TensorFlow 1.15.0 of Python 3.0 is a built-in component of E-MapReduce (EMR) Data Science clusters. You can use this component without additional configurations. On the master node of a Data Science cluster, you can purchase only vCPU resources to compute TensorFlow jobs. On a core node of a Data Science cluster, you can purchase vCPU or vGPU resources to compute TensorFlow jobs. This topic describes how to view the TensorFlow version, switch the TensorFlow version, and install a Python package.
Usage guide
View the TensorFlow version
Log on to the master node of your cluster in SSH mode. For more information, see Log on to a cluster.
Run the pip3 list command to view the TensorFlow version.
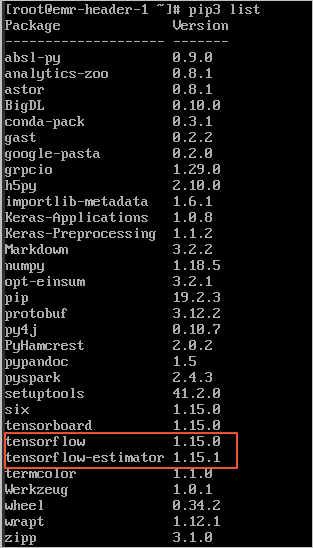
Switch the TensorFlow version
Download a compressed package that is used to switch the TensorFlow version.
In this example, the package name is install_tf_header.tar.gz.
Use a file transfer tool to upload install_tf_header.tar.gz to a directory of the master node in your Data Science cluster.
NoteIn this example, the compressed package is uploaded to the /home directory.
Log on to the master node of your cluster in SSH mode. For more information, see Log on to a cluster.
Run the following commands to switch the TensorFlow version:
Decompress the package.
tar -zxvf install_tf_header.tar.gzSwitch the TensorFlow version.
Command syntax
sh install_tf_header.sh <version>versionspecifies the destination version.Example: Run the following command to switch the TensorFlow version to 2.0.3:
sh install_tf_header.sh 2.0.3
Run the pip3 list command to view the TensorFlow version.
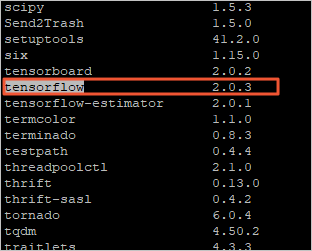
The TensorFlow version is switched to 2.0.3.
Install a Python package
Download a Python package.
In this example, the name of the Python package is install_app_onds.tar.gz.
Use a file transfer tool to upload install_app_onds.tar.gz to a directory of the master node in your Data Science cluster.
NoteIn this example, the compressed package is uploaded to the /home directory.
Log on to the master node of your cluster in SSH mode. For more information, see Log on to a cluster.
Run the following commands to install the Python package on all nodes of your Data Science cluster:
Decompress the package.
tar -zxvf install_app_onds.tar.gzInstall the Python package.
Command syntax
sh install_app_onds.sh <package_name> <version>where:
package_namespecifies the name of the Python package that you want to install.versionspecifies the version of the Python package that you want to install.
Example: Run the following command to install the GNU Readline package of version 8.0.0 on all nodes of your Data Science cluster:
sh install_app_onds.sh gnureadline 8.0.0