Data lineage answers three questions about your streaming data: where did it come from, where is it going, and how was it transformed along the way? In Realtime Compute for Apache Flink, the data lineage feature maps the relationships between SQL deployments and the metadata they read from or write to — at both the table level and the field level.
Use data lineage to:
Trace the source and processing history of data in a deployment
Identify the root cause of data errors without manually inspecting each stage
Assess which deployments are affected when a table schema or field changes
Spot unused services and optimize data processing pipelines
How it works
Data lineage is represented as a graph of nodes and edges.
| Element | Description |
|---|---|
| Node | An abstraction of a catalog, database, table, field, or deployment. Nodes fall into two types: data nodes (metadata such as catalogs, databases, tables, and fields) and deployment nodes (SQL deployments). |
| Edge | A directional relationship between nodes. If a deployment node points to a data node, the deployment produces the data of that data node. If a data node points to a deployment node, the deployment consumes the data of that data node. |
Edges encode the following relationships:
Dependencies between tables
Affiliation relationships between tables and their fields
Production and consumption relationships between deployments and data nodes
The following figure shows how nodes and edges are structured in a lineage graph.

Limitations
Data lineage is scoped to a single namespace. Cross-namespace lineage is not supported.
To view lineage from the metadata perspective, you must use a catalog. The deployment perspective does not require a catalog.
Only SQL deployments support data lineage. Other deployment types cannot be searched or viewed.
Only SQL deployments that have been started at least once have lineage data. The most recent lineage is retained after a deployment is canceled.
The following operations are tracked:
QueryOperation,SinkModifyOperation, andCreateTableAsTableOperation. Filter operations, JOIN operations, and theCREATE DATABASE ASstatement are not tracked.
View lineage from the deployment perspective
The lineage graph centers on a deployment and shows three layers by default: the upstream table, the central deployment, and the downstream table. To trace additional layers, click the plus sign on the left side of an upstream table or on the right side of a downstream table.
Prerequisites: A SQL deployment that has been started at least once.
View table-level or field-level lineage
Log on to the Realtime Compute for Apache Flink console.
Find the workspace you want to manage and click Console in the Actions column.
In the left-side navigation pane, choose O&M > Deployments. Find the deployment and click its name.
Click the Lineage tab, then select a view:
Table Level — shows node type, connector type, catalog name, database name, destination table name, source table name, and deployment information (ID, creation time, creator, last modified time, and last modified user).
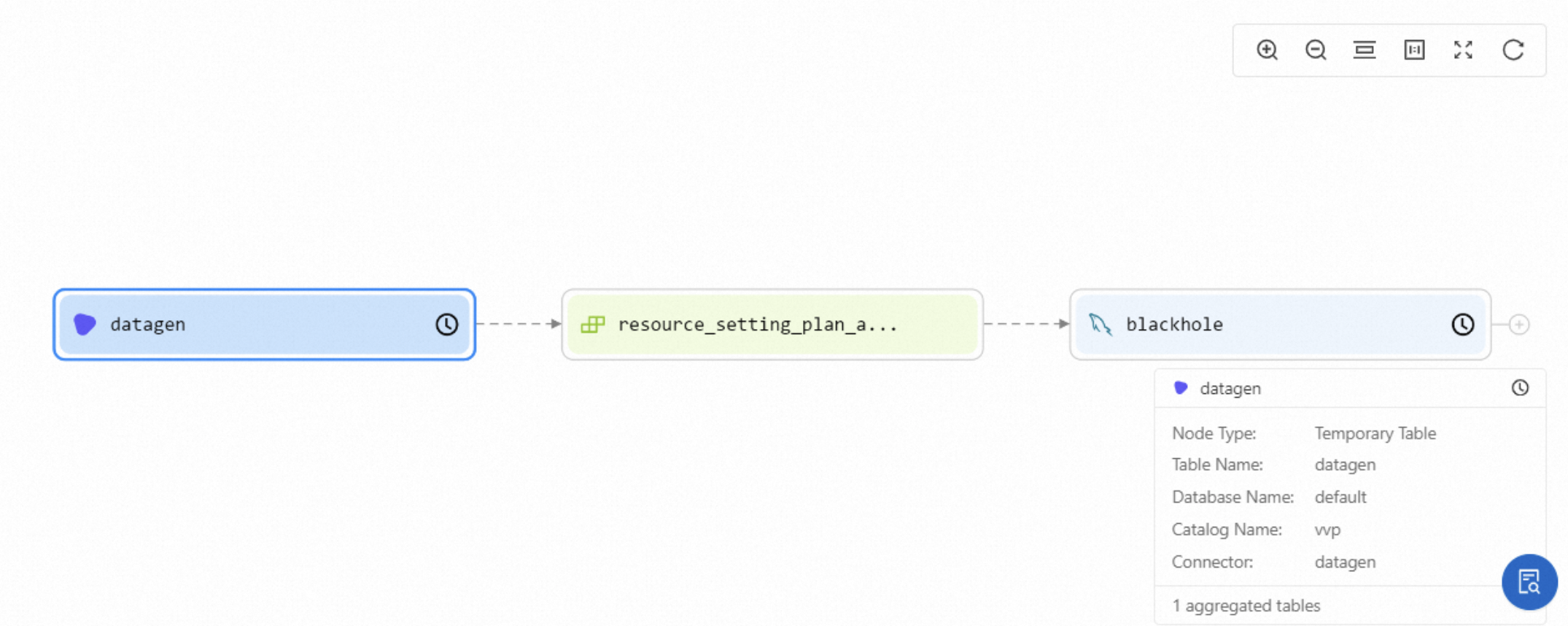
Column Level — shows table field names and types, database names, catalog names, connector types, and deployment information.
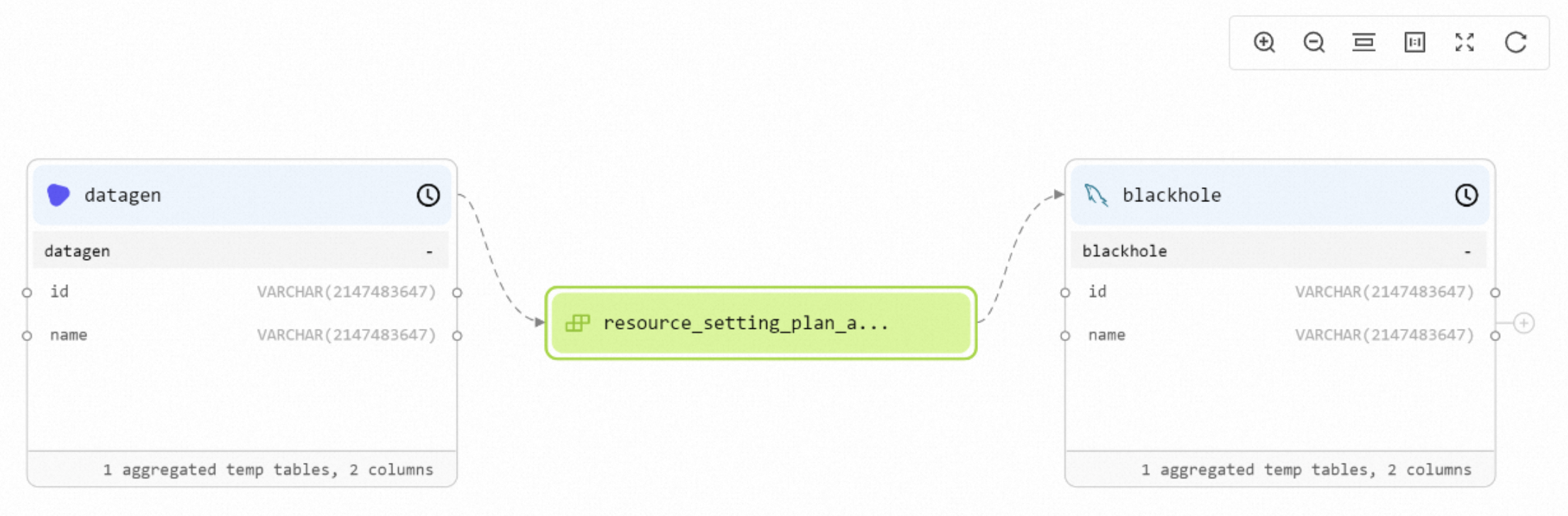
View lineage from the metadata perspective
Starting from a catalog table gives you the reverse view: instead of asking "what does this deployment touch?", you ask "what deployments reference this table or field?". This is useful for impact analysis — when a table schema or field changes, you can quickly identify all affected deployments.
Prerequisites: A catalog configured in Realtime Compute for Apache Flink.
If a table is referenced by many deployments, the lineage graph can become dense. Zoom in or out to navigate the graph. Turn on Auto focus clicked node to automatically center the graph on any deployment or table you click.
View table-level or field-level lineage
Log on to the Realtime Compute for Apache Flink console.
Find the workspace you want to manage and click Console in the Actions column.
In the left-side navigation pane, click Catalogs. On the Catalogs page, double-click the name of a table under a specific database of a catalog.
On the Lineage tab, select a view:
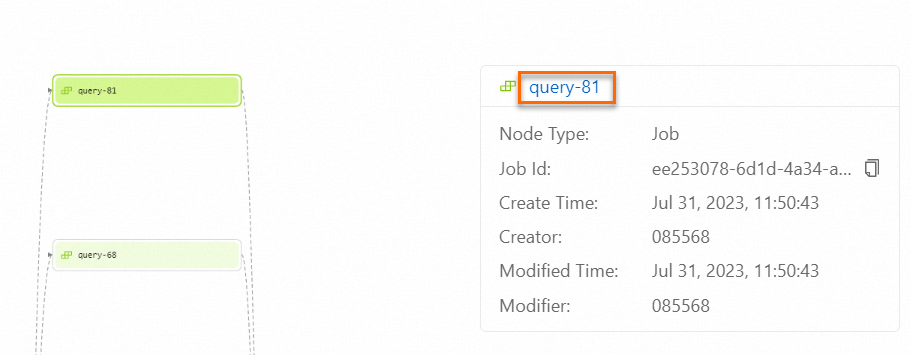
Table Level — shows all deployments that reference the table. Double-click a deployment node to view its ID, creation information, and modification information. Click the deployment name to go to the Deployments page for that deployment.
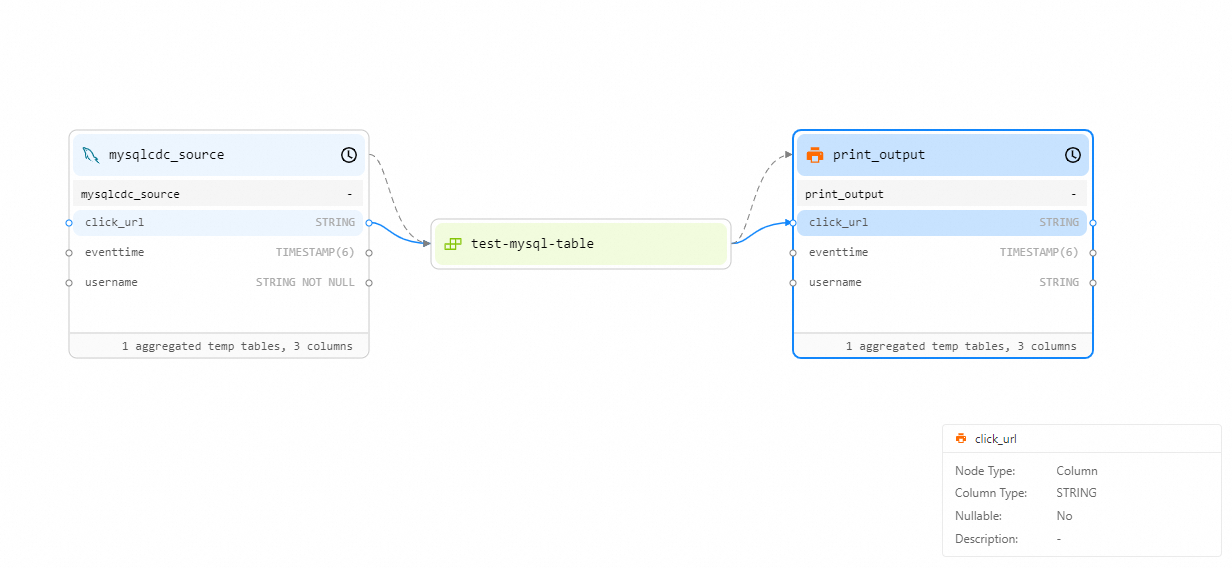
Column Level — click a field to highlight the deployments and tables that reference it. Associated fields are connected by blue solid lines. Use this view to assess impact when a field is deleted, renamed, or its attributes change.
Search by node or field name
When the lineage graph is large, search lets you jump directly to any node or field instead of navigating the full graph.
On the Lineage tab of the Deployments page, enter a node or field name in the search box and press Enter. The central node shifts from the deployment to the specified node or field, and the node or field changes color.
Field search is available only on the Column Level tab.
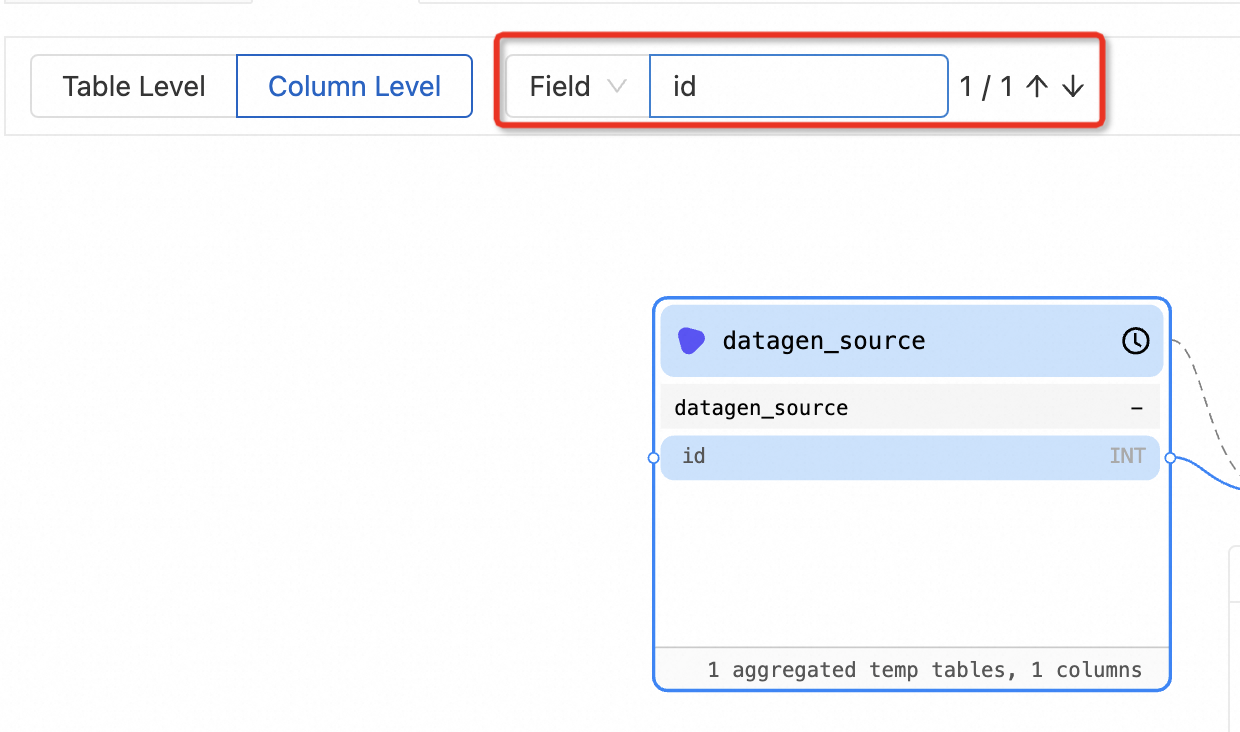
Double-click the node or field name to view its lineage.