YARN node labels let you divide an E-MapReduce (EMR) cluster into partitions and control which queues and compute jobs run on which nodes. This is useful for isolating batch jobs from streaming workloads, reserving nodes for critical jobs, or handling clusters with heterogeneous node specs.
Version compatibility
| Cluster version | Configuration type | How to manage |
|---|---|---|
| Earlier than EMR V5.11.1 or EMR V3.45.1 | centralized (default) |
Follow the instructions in this topic |
| EMR V5.11.1, EMR V3.45.1, or later | distributed (default) |
Use the EMR console |
This topic covers centralized mode. If your cluster runs EMR V5.11.1 or EMR V3.45.1 or later, manage YARN partitions directly in the EMR console. For more information, see Manage YARN partitions in the EMR console.
Key concepts
Partitions
Each node belongs to exactly one partition. Nodes without an assigned partition belong to the DEFAULT partition (partition="").
Partitions come in two types:
-
Exclusive partition: Containers are allocated to a node only when the job explicitly requests that partition.
-
Non-exclusive partition: Containers are allocated when the partition is explicitly requested, or when the DEFAULT partition is specified and the node has idle resources.
Capacity Scheduler requirement
Only Capacity Scheduler supports node labels. Before proceeding, confirm that yarn.resourcemanager.scheduler.class is set to org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler in yarn-site.xml.
For background on the Apache Hadoop implementation, see YARN Node Labels.
Prerequisites
Before you begin, ensure that you have:
-
An EMR cluster running a version earlier than EMR V5.11.1 or EMR V3.45.1
-
Sufficient permissions to modify YARN configurations and restart ResourceManager
-
Access to the EMR console
Step 1: Enable node labels in yarn-site.xml
-
In the EMR console, go to the YARN service page and click the Configure tab.
-
Click the yarn-site.xml tab and add the following configuration items:
Key Value Description yarn.node-labels.enabledtrueEnables the node label feature yarn.node-labels.fs-store.root-dir/tmp/node-labelsStorage directory for node label data -
Click Save, then restart ResourceManager for the changes to take effect.
Ifyarn.node-labels.fs-store.root-diris set to a directory path rather than a full URL, YARN uses the file system specified byfs.defaultFS. This is equivalent to${fs.defaultFS}/tmp/node-labels. The default file system in EMR is Hadoop Distributed File System (HDFS).
For high availability (HA) clusters, always set yarn.node-labels.fs-store.root-dir to a distributed file system path (such as /tmp/node-labels or ${fs.defaultFS}/tmp/node-labels). In HA clusters, ResourceManager is deployed on multiple nodes. After a failover, the new active node cannot read node label data from a local path. Before switching to a distributed file system path, confirm that HDFS is healthy and that the hadoop user has read and write access. If these conditions are not met, ResourceManager fails to start.
Step 2: Create partitions and assign nodes
Run the following commands as the hadoop user:
# Switch to the hadoop user
sudo su - hadoop
# Create partitions
yarn rmadmin -addToClusterNodeLabels "DEMO"
yarn rmadmin -addToClusterNodeLabels "CORE"
# List nodes to get their hostnames
yarn node -list
# Map nodes to partitions
# In EMR clusters, each node runs exactly one NodeManager, so no port is needed.
yarn rmadmin -replaceLabelsOnNode "core-1-1.c-XXX.cn-hangzhou.emr.aliyuncs.com=DEMO"
yarn rmadmin -replaceLabelsOnNode "core-1-2.c-XXX.cn-hangzhou.emr.aliyuncs.com=DEMO"For node groups that scale out automatically: Add the yarn rmadmin -replaceLabelsOnNode command to the bootstrap script of the node group. This ensures partitions are assigned after NodeManager starts on each new node.
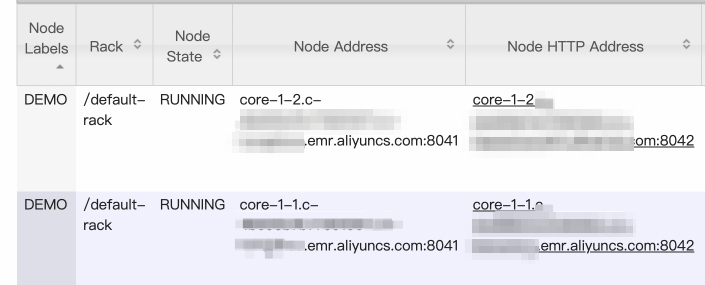
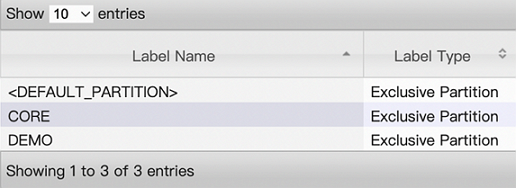
After running the commands, check the configuration results on the web UI of ResourceManager.
-
Node configurations:
-
Node label configurations:
Step 3: Configure Capacity Scheduler queues
Add the following configuration items to capacity-scheduler.xml. Replace <queue-path> with the queue path and <label> with the partition name.
| Configuration item | Default | Description |
|---|---|---|
yarn.scheduler.capacity.<queue-path>.accessible-node-labels |
Inherited from parent | Comma-separated list of partitions accessible to the queue. |
yarn.scheduler.capacity.<queue-path>.accessible-node-labels.<label>.capacity |
0 |
Percentage of partition resources available to this queue. The sum across all child queues under the same parent must equal 100. |
yarn.scheduler.capacity.<queue-path>.accessible-node-labels.<label>.maximum-capacity |
100 |
Maximum percentage of partition resources this queue can use. |
yarn.scheduler.capacity.<queue-path>.default-node-label-expression |
Empty string (DEFAULT partition) | Default partition for containers in jobs submitted to this queue when no partition is specified. |
Root queue requirement: The capacity value for all queues defaults to 0. For child queues to get any resources from a partition, first set yarn.scheduler.capacity.root.accessible-node-labels.<label>.capacity to 100 on the root queue. Then assign capacity values across child queues so they sum to 100.
The following example configures the default queue to use the DEMO partition:
<configuration>
<!-- Grant the default queue access to the DEMO partition -->
<property>
<name>yarn.scheduler.capacity.root.default.accessible-node-labels</name>
<value>DEMO</value>
</property>
<!-- Set root queue capacity in the DEMO partition to 100 (required) -->
<property>
<name>yarn.scheduler.capacity.root.accessible-node-labels.DEMO.capacity</name>
<value>100</value>
</property>
<!-- Set default queue capacity in the DEMO partition -->
<property>
<name>yarn.scheduler.capacity.root.default.accessible-node-labels.DEMO.capacity</name>
<value>100</value>
</property>
<!-- Optional: set maximum capacity for the default queue in the DEMO partition -->
<property>
<name>yarn.scheduler.capacity.root.default.accessible-node-labels.DEMO.maximum-capacity</name>
<value>100</value>
</property>
<!-- Optional: send jobs from the default queue to DEMO by default -->
<property>
<name>yarn.scheduler.capacity.root.default.default-node-label-expression</name>
<value>DEMO</value>
</property>
</configuration>To apply the changes without restarting YARN, use the refreshQueues feature on the Status tab of the YARN service page.
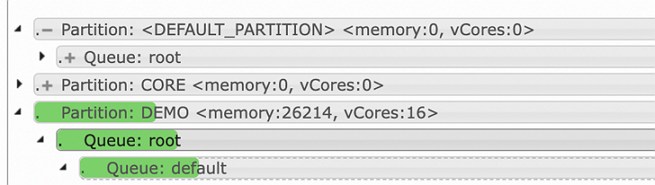
After applying the Capacity Scheduler configuration and refreshing queues:
Step 4: Set node label expressions in compute jobs
In addition to queue-level defaults, you can specify partitions per job for MapReduce, Spark, and Flink. Tez does not support node label expressions.
MapReduce
| Parameter | Description |
|---|---|
mapreduce.job.node-label-expression |
Default partition for all containers in the job |
mapreduce.job.am.node-label-expression |
Partition for ApplicationMaster |
mapreduce.map.node-label-expression |
Partition for map tasks |
mapreduce.reduce.node-label-expression |
Partition for reduce tasks |
Spark
| Parameter | Description |
|---|---|
spark.yarn.am.nodeLabelExpression |
Partition for ApplicationMaster |
spark.yarn.executor.nodeLabelExpression |
Partition for Executor |
Flink
| Parameter | Description |
|---|---|
yarn.application.node-label |
Default partition for all containers in the job |
yarn.taskmanager.node-label |
Partition for TaskManager. Requires Apache Flink 1.15.0 or later on EMR V3.44.0, EMR V5.10.0, or later minor versions. |
Verify the configuration
After completing the steps above, confirm the configuration through the ResourceManager web UI.
Open the ResourceManager web UI and verify that node partition assignments and queue-level partition settings appear as expected. You can also run yarn node -list -showDetails to query the partition to which each node belongs.
FAQ
Why must I use a distributed file system path for node label storage in HA clusters?
Open source Hadoop stores node label data at file:///tmp/hadoop-yarn-${user}/node-labels/ by default. In an HA cluster, if the active ResourceManager fails and a standby takes over, the new active node cannot read label data from a path local to the previous node. Using a distributed file system path (such as HDFS) ensures all ResourceManager instances can access the same data regardless of which node is active.
Why should I not specify a NodeManager port when mapping nodes to partitions?
Each node in an EMR cluster runs exactly one NodeManager, so the port is unambiguous and not required. If you specify an invalid or random port, the yarn rmadmin -replaceLabelsOnNode command cannot locate the NodeManager and the mapping silently fails. Run yarn node -list -showDetails to confirm the partition assignment after running the command.
When should I use node labels?
Node labels are not enabled by default in EMR clusters. Enabling them increases O&M complexity, because YARN resource statistics only cover the DEFAULT partition and do not reflect partition-level resource usage.
Consider enabling node labels when:
-
Separating batch and streaming jobs: Run both workload types simultaneously without contention by assigning them to different partitions.
-
Protecting critical nodes: Pin high-priority jobs to nodes that are not part of the auto-scaling pool.
-
Handling heterogeneous nodes: Route jobs to node groups with matching resource profiles to avoid scheduling imbalances.
What's next
-
Manage YARN partitions in the EMR console (EMR V5.11.1 / V3.45.1 and later)
-
YARN Node Labels (Apache Hadoop documentation)