MirrorMaker 2 (MM2) on Kafka Connect replicates data between Apache Kafka clusters—including topic data, consumer group offsets, access control lists (ACLs), and topic configuration. This document shows you how to run MM2 in Distributed mode on an E-MapReduce (EMR) cluster using three connectors: MirrorSourceConnector, MirrorCheckpointConnector, and MirrorHeartbeatConnector.
Use cases
-
Cross-region sync: Replicate data between clusters in different regions.
-
Disaster recovery: Keep a secondary cluster in sync with a primary cluster in a different data center. If the primary becomes unavailable, shift traffic to the secondary.
-
Data migration: Migrate data to a new cluster during cloud migrations, hybrid-cloud deployments, or cluster upgrades without interrupting consumers.
-
Data aggregation: Collect data from multiple Kafka sub-clusters into a single central cluster.
How it works
MM2 runs as a set of Kafka Connect connectors. Each connector handles a specific part of replication:
| Connector | Role |
|---|---|
| MirrorSourceConnector | Replicates topic data and configuration from the source cluster. Automatically detects new topics and partitions. |
| MirrorCheckpointConnector | Syncs consumer group offsets so that consumers can resume from the correct position on the destination cluster. |
| MirrorHeartbeatConnector | Publishes periodic heartbeats to verify the replication pipeline is active. |
All three connectors communicate with both the source and destination clusters via their respective bootstrap servers. MM2 also replicates ACLs and provides metrics for monitoring replication health. MM2 supports high-availability architectures that are horizontally scalable.
For the full specification, see KIP-382: MirrorMaker 2.0.
Prerequisites
Before you begin, make sure you have:
-
A source Kafka cluster (
emrsource) and a destination Kafka cluster (emrdest), each created with Kafka selected as an optional service. For instructions, see Create a cluster. -
Both clusters running EMR V3.42.0, of the DataFlow type, and in the same virtual private cloud (VPC).
-
The destination cluster running Kafka version 2.12_2.4.1 or later. Earlier versions are not supported.
-
Network connectivity between the source cluster and the Kafka Connect cluster on the destination side.
Step 1: Set up a Kafka Connect cluster on the destination
Create and scale a task node group
-
In the EMR console, go to the Nodes page of the
emrdestcluster. -
Click Create Node Group. In the Add machine group panel, set the following parameters:
Parameter Value Node Group Type TASK (Task Node Group) Node Group Name emr-task(or any name you prefer)Storage Configuration Select a data disk -
After the node group is created, find
emr-taskin the node group list and click Scale Out in the Actions column. -
In the dialog box, specify the number of instances to add and accept the Terms of Service, then click OK.
Note This example adds one instance. For a highly available Kafka Connect cluster, add at least two instances.
Verify that Kafka Connect is running
-
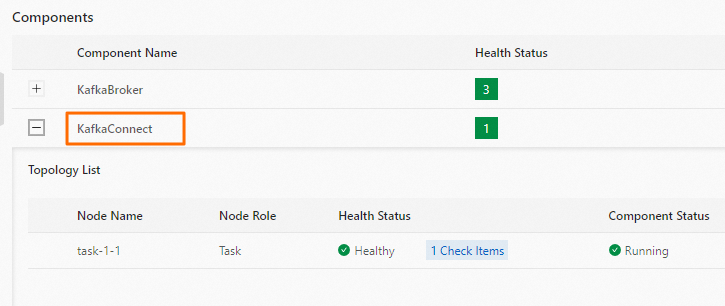
At the top of the cluster page, click Services.
-
In the Kafka details section, click Status.
-
In the Components section, verify that KafkaConnect shows a running status.
Check the REST API
-
Use SSH to log in to the
emrdestcluster. For instructions, see Log on to a cluster. -
Run the following command to verify the Kafka Connect REST API is reachable:
curl -X GET http://task-1-1:8083 | jq .A successful response looks like this:
{ "version": "2.4.1", "commit": "42ce056344c5625a", "kafka_cluster_id": "6Z7IdHW4SVO1Pbql4c****" }The
versionandkafka_cluster_idfields confirm that the REST API is running and connected to the Kafka cluster.
Step 2: Deploy the MM2 connectors
MM2 requires three connector configuration files. Create each file on the emrdest cluster (the same host where you run the curl commands), then submit them to the Kafka Connect REST API.
Prepare the configuration files
MirrorSourceConnector (mm2-source-connector.json)
{
"name": "mm2-source-connector",
"connector.class": "org.apache.kafka.connect.mirror.MirrorSourceConnector",
"clusters": "emrsource,emrdest",
"source.cluster.alias": "emrsource",
"target.cluster.alias": "emrdest",
"source.cluster.bootstrap.servers": "10.0.**.**:9092",
"target.cluster.bootstrap.servers": "core-1-1:9092;core-1-2:9092;core-1-3:9092",
"topics": "^foo.*",
"tasks.max": "4",
"key.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"value.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"replication.factor": "3",
"offset-syncs.topic.replication.factor": "3",
"sync.topic.acls.interval.seconds": "20",
"sync.topic.configs.interval.seconds": "20",
"refresh.topics.interval.seconds": "20",
"refresh.groups.interval.seconds": "20",
"consumer.group.id": "mm2-mirror-source-consumer-group",
"producer.enable.idempotence": "true",
"source.cluster.security.protocol": "PLAINTEXT",
"target.cluster.security.protocol": "PLAINTEXT"
}Key parameters:
| Parameter | Description |
|---|---|
source.cluster.bootstrap.servers |
The Kafka endpoint of emrsource. Make sure emrsource is reachable from the Kafka Connect cluster. |
topics |
A regex pattern for topics to replicate. ^foo.* replicates all topics whose names start with foo. |
tasks.max |
Maximum number of parallel replication tasks. Increase this value to improve throughput. |
replication.factor |
Replication factor for internal MM2 topics created in the destination cluster. |
offset-syncs.topic.replication.factor |
Replication factor for the internal offset-syncs topic. |
sync.topic.acls.interval.seconds |
How often (in seconds) MM2 syncs ACLs from source to destination. |
sync.topic.configs.interval.seconds |
How often MM2 syncs topic configuration changes. |
refresh.topics.interval.seconds |
How often MM2 checks for new topics matching the topics pattern. |
refresh.groups.interval.seconds |
How often MM2 checks for new consumer groups to track. |
MirrorCheckpointConnector (mm2-checkpoint-connector.json)
{
"name": "mm2-checkpoint-connector",
"connector.class": "org.apache.kafka.connect.mirror.MirrorCheckpointConnector",
"clusters": "emrsource,emrdest",
"source.cluster.alias": "emrsource",
"target.cluster.alias": "emrdest",
"source.cluster.bootstrap.servers": "10.0.**.**:9092",
"target.cluster.bootstrap.servers": "core-1-1:9092;core-1-2:9092;core-1-3:9092",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"value.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"replication.factor": "3",
"checkpoints.topic.replication.factor": "3",
"emit.checkpoints.interval.seconds": "20",
"source.cluster.security.protocol": "PLAINTEXT",
"target.cluster.security.protocol": "PLAINTEXT"
}MirrorHeartbeatConnector (mm2-heartbeat-connector.json)
{
"name": "mm2-heartbeat-connector",
"connector.class": "org.apache.kafka.connect.mirror.MirrorHeartbeatConnector",
"clusters": "emrsource,emrdest",
"source.cluster.alias": "emrsource",
"target.cluster.alias": "emrdest",
"source.cluster.bootstrap.servers": "10.0.**.**:9092",
"target.cluster.bootstrap.servers": "core-1-1:9092;core-1-2:9092;core-1-3:9092",
"tasks.max": "1",
"key.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"value.converter": "org.apache.kafka.connect.converters.ByteArrayConverter",
"replication.factor": "3",
"heartbeats.topic.replication.factor": "3",
"emit.heartbeats.interval.seconds": "20",
"source.cluster.security.protocol": "PLAINTEXT",
"target.cluster.security.protocol": "PLAINTEXT"
}Deploy MirrorSourceConnector
-
Submit the connector configuration:
curl -X PUT -H "Content-Type: application/json" \ --data @mm2-source-connector.json \ http://task-1-1:8083/connectors/mm2-source-connector/config -
Check the connector status:
curl -s task-1-1:8083/connectors/mm2-source-connector/status | jq .The connector is running when the
statefield showsRUNNINGfor both the connector and its tasks.
Deploy MirrorCheckpointConnector
-
Submit the connector configuration:
curl -X PUT -H "Content-Type: application/json" \ --data @mm2-checkpoint-connector.json \ http://task-1-1:8083/connectors/mm2-checkpoint-connector/config -
Check the connector status:
curl -s task-1-1:8083/connectors/mm2-checkpoint-connector/status | jq .The connector is running when the
statefield showsRUNNINGfor both the connector and its tasks.
Deploy MirrorHeartbeatConnector
-
Submit the connector configuration:
curl -X PUT -H "Content-Type: application/json" \ --data @mm2-heartbeat-connector.json \ http://task-1-1:8083/connectors/mm2-heartbeat-connector/config -
Check the connector status:
curl -s task-1-1:8083/connectors/mm2-heartbeat-connector/status | jq .The connector is running when the
statefield showsRUNNINGfor both the connector and its tasks.
Verify replication
List the topics in the emrdest cluster:
kafka-topics.sh --list --bootstrap-server core-1-1:9092All three connectors are working correctly when you see the following topics:
| Topic | Created by | Meaning |
|---|---|---|
Topics prefixed with emrsource.foo |
MirrorSourceConnector | Topics replicated from emrsource matching the ^foo.* pattern |
emrsource.checkpoints.internal |
MirrorCheckpointConnector | Stores consumer group offset mappings for failover |
heartbeats |
MirrorHeartbeatConnector | Tracks replication pipeline liveness |
If any of these topics are missing, check the corresponding connector's status output for errors and verify network connectivity between the clusters.
What's next
-
To manage all MM2 jobs using the driver program instead of Kafka Connect, see Deploy MM2 on a dedicated cluster to synchronize data across clusters.
-
To test MM2 without a full Kafka Connect cluster, you can run a single MirrorSourceConnector job directly.
-
For the full MM2 specification and advanced configuration options, see the Apache Kafka documentation.