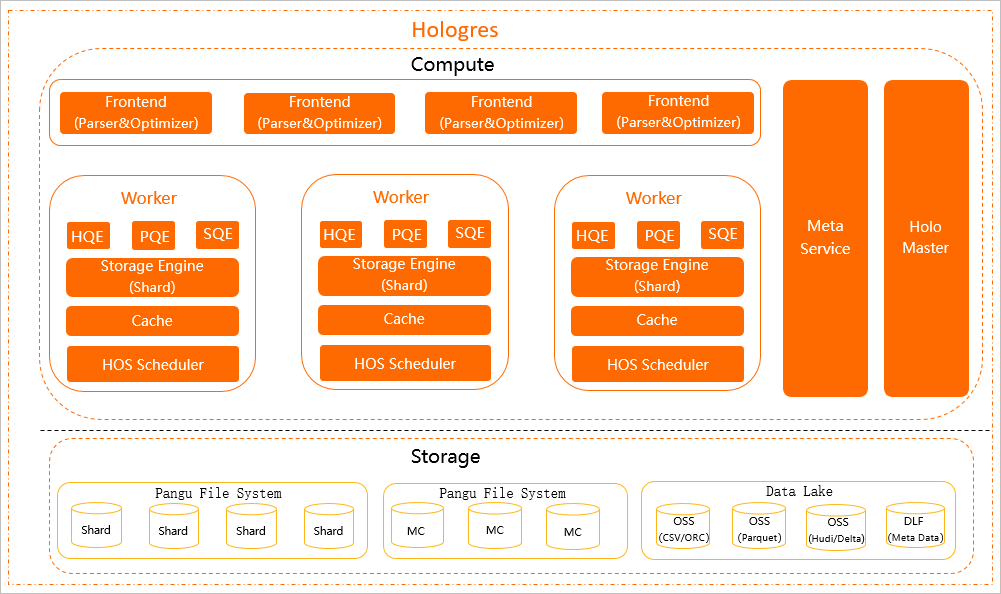
Computing layer
Frontend (FE)
The FE authenticates, parses, and optimizes SQL statements. A Hologres instance runs multiple FEs. Hologres is compatible with PostgreSQL 11, so you can use standard PostgreSQL syntax and connect with PostgreSQL-compatible development tools and Business Intelligence (BI) tools without additional configuration.
HoloWorker
HoloWorkers schedule and execute user queries. Each HoloWorker contains a Query Engine (QE), Storage Engine (SE), Cache, and HOS Scheduler.
*Query Engine (QE)*
HoloWorker supports three query engines, each serving a different workload:
| Engine | Purpose | Key characteristics |
|---|---|---|
| Hologres Query Engine (HQE) | Primary engine for analytical queries | Scalable MPP architecture with vectorization operators; maximizes CPU utilization for high query performance |
| PostgreSQL Query Engine (PQE) | PostgreSQL compatibility layer | Supports PostGIS and UDFs written in PL/Java, PL/SQL, or PL/Python; handles operations not yet supported by HQE |
| Seahawks Query Engine (SQE) | MaxCompute integration | Connects to MaxCompute without data migration; supports hash tables, range-clustered tables, and interactive analysis of PB-level batch data |
The long-term goal is to integrate all PQE functionality into HQE.
*Storage Engine (SE)*
The SE manages data and handles all create, read, update, and delete (CRUD) operations.
*Cache*
The Cache component caches query results to improve query performance.
*HOS Scheduler*
HOS Scheduler provides lightweight scheduling capabilities.
Meta Service
Meta Service manages metadata—including table structures and data distribution across the SE—and provides it to FEs.
Holo Master
Hologres runs natively on Kubernetes. If a worker node fails, Kubernetes provisions a replacement within a short period, maintaining node-level availability. Holo Master monitors component health within each worker node and restarts any component that enters an abnormal state, reducing service interruption.
Storage layer
Hologres data is stored in Pangu, Alibaba's distributed file system. The storage layer also integrates with external data sources:
MaxCompute: Hologres reads MaxCompute data stored in Pangu. Pangu enables efficient mutual access between Hologres and MaxCompute without data movement.
Object Storage Service (OSS) and Data Lake Formation (DLF): Hologres queries data in OSS and DLF to accelerate analysis in data lakes. Supported formats include CSV, ORC, Parquet, Hudi, Delta, and Meta Data. Hologres can also write data to OSS to reduce storage costs.