This topic describes how to use Model Studio's model services for data analysis.
Background information
Model Studio is a one-stop platform for AI developers and business teams to build applications that use large language models (LLMs). It deeply integrates the real-time computing capabilities of Realtime Compute for Apache Flink. You can quickly invoke the LLM capabilities of Model Studio and combine them with Flink real-time data processing pipelines to significantly shorten the process from data ingestion to intelligent decision-making. The following sections describe the use cases of two core models:
chat/completions model A chat/completions model is an LLM based on dialogue generation and text understanding. It is widely used in scenarios such as sentiment analysis, intent recognition, and question-answering systems.
Sentiment analysis: Performs real-time sentiment classification of your business's social media comments to identify user sentiment as positive, negative, or neutral.
Intelligent customer service: Provides natural language interactions for intelligent customer service systems, powered by dialogue generation capabilities.
Content moderation: Automatically detects sensitive content or policy violations in text for more efficient content security audits.
embedding model An embedding model converts text into high-dimensional vector representations. Common applications include semantic search, recommendation systems, and knowledge graph construction.
Semantic search: Enables relevance-based semantic search by vectorizing product descriptions or user queries.
Recommendation systems: Uses text vectorization to discover associations between user interests and product features, improving recommendation accuracy.
Knowledge graph: Converts unstructured text into a vector format to simplify subsequent knowledge extraction and relationship modeling.
Prerequisites
You have activated a Flink workspace. For more information, see Activate Realtime Compute for Apache Flink.
You have activated a Model Studio workspace and established a network connection to the development console of Realtime Compute for Apache Flink. To access Model Studio over a VPC, see Access the API of a model or application in Model Studio over a private network.
If you access Model Studio by using a domain name, you must register it in the development console of Realtime Compute for Apache Flink. For more information, see Manage domain names.
Limitations
This feature is supported only in Ververica Runtime (VVR) 11.1 and later.
Step 1: Register a Model Studio model
For more information, see Configure a model.
Chat/completions model
The following sample SQL code shows how to register the qwen-turbo model:
CREATE MODEL ai_analyze_sentiment
INPUT (`input` STRING)
OUTPUT (`content` STRING)
WITH (
'provider'='bailian',
'endpoint'='<base_url>/compatible-mode/v1/chat/completions', -- The endpoint for chat/completions model tasks.
'api-key' = '<YOUR KEY>',
'model'='qwen-turbo', -- The Qwen-turbo model.
'system-prompt' = 'Classify the text below into one of the following labels: [positive, negative, neutral, mixed]. Output only the label.'
);Replace the <base_url> part of the endpoint parameter value depending on your access method:
For Internet access to Model Studio, replace
<base_url>withhttps://dashscope-intl.aliyuncs.com.For private network access to Model Studio over a VPC, replace
<base_url>withhttps://vpc-ap-southeast-1.dashscope.aliyuncs.com.NoteThe
endpointparameter supports only the HTTPS protocol.
Embedding model
The following sample SQL code shows how to register the text-embedding-v3 model:
CREATE MODEL embedding_model
INPUT (`input` STRING)
OUTPUT (`embeddings` ARRAY<FLOAT>)
WITH (
'provider'='bailian',
'endpoint'='https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings', -- The endpoint for embedding model tasks.
'api-key' = '<YOUR KEY>',
'model'='text-embedding-v3' -- The text-embedding-v3 model.
);Step 2: Create a job
Create a draft for an SQL streaming job. For more information, see Flink SQL jobs.
Step 3: Write an SQL job for LLM analysis
Chat/completions model
Use the ML_PREDICT AI function to call the registered ai_analyze_sentiment model and perform sentiment analysis on movie reviews.
The throughput of the Flink operator associated with the ML_PREDICT statement is subject to rate limiting by Model Studio. When the request limit to Model Studio is reached, backpressure occurs in the Flink job, and the ML_PREDICT operator becomes the bottleneck. Severe rate limiting can trigger a timeout error for the related operator, which causes the job to restart. You can check the rate limiting conditions for different models in Model Studio. For more information, see Limits on QPS and tokens. You can also contact your business manager or a pre-sales and after-sales specialist to learn how to remove the limits.
Copy the following sample SQL to the SQL editor.
-- Create a temporary sink table.
CREATE TEMPORARY TABLE print_sink(
id BIGINT,
movie_name VARCHAR,
predict_label VARCHAR,
actual_label VARCHAR
) WITH (
'connector' = 'print', -- Use the print connector.
'logger' = 'true' -- Display the results in the console.
);
-- Create a temporary data view to construct test data.
-- | id | movie_name | comment | actual_label |
-- | 1 | Her Story | My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving. | POSITIVE |
-- | 2 | The Dumpling Queen | Unremarkable. | NEGATIVE |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment, actual_label)
AS VALUES (1, 'Her Story', 'My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.', 'positive'), (2, 'The Dumpling Queen', 'Unremarkable.', 'negative');
INSERT INTO print_sink
SELECT id, movie_name, content as predict_label, actual_label
FROM ML_PREDICT(
TABLE movie_comment,
MODEL ai_analyze_sentiment, -- The registered Qwen-turbo model.
DESCRIPTOR(user_comment)); Embedding model
Use the ML_PREDICT AI function to call the registered embedding_model model, generate embeddings for movie reviews, and then write the results to Milvus (public preview).
The throughput of the Flink operator associated with the ML_PREDICT statement is subject to rate limiting by Model Studio. When the request limit to Model Studio is reached, backpressure occurs in the Flink job, and the ML_PREDICT operator becomes the bottleneck. Severe rate limiting can trigger a timeout error for the related operator, which causes the job to restart. You can check the rate limiting conditions for different models in Model Studio. For more information, see Limits on QPS and tokens. You can also contact your business manager or a pre-sales and after-sales specialist to learn how to remove the limits.
Copy the following sample SQL to the SQL editor.
-- Create a temporary sink table named milvus_sink.
CREATE TEMPORARY TABLE milvus_sink
(
id STRING,
movie_name STRING,
user_comment STRING,
embeddings ARRAY<FLOAT>,
PRIMARY KEY (id) NOT ENFORCED
)
WITH (
'connector' = 'milvus',
'endpoint' = '<YOUR-ENDPOINT>',
'port' = '<YOUR-PORT>',
'userName' = '<YOUR-USERNAME>',
'password' = '<YOUR-PASSWORD>',
'databaseName' = 'default',
'collectionName' = 'movie-comment-embeddings'
);
-- Create a temporary data view to construct test data.
-- | id | movie_name | comment |
-- | 1 | Her Story |My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.|
-- | 2 | The Dumpling Queen | Unremarkable. |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment)
AS VALUES ('1', 'Her Story', 'My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.'), ('2', 'The Dumpling Queen', 'Unremarkable.');
INSERT INTO
milvus_sink
SELECT
id,
movie_name,
user_comment,
embeddings
FROM
ML_PREDICT (
TABLE movie_comment,
MODEL embedding_model, -- The registered text-embedding-v3 model.
DESCRIPTOR (user_comment)
);Step 4: Deploy and start the job
Deploy and start the job. For more information, see Flink SQL jobs.
Step 5: View the analysis results
Chat/completions model
Verify that the job status is FINISHED.
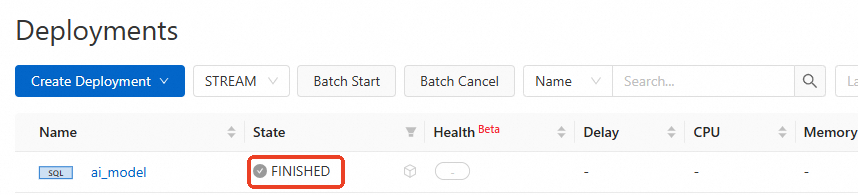
In the console, go to the Deployments page and click the name of the target job.
On the Logs tab, click the Task Managers subtab and select the current TaskManager.
Click Log and search for logs related to PrintSinkOutputWriter.
The model's predicted label
predict_labelmatches the actual labelactual_label.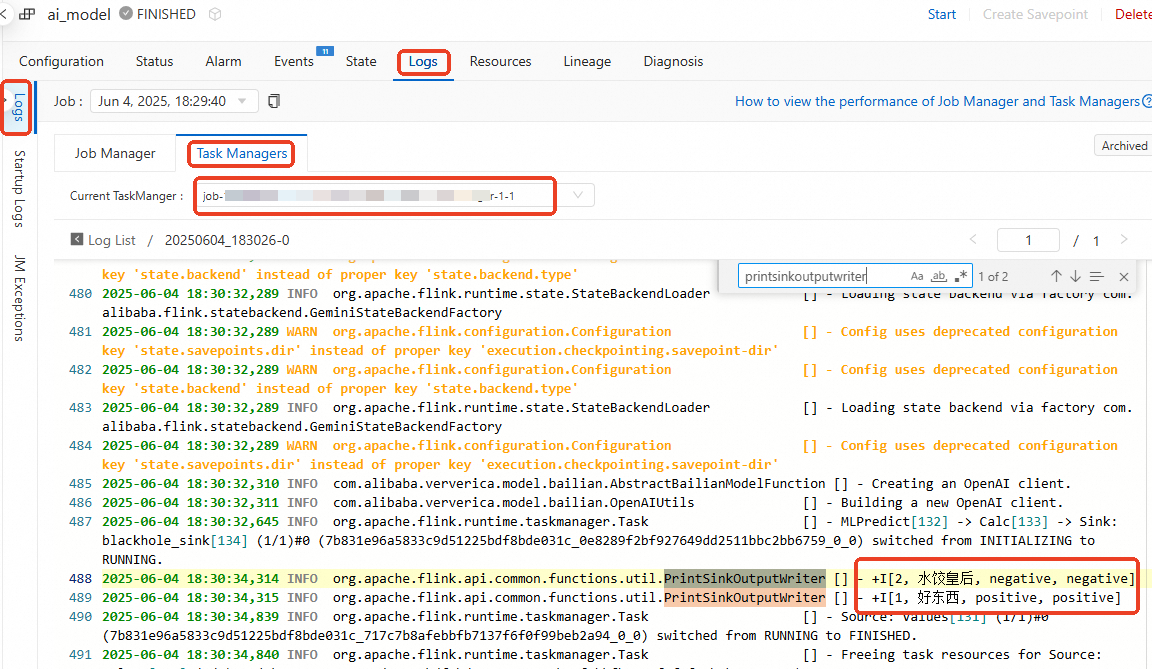
Related documents
Data definition language (DDL) statements for AI models: Configure a model
AI functions: ML_PREDICT
Vector search service: Milvus (public preview)