Writing Flink SQL for MySQL-to-Hologres synchronization from scratch requires understanding CDAS and CTAS statement syntax, handling schema changes manually, and managing server IDs for CDC connectors. Data synchronization templates generate this SQL automatically — you select the source and destination catalogs, choose a synchronization method, and the template produces a ready-to-deploy Flink SQL file that covers full data, incremental data, and schema changes.
Synchronization methods
Two methods are available. Choose based on how your source data is structured:
| Method | Use when | SQL generated |
|---|---|---|
| Multi-database multi-table synchronization | Synchronizing one or more tables from one or more databases to a single destination database | CREATE DATABASE AS (CDAS) |
| Sharded-data merging | Merging multiple sharded tables with a similar schema into one destination table | CREATE TABLE AS (CTAS) |
Both methods use Flink Change Data Capture (CDC) connectors to automatically synchronize full data, incremental data, and schema changes (such as added columns) from each source table to the destination.
Limitations
Data synchronization templates only support MySQL as the source and Hologres as the destination.
Prerequisites
Before you begin, ensure that you have:
A MySQL catalog. If none exists, create one — see Manage MySQL catalogs
A Hologres catalog. If none exists, create one — see Manage Hologres Catalog
Access to a Realtime Compute for Apache Flink workspace
Table creation behavior: Realtime Compute for Apache Flink automatically creates the destination table in Hologres. If the table already exists, data is synchronized based on the destination database and table you select during plan creation.
Data type changes: Hologres does not allow changing column data types. If a source field's data type differs from the existing Hologres table, the write fails. Change the column data type and re-synchronize.
Default naming: The template creates the destination database and table with the same names as the source catalog, synchronized to the public schema by default. To change the database name, table name, or schema, use SQL statements instead. See CREATE TABLE AS (CTAS) and CREATE DATABASE AS (CDAS).
Synchronize data using a template
Log on to the Realtime Compute for Apache Flink console.
Find the workspace and click Console in the Actions column.
In the left navigation menu, click Development > ETL. Click the
 icon and select New Draft with Template.
icon and select New Draft with Template.In the New Draft dialog box, click the Flink CDC tab. Select the Data Synchronization from MySQL to Hologres card, and click Next.
Configure the source and sink: Click Next.
Category Parameter Description Source MySQL Catalog Select an existing MySQL catalog. If none exists, click Create Catalog. See Manage MySQL catalogs. Source MySQL server-id Enter a unique ID for each MySQL database client. Valid values: 5400–6400. You can also specify a range (for example, 5400-5408). If parallel reading is enabled in incremental reading mode, specify a range to assign a unique server ID to each parallel thread.ImportantDo not use the same server-id for different deployments or services that access the database.
Sink Hologres Catalog Select an existing Hologres catalog. If none exists, click Create Catalog. See Manage Hologres Catalog. 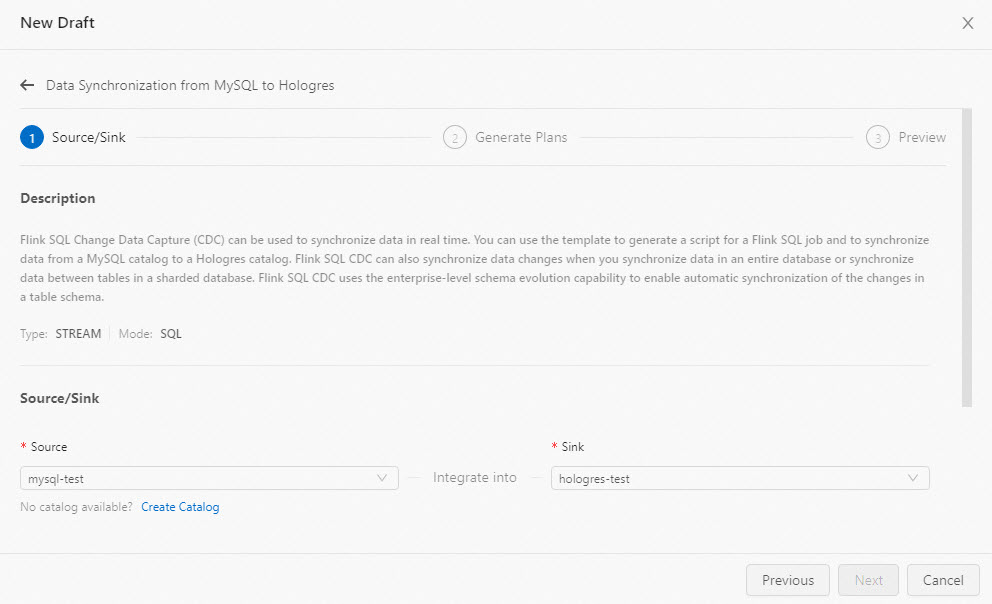
Create a plan. Follow the steps for your chosen synchronization method:
Multi-database multi-table synchronization
On the To Single Database tab, select the source database and table.
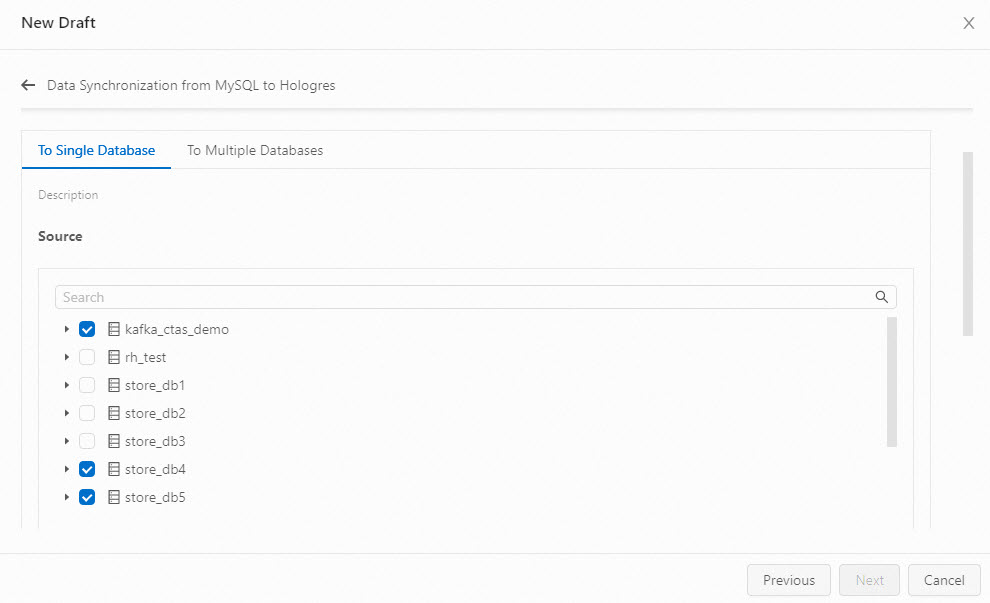
Click Save Plan. The plan appears in the plan list.
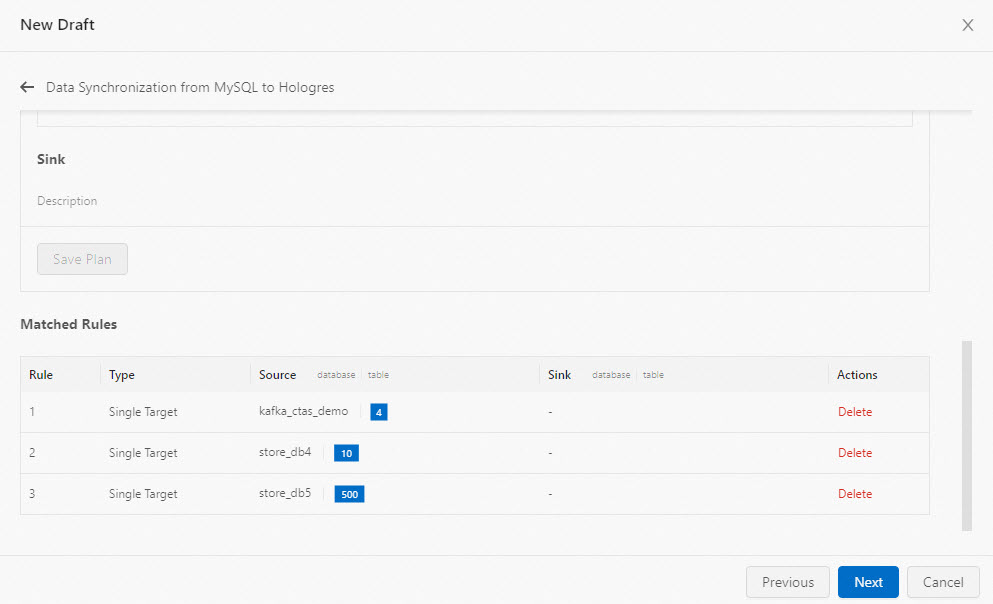 Note
NoteThe template creates a database and table in the destination catalog with the same names as the source. Both are synchronized to the
publicschema by default. To customize the database name, table name, or schema, use SQL statements instead. See CREATE TABLE AS (CTAS) and CREATE DATABASE AS (CDAS).Click Next.
Review the generated SQL. You can modify Name, Location, or Engine Version based on your requirements.
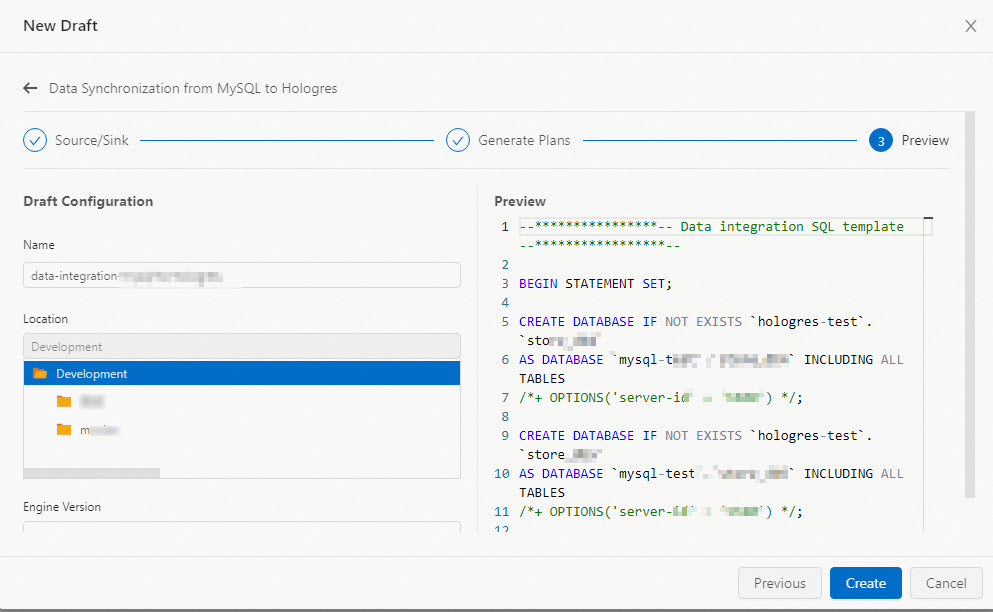
Sharded-data merging
On the To Multiple Databases tab, select the source databases and tables, or enter the destination database and table names.
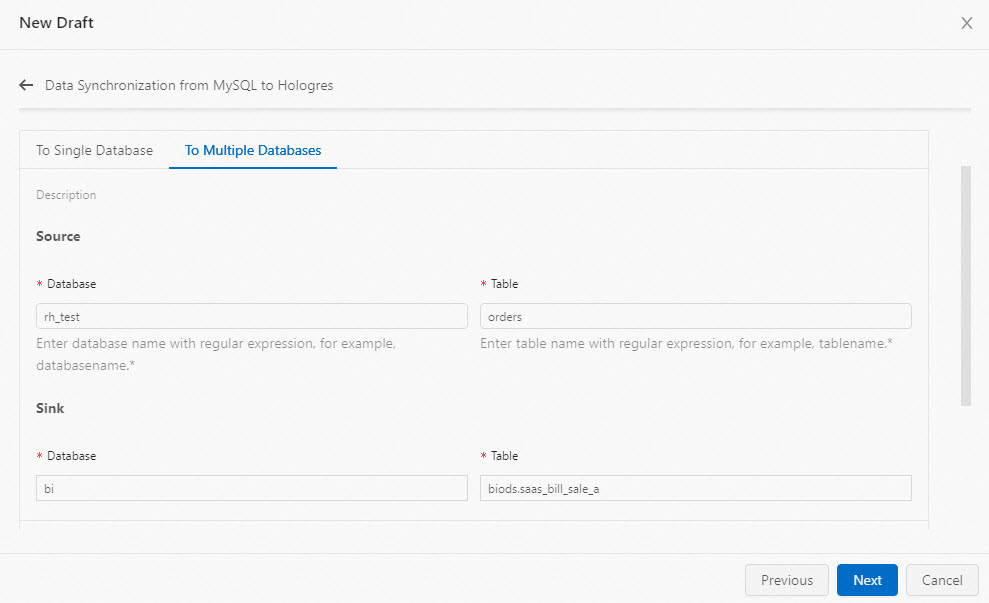 We recommend that you use regular expressions to specify the source databases and source tables.
We recommend that you use regular expressions to specify the source databases and source tables.Click Save Plan. The plan appears in the plan list.
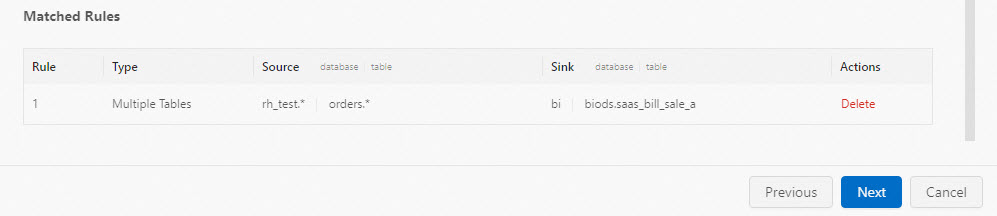 You can create multiple plans — for multi-database multi-table synchronization and sharded-data merging — within a single draft.
You can create multiple plans — for multi-database multi-table synchronization and sharded-data merging — within a single draft. 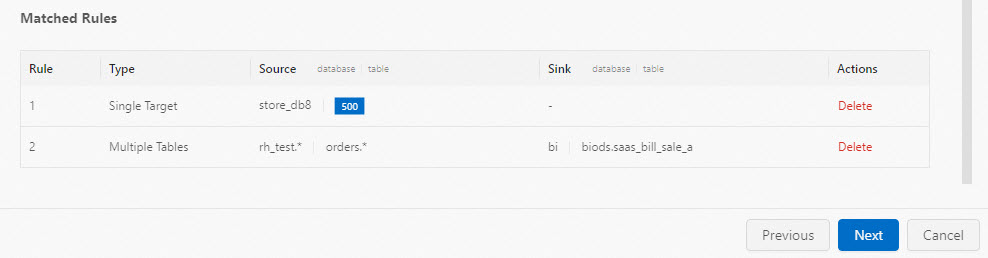
Click Next.
Review the generated SQL. You can modify Name, Location, or Engine Version based on your requirements.
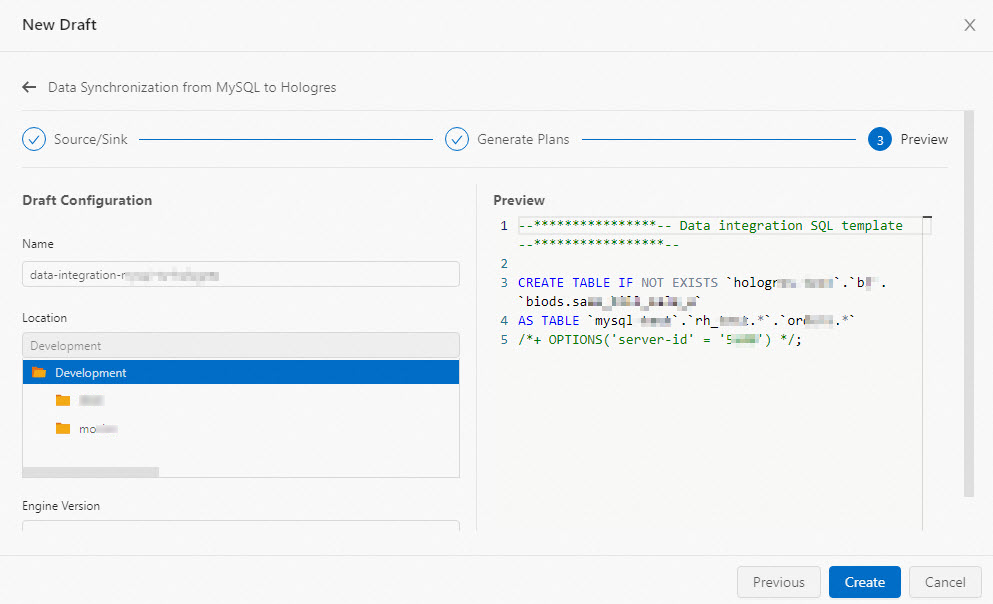
Click Create. You are redirected to the SQL Editor page. From here, the workflow is the same as for a standard deployment. See Job development map and Start a job deployment.
What's next
To customize the generated SQL with advanced options such as schema mapping or custom table names, see CREATE TABLE AS (CTAS) and CREATE DATABASE AS (CDAS).
To start the job after creating the deployment, see Start a job deployment.
For more information about Hologres result tables, see Create a Hologres result table.