Fully Managed Flink includes built-in code templates covering common Flink SQL patterns — from basic data definition language (DDL) and window aggregations to joins, deduplication, and complex event processing (CEP). Each template provides working SQL with inline comments, so you can adapt it to your business logic without starting from scratch.
A job cannot be deployed if the SQL script does not include an INSERT INTO statement. Make sure your final script contains at least one INSERT INTO before deploying.
Limits
Code templates require real-time computing engine version vvr-4.0.12-flink-1.13 or later.
Supported templates
The following table lists all available templates and their intended use cases. For the most up-to-date list, refer to the console.
| Category | Template | Use case |
|---|---|---|
| Basic templates | Create Table | Create a persistent table using a DDL statement and save it to a catalog. |
| Basic templates | Create Temporary Table | Create a table scoped to the current session or SQL script. |
| Basic templates | Create Temporary View | Reuse a subquery, organize long queries, or simplify development by wrapping logic in a named view. |
| Basic templates | INSERT INTO | Write query results to a table in an external storage system for downstream consumption. |
| Basic templates | STATEMENT SET | Write query results to two or more downstream external systems in a single job. |
| Basic templates | Watermark | Handle out-of-order data by defining a watermark on an existing field and marking it as a time attribute. See Event time and watermarks for background. |
| Aggregation and analysis | GROUP BY | Aggregate and analyze streaming data in real time using SQL GROUP BY. |
| Aggregation and analysis | Tumbling window aggregation | Group time series data into fixed, non-overlapping windows and aggregate within each window. |
| Aggregation and analysis | Sliding window aggregation | Slide a window over data at a specified interval to maintain a rolling aggregate. |
| Aggregation and analysis | Cumulative window aggregation | Get intermediate aggregation results before the window closes — for example, view the latest result every minute within an hourly window. Note
Cumulative window aggregation does not support change data capture (CDC). Using it with CDC sources causes a syntax validation error: |
| Aggregation and analysis | Session window aggregation | Collect real-time statistics on user activity during an active session, where the window closes after a period of inactivity. |
| Aggregation and analysis | OVER window aggregation | Run statistical analysis on each row within a sliding range of preceding rows. |
| Aggregation and analysis | Cascading window aggregation | Aggregate the same stream across multiple time granularities simultaneously — for example, 1 min, 5 min, 30 min, and 1 hour. |
| Deduplication template | Deduplication | Remove duplicate records from a data stream using Flink SQL deduplication syntax. |
| Top-N templates | Top-N | Rank records and retrieve the top or bottom N results across the entire stream. |
| Top-N templates | Window Top-N | Rank records and retrieve the top or bottom N results within a specific time window. |
| CEP template | Pattern detection (CEP) | Search for sequences of events matching a defined pattern using the MATCH_RECOGNIZE syntax. |
| Join templates | Regular join | Join data streams and query the combined result set. |
| Join templates | Interval join | Join records from two streams where the timestamps fall within a specified time range. |
| Join templates | Temporal table join | Join each stream record with the version of a table row that was valid at the time of the event. |
| Join templates | Dimension table join | Enrich streaming data by joining it with a static dimension table. |
Create a job from a template
The following steps use the Create Table template as an example. The process is the same for all other templates.
Prerequisites
Before you begin, ensure that you have:
-
Access to a Fully Managed Flink workspace
-
A workspace running real-time computing engine version vvr-4.0.12-flink-1.13 or later
Open a template and create a job
-
Log on to the Real-time Compute console.
-
In the Actions column for the workspace you want to use, click Console.
-
On the Data Studio > ETL page, click New.
-
On the SQL Basic Template tab, double-click the template you want to use. Alternatively, select the template and click Next in the lower-right corner.
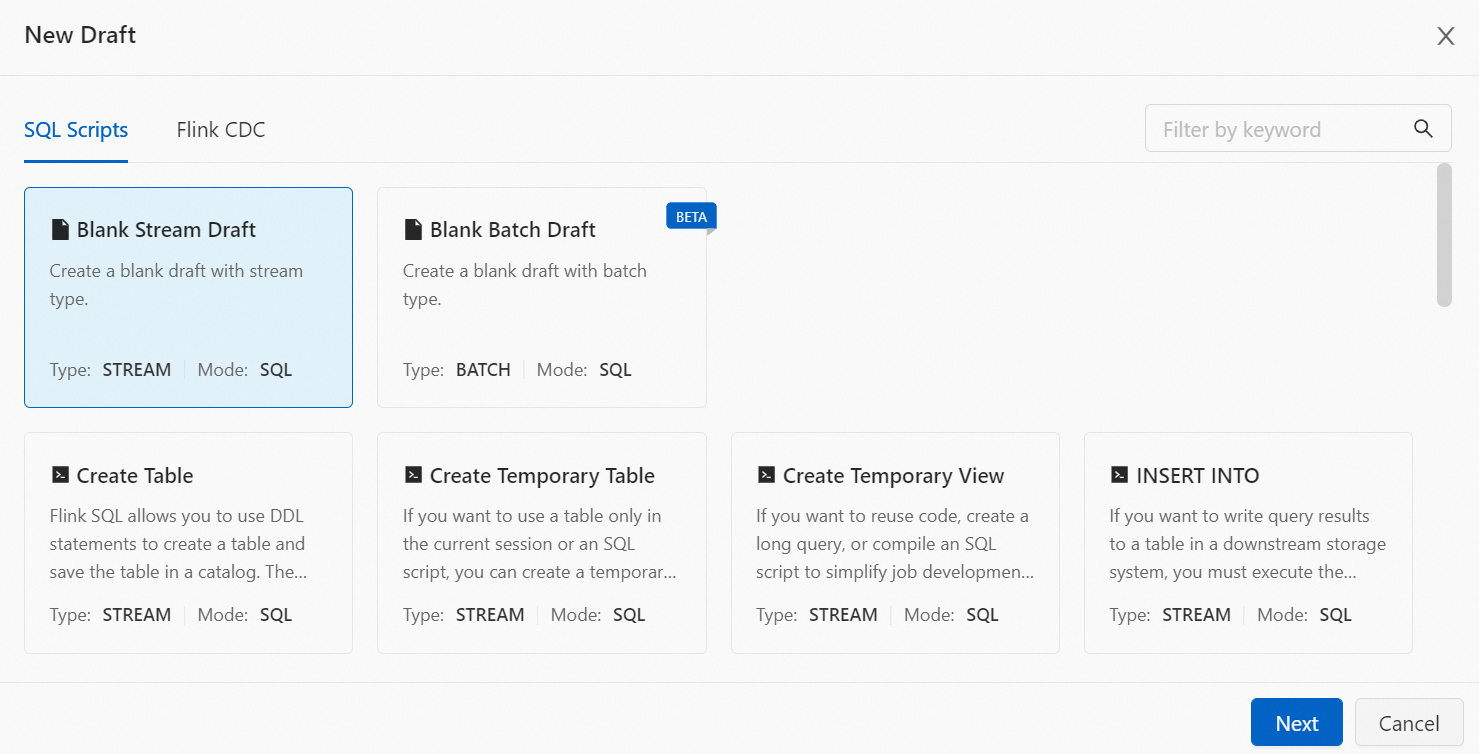
-
Optionally, modify the File Name, Storage Location, Engine Version, and SQL code to fit your requirements.
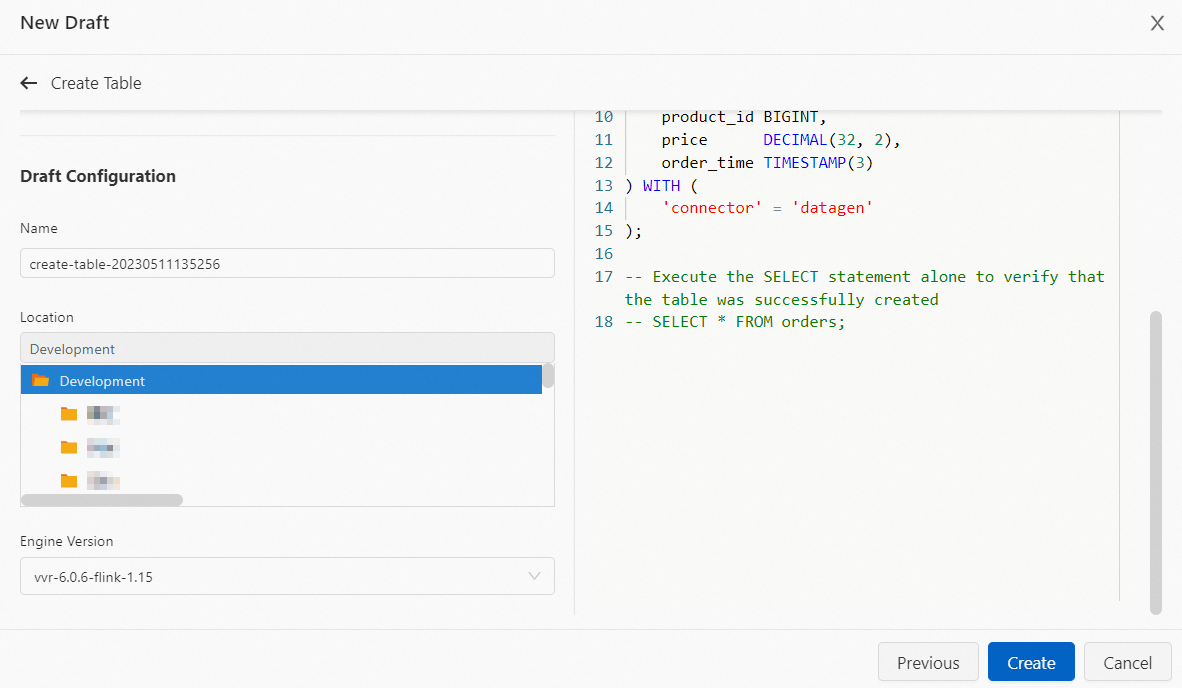
-
Click Create.
What's next
After creating the job, follow the standard job development workflow to configure, deploy, and run it. See Job development map.