You can store HBase data in OSS-HDFS for DataServing clusters to separate compute from storage. Write-Ahead Logging (WAL) data remains in HDFS.
Background
OSS-HDFS is a cloud-native data lake storage service with unified metadata management, full HDFS API compatibility, and comprehensive POSIX support. It is well suited for big data and AI computing scenarios in data lake architectures. For more information, see What is OSS-HDFS?.
The following figure shows the architecture of HBase on OSS-HDFS.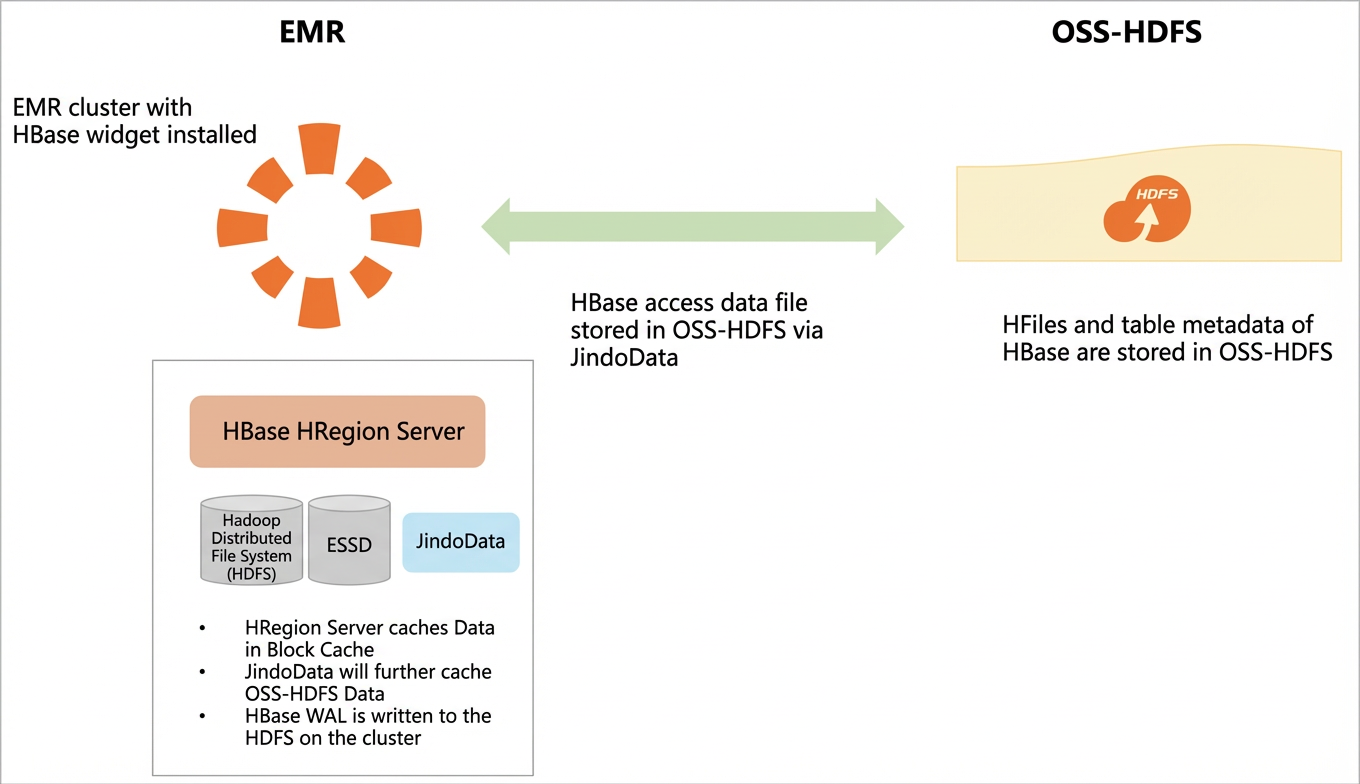
Limitations
Supported only on DataServing clusters running E-MapReduce 3.42 or later, or E-MapReduce 5.8.0 or later.
Procedure
-
Enable OSS-HDFS and grant the required access permissions. For detailed instructions, see Enable OSS-HDFS and grant access permissions.
-
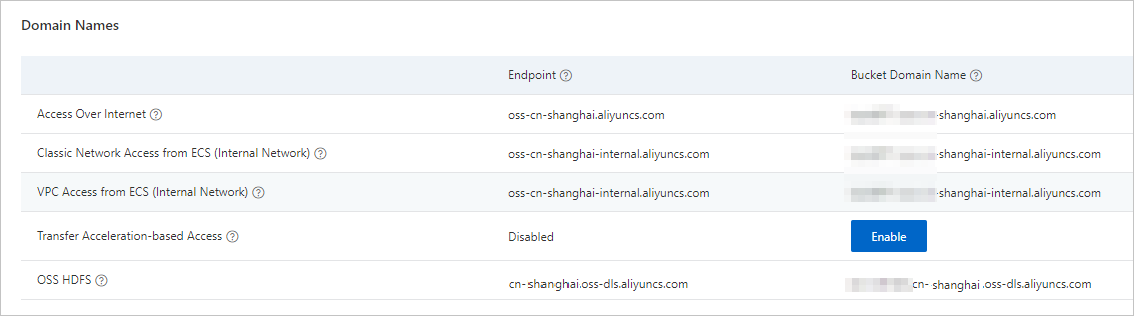
Get the OSS-HDFS service endpoint.
In the OSS console, go to the Overview page and copy the endpoint for the OSS-HDFS service. Use this endpoint as the path for the hbase.rootdir parameter when you create the E-MapReduce HBase cluster.
-
Use OSS-HDFS.
-
Create a DataServing cluster. For more information, see Create a cluster.
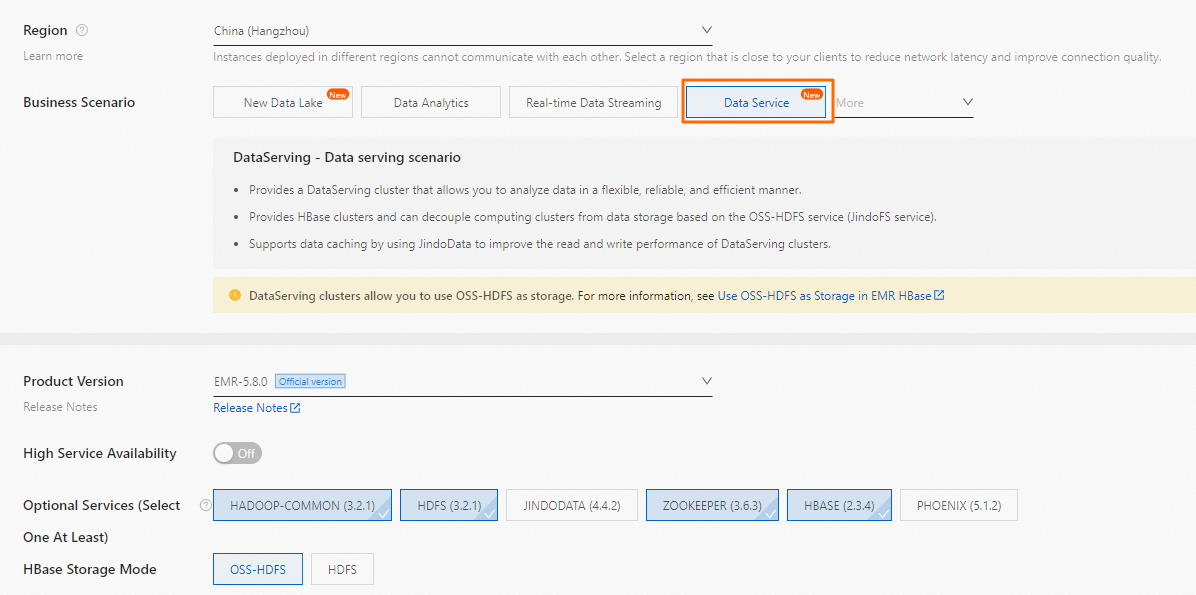 When you create the DataServing cluster, configure the following parameters:
When you create the DataServing cluster, configure the following parameters:-
Optional Services: Select all services except JindoData and Phoenix.
-
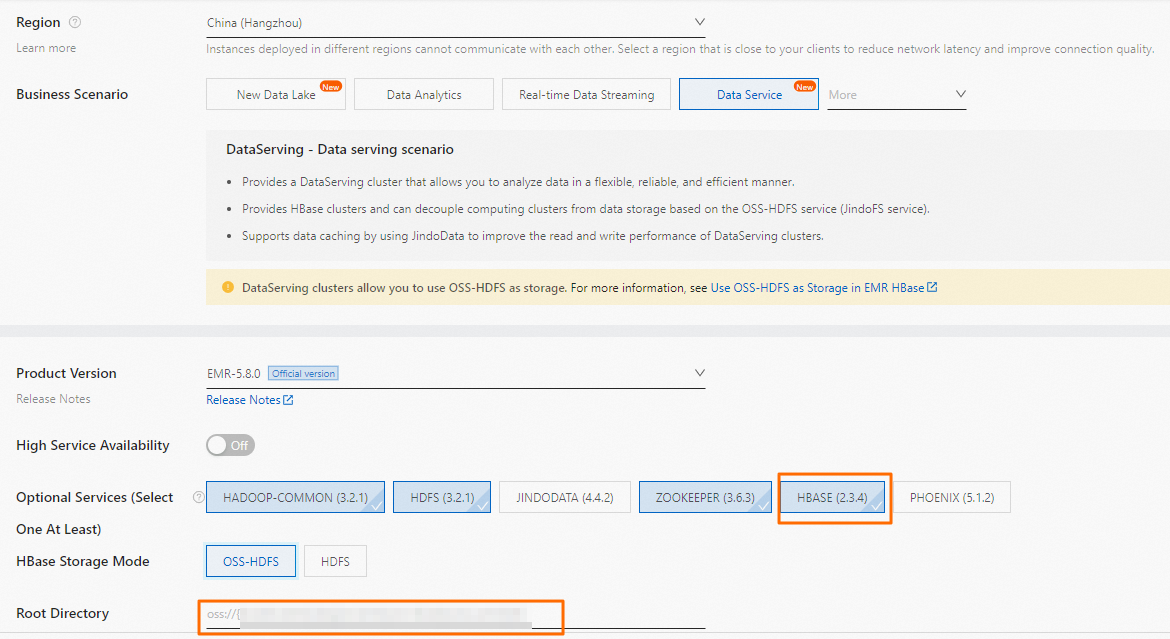
HBase Storage Mode: Select OSS-HDFS.
-
Root Directory: Specify an OSS bucket with the HDFS service enabled. Use the format oss://${OSS-HDFS_ENDPOINT}/${DIR}. For example, oss://test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase.
NoteReplace the following placeholders:
-
${OSS-HDFS_ENDPOINT}: The OSS-HDFS endpoint that you obtained in Step 2.
-
${DIR}: The root directory for HBase.
-
-
Create an HBase table.
-
Log on to the DataServing cluster. For more information, see Log on to a cluster.
-
Run the following command to start the HBase Shell:
hbase shell -
Run the following command to create a test table named
barwith a column family namedf:create 'bar','f'After creating the table, you can run the
listcommand to view your tables.Example output:
TABLE bar 1 row(s) Took 0.0138 seconds
-
-
Exit the HBase Shell and run the following command to verify the table data is stored in OSS-HDFS.
Syntax:
hadoop fs -ls oss://${OSS-HDFS_ENDPOINT}/${DIR}Example:
hadoop fs -ls oss://test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase/data/defaultSimilar output confirms that the directory for the HBase table has been created in OSS-HDFS:
Found 1 items drwxrwxrwx - hbase supergroup 0 2022-07-28 14:45 oss://test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase/data/default/bar
-
-
Optional: Terminate and restore a cluster.
Because OSS-HDFS separates compute from storage, you can terminate the original cluster and create a new one that reads the same data from the same OSS-HDFS directory.
Important-
The new cluster and the original cluster must use the same version of HBase. A version mismatch can cause unpredictable compatibility issues and may render the new cluster unusable.

-
Concurrent writes from multiple clusters can cause metadata or data inconsistencies, corrupt your data, and make the clusters unavailable.
-
Log on to the DataServing cluster. For more information, see Log on to a cluster.
-
Start the HBase Shell.
hbase shell -
Run the
flushcommand to write all in-memory data for your tables to HFile.flush 'bar' -
Run the
disablecommand on your tables to prevent new data writes.disable 'bar' -
Create a new cluster. Ensure it has the same HBase version as the original cluster and configure it to use the same OSS-HDFS directory as its storage backend.
The new cluster automatically restores data from OSS-HDFS and is ready for use.
-