This topic describes how to use Jindo DistCp in specific scenarios.
Prerequisites
- An E-MapReduce (EMR) cluster of a required version is created. For more information, see Create a cluster.
- Java Development Kit (JDK) 1.8 is installed.
- jindo-distcp-<version>.jar is downloaded based on your Hadoop version:
- jindo-distcp-3.0.0.jar for Hadoop 2.7 and later
- jindo-distcp-3.0.0.jar for Hadoop 3.X
Scenarios
- Scenario 1: What parameters are required for optimization if I import a large amount of HDFS data or a large number of HDFS files (millions or tens of millions) to OSS?
- Scenario 2: How do I verify data integrity after I use Jindo DistCp to import data to OSS?
- Scenario 3: What parameters are required to support a resumable upload if a DistCp task fails to import HDFS data to OSS?
- Scenario 4: What parameters are required to process the files that may be generated when I use Jindo DistCp to import HDFS data to OSS?
- Scenario 5: What parameters are required to specify the YARN queue where a Jindo DistCp task resides and the available bandwidth allocated to the task?
- Scenario 6: What parameters are required when I write data to OSS Cold Archive, Archive, or IA storage?
- Scenario 7: What parameters are required to accelerate file transfer based on the proportion of small files and specific file size?
- Scenario 8: What parameters are required if Amazon S3 is used as a data source?
- Scenario 9: What parameters are required if I want to copy files to OSS and compress the copied files in the LZO or GZ format?
- Scenario 10: What parameters are required if I want to copy the files that meet specific rules or the files in some sub-directories of the same parent directory?
- Scenario 11: What parameters are required if I want to merge the files that meet specific rules to reduce the number of files?
- Scenario 12: What parameters are required if I want to delete original files after a copy operation?
- Scenario 13: What do I do if I do not want to specify AccessKey pair and endpoint information of OSS in the CLI?
Scenario 1: What parameters are required for optimization if I import a large amount of HDFS data or a large number of HDFS files (millions or tens of millions) to OSS?
- You can read data from HDFS.
- The AccessKey ID, AccessKey secret, and endpoint of OSS are obtained. You can write data to a destination OSS bucket.
- The storage class of the OSS bucket is not Archive.
- You can submit MapReduce tasks.
- The JAR package of Jindo DistCp is downloaded.
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10enableBatch to true for optimization. Optimization command: hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 500 --enableBatchScenario 2: How do I verify data integrity after I use Jindo DistCp to import data to OSS?
- Jindo DistCp Counters
Check DistCp Counters in the counter information of a MapReduce task.
Distcp Counters Bytes Destination Copied=11010048000 Bytes Source Read=11010048000 Files Copied=1001 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0where:- Bytes Destination Copied specifies the size of the file that you copy to a destination directory, in bytes.
- Bytes Source Read specifies the size of the file that you read from the source directory, in bytes.
- Files Copied specifies the number of copied files.
- Jindo DistCp --diff
Run a command that ends with the
--diffparameter to compare the files in the source and destination directories. This command compares the names and sizes of the files in the source and destination directories, identifies the files that are not copied or failed to be copied, and generates a manifest file in the directory to which the command is submitted.Add--diffto the command described in Scenario 1. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diffIf all files are copied, the following information is returned:INFO distcp.JindoDistCp: distcp has been done completely
Scenario 3: What parameters are required to support a resumable upload if a DistCp task fails to import HDFS data to OSS?
- Add
--diffto check whether all files are copied.hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diffIf all the files are copied, the following information is returned.INFO distcp.JindoDistCp: distcp has been done completely. - If some files are not copied, a manifest file is generated. In this case, use
--copyFromManifestand--previousManifestto copy the remaining files. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --dest oss://destBucket/hourly_table --previousManifest=file:///opt/manifest-2020-04-17.gz --copyFromManifest --parallelism 20file:///opt/manifest-2020-04-17.gzis the path where the manifest file is stored.
Scenario 4: What parameters are required to process the files that may be generated when I use Jindo DistCp to import HDFS data to OSS?
The upstream process continues to generate files when I use Jindo DistCp to import HDFS data to OSS. For example, if new files are created every hour or every minute, configure the downstream process to receive the files based on the schedule. Jindo DistCp provides the update method.
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10 --update--update specifies the incremental copy mode. Before files are copied, JindoDistCp compares the names, sizes, and checksum of the files in sequence. If you do not want to compare the checksum of the files, add --disableChecksum to disable it.
Scenario 5: What parameters are required to specify the YARN queue where a Jindo DistCp task resides and the available bandwidth allocated to the task?
--queue: the name of the YARN queue.--bandwidth: the size of the specified bandwidth, in MB/s.
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --queue yarnqueue --bandwidth 6 --parallelism 10Scenario 6: What parameters are required when I write data to OSS Cold Archive, Archive, or IA storage?
- If the Cold Archive storage class is used, add
--policy coldArchiveto the command described in Scenario 1. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy coldArchive --parallelism 20Note The Cold Archive storage class is available only in some regions. For more information, see Overview. - If the Archive storage class is used, add
--policy archiveto the command described in Scenario 1. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy archive --parallelism 20 - If the Infrequent Access (IA) storage class is used, add
--policy iato the command described in Scenario 1. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy ia --parallelism 20
Scenario 7: What parameters are required to accelerate file transfer based on the proportion of small files and specific file sizes?
- A large number of small files and large data volume for a single large file
If most of the files that you want to copy are small files, but the data volume of a single large file is large, the general solution is to randomly allocate the files to be copied. In this case, if you do not optimize the job allocation plan, a few large files and many small files may be allocated to the same copy process. This results in a sub-optimal copy performance.
Add--enableDynamicPlanto the command described in Scenario 1 to enable the optimization. --enableDynamicPlan cannot be used with--enableBalancePlan. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableDynamicPlan --parallelism 10The following figure shows the data copy performance before and after the plan is optimized.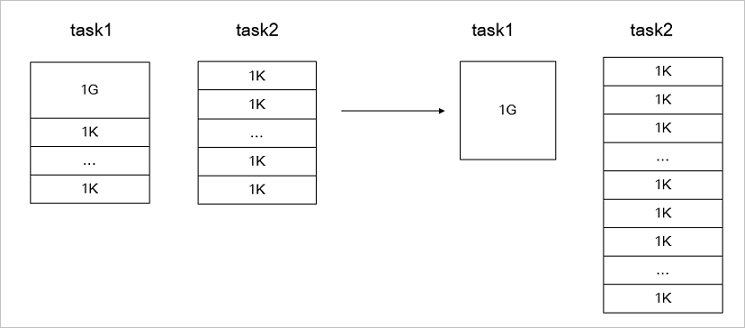
- No significant differences in sizes of files
If the sizes are not significantly different among the files that you want to copy, use
--enableBalancePlanto optimize the job allocation plan. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableBalancePlan --parallelism 10The following figure shows the data copy performance before and after the plan is optimized.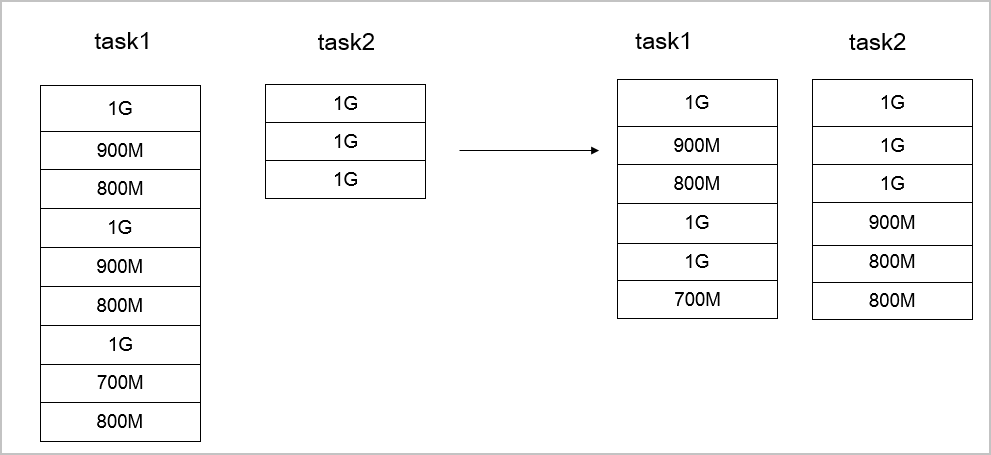
Scenario 8: What parameters are required if Amazon S3 is used as a data source?
--s3Key: the AccessKey ID for Amazon S3--s3Secret: the AccessKey secret for Amazon S3--s3EndPoint: the endpoint for Amazon S3
hadoop jar jindo-distcp-<version>.jar --src s3a://yourbucket/ --dest oss://destBucket/hourly_table --s3Key yourkey --s3Secret yoursecret --s3EndPoint s3-us-west-1.amazonaws.com --parallelism 10Scenario 9: What parameters are required if I want to copy files to OSS and compress the copied files in the LZO or GZ format?
You can use --outputCodec to compress the copied files in a format such as LZO or GZ to reduce the space that
is used to store the files.
--outputCodec to the command described in Scenario 1. Example: hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputCodec=gz --parallelism 10- none: Jindo DistCp does not compress copied files. If the files have been compressed, Jindo DistCp decompresses them.
- keep: Jindo DistCp copies files with no change to the compression.
Scenario 10: What parameters are required if I want to copy the files that meet specific rules or the files in some sub-directories of the same parent directory?
- If you want to copy the files that meet specific rules, add
--srcPatternto the command described in Scenario 1. Example:hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPattern .*\.log --parallelism 10--srcPattern: specifies a regular expression that filters files for the copy operation. - If you want to copy the files stored in some sub-directories of the same parent directory,
add
--srcPrefixesFileto the command described in Scenario 1.hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPrefixesFile file:///opt/folders.txt --parallelism 20--srcPrefixesFile: enables Jindo DistCp to copy the files in multiple folders under the same parent directory at a time.Content of the folders.txt file:hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-01 hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-02
Scenario 11: What parameters are required if I want to merge the files that meet specific rules to reduce the number of files?
--targetSize: the maximum size of the merged file, in MB--groupBy: the merging rule, which is a regular expression
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --targetSize=10 --groupBy='.*/([a-z]+).*.txt' --parallelism 20Scenario 12: What parameters are required if I want to delete original files after a copy operation?
--deleteOnSuccess to the command described in Scenario 1. Example: hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --deleteOnSuccess --parallelism 10Scenario 13: What do I do if I do not want to specify AccessKey pair and endpoint information of OSS in the CLI?
- If you want to save the AccessKey ID, AccessKey secret, and endpoint of OSS, save
the following information into the core-site.xml file:
<configuration> <property> <name>fs.jfs.cache.oss-accessKeyId</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-accessKeySecret</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-endpoint</name> <value>oss-cn-xxx.aliyuncs.com</value> </property> </configuration> - If you want to save the AccessKey ID, AccessKey secret, and endpoint of Amazon S3,
save the following information into the core-site.xml file:
<configuration> <property> <name>fs.s3a.access.key</name> <value>xxx</value> </property> <property> <name>fs.s3a.secret.key</name> <value>xxx</value> </property> <property> <name>fs.s3.endpoint</name> <value>s3-us-west-1.amazonaws.com</value> </property> </configuration>