This topic describes how to import data from Flink to a ClickHouse cluster.
Prerequisites
An E-MapReduce (EMR) Flink cluster is created. For more information, see Create a cluster.
An EMR ClickHouse cluster is created. For more information, see Create a ClickHouse cluster.
Background information
For more information about Flink, visit the Apache Flink official website.
Sample code
Sample code:
Stream processing
package com.company.packageName import java.util.concurrent.ThreadLocalRandom import scala.annotation.tailrec import org.apache.flink.api.common.typeinfo.Types import org.apache.flink.api.java.io.jdbc.JDBCAppendTableSink import org.apache.flink.streaming.api.scala._ import org.apache.flink.table.api.scala.{StreamTableEnvironment, table2RowDataStream} object StreamingJob { case class Test(id: Int, key1: String, value1: Boolean, key2: Long, value2: Double) private var dbName: String = "default" private var tableName: String = "" private var ckHost: String = "" private var ckPort: String = "8123" private var user: String = "default" private var password: String = "" def main(args: Array[String]) { parse(args.toList) checkArguments() // set up the streaming execution environment val env = StreamExecutionEnvironment.getExecutionEnvironment val tableEnv = StreamTableEnvironment.create(env) val insertIntoCkSql = s""" | INSERT INTO $tableName ( | id, key1, value1, key2, value2 | ) VALUES ( | ?, ?, ?, ?, ? | ) |""".stripMargin val jdbcUrl = s"jdbc:clickhouse://$ckHost:$ckPort/$dbName" println(s"jdbc url: $jdbcUrl") println(s"insert sql: $insertIntoCkSql") val sink = JDBCAppendTableSink .builder() .setDrivername("ru.yandex.clickhouse.ClickHouseDriver") .setDBUrl(jdbcUrl) .setUsername(user) .setPassword(password) .setQuery(insertIntoCkSql) .setBatchSize(1000) .setParameterTypes(Types.INT, Types.STRING, Types.BOOLEAN, Types.LONG, Types.DOUBLE) .build() val data: DataStream[Test] = env.fromCollection(1 to 1000).map(i => { val rand = ThreadLocalRandom.current() val randString = (0 until rand.nextInt(10, 20)) .map(_ => rand.nextLong()) .mkString("") Test(i, randString, rand.nextBoolean(), rand.nextLong(), rand.nextGaussian()) }) val table = table2RowDataStream(tableEnv.fromDataStream(data)) sink.emitDataStream(table.javaStream) // execute program env.execute("Flink Streaming Scala API Skeleton") } private def printUsageAndExit(exitCode: Int = 0): Unit = { println("Usage: flink run com.company.packageName.StreamingJob /path/to/flink-clickhouse-demo-1.0.0.jar [options]") println(" --dbName Specifies the name of the ClickHouse database. Default value: default.") println(" --tableName Specifies the name of the table in the ClickHouse database.") println(" --ckHost Specifies the IP address of the ClickHouse cluster.") println(" --ckPort Specifies the port number of the ClickHouse cluster. Default value: 8123.") println(" --user Specifies the username that is used to access the ClickHouse cluster.") println(" --password Specifies the password that is used to access the ClickHouse cluster.") System.exit(exitCode) } @tailrec private def parse(args: List[String]): Unit = args match { case ("--help" | "-h") :: _ => printUsageAndExit() case "--dbName" :: value :: tail => dbName = value parse(tail) case "--tableName" :: value :: tail => tableName = value parse(tail) case "--ckHost" :: value :: tail => ckHost = value parse(tail) case "--ckPort" :: value :: tail => ckPort = value parse(tail) case "--user" :: value :: tail => user = value parse(tail) case "--password" :: value :: tail => password = value parse(tail) case Nil => case _ => printUsageAndExit(1) } private def checkArguments(): Unit = { if ("".equals(tableName) || "".equals(ckHost)) { printUsageAndExit(2) } } }Batch processing
package com.company.packageName import java.util.concurrent.ThreadLocalRandom import scala.annotation.tailrec import org.apache.flink.Utils import org.apache.flink.api.common.typeinfo.Types import org.apache.flink.api.java.io.jdbc.JDBCAppendTableSink import org.apache.flink.api.scala._ import org.apache.flink.table.api.scala.{BatchTableEnvironment, table2RowDataSet} object BatchJob { case class Test(id: Int, key1: String, value1: Boolean, key2: Long, value2: Double) private var dbName: String = "default" private var tableName: String = "" private var ckHost: String = "" private var ckPort: String = "8123" private var user: String = "default" private var password: String = "" def main(args: Array[String]) { parse(args.toList) checkArguments() // set up the batch execution environment val env = ExecutionEnvironment.getExecutionEnvironment val tableEnv = BatchTableEnvironment.create(env) val insertIntoCkSql = s""" | INSERT INTO $tableName ( | id, key1, value1, key2, value2 | ) VALUES ( | ?, ?, ?, ?, ? | ) |""".stripMargin val jdbcUrl = s"jdbc:clickhouse://$ckHost:$ckPort/$dbName" println(s"jdbc url: $jdbcUrl") println(s"insert sql: $insertIntoCkSql") val sink = JDBCAppendTableSink .builder() .setDrivername("ru.yandex.clickhouse.ClickHouseDriver") .setDBUrl(jdbcUrl) .setUsername(user) .setPassword(password) .setQuery(insertIntoCkSql) .setBatchSize(1000) .setParameterTypes(Types.INT, Types.STRING, Types.BOOLEAN, Types.LONG, Types.DOUBLE) .build() val data = env.fromCollection(1 to 1000).map(i => { val rand = ThreadLocalRandom.current() val randString = (0 until rand.nextInt(10, 20)) .map(_ => rand.nextLong()) .mkString("") Test(i, randString, rand.nextBoolean(), rand.nextLong(), rand.nextGaussian()) }) val table = table2RowDataSet(tableEnv.fromDataSet(data)) sink.emitDataSet(Utils.convertScalaDatasetToJavaDataset(table)) // execute program env.execute("Flink Batch Scala API Skeleton") } private def printUsageAndExit(exitCode: Int = 0): Unit = { println("Usage: flink run com.company.packageName.StreamingJob /path/to/flink-clickhouse-demo-1.0.0.jar [options]") println(" --dbName Specifies the name of the ClickHouse database. Default value: default.") println(" --tableName Specifies the name of the table in the ClickHouse database.") println(" --ckHost Specifies the IP address of the ClickHouse cluster.") println(" --ckPort Specifies the port number of the ClickHouse cluster. Default value: 8123.") println(" --user Specifies the username that is used to access the ClickHouse cluster.") println(" --password Specifies the password that is used to access the ClickHouse cluster.") System.exit(exitCode) } @tailrec private def parse(args: List[String]): Unit = args match { case ("--help" | "-h") :: _ => printUsageAndExit() case "--dbName" :: value :: tail => dbName = value parse(tail) case "--tableName" :: value :: tail => tableName = value parse(tail) case "--ckHost" :: value :: tail => ckHost = value parse(tail) case "--ckPort" :: value :: tail => ckPort = value parse(tail) case "--user" :: value :: tail => user = value parse(tail) case "--password" :: value :: tail => password = value parse(tail) case Nil => case _ => printUsageAndExit(1) } private def checkArguments(): Unit = { if ("".equals(tableName) || "".equals(ckHost)) { printUsageAndExit(2) } } }
Procedure
Step 1: Create ClickHouse tables
Log on to the ClickHouse cluster in SSH mode. For more information, see Log on to a cluster.
Run the following command to start the ClickHouse client:
clickhouse-client -h core-1-1 -mNoteIn the sample command, core-1-1 indicates the name of the core node that you log on to. If you have multiple core nodes, you can log on to one of the nodes.
Create a ClickHouse database and the required ClickHouse tables.
Run the following command to create a database named clickhouse_database_name:
CREATE DATABASE clickhouse_database_name ON CLUSTER cluster_emr;Alibaba Cloud EMR automatically generates a ClickHouse cluster named cluster_emr. You can customize the name of the database.
Run the following command to create a table named clickhouse_table_name_local:
CREATE TABLE clickhouse_database_name.clickhouse_table_name_local ON CLUSTER cluster_emr ( id UInt32, key1 String, value1 UInt8, key2 Int64, value2 Float64 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/clickhouse_database_name/clickhouse_table_name_local', '{replica}') ORDER BY id;NoteYou can customize the name of the table, but the table name must end with _local. The layer, shard, and replica parameters are macros that are automatically generated by Alibaba Cloud EMR for ClickHouse clusters and can be directly used.
Run the following command to create a table named clickhouse_table_name_all. The fields in this table are defined in the same way as the fields in the clickhouse_table_name_local table.
NoteYou can customize the name of the table, but the table name must end with _all.
CREATE TABLE clickhouse_database_name.clickhouse_table_name_all ON CLUSTER cluster_emr ( id UInt32, key1 String, value1 UInt8, key2 Int64, value2 Float64 ) ENGINE = Distributed(cluster_emr, clickhouse_database_name, clickhouse_table_name_local, rand());
Step 2: Compile and package the code
Download and decompress the flink-clickhouse-demo.tgz file to your on-premises machine.
In the CLI, go to the path that stores the pom.xml file and run the following command to package the file:
mvn clean packageThe JAR package named flink-clickhouse-demo-1.0.0.jar is displayed in the target directory based on the artifactId information in the pom.xml file.
Step 3: Submit a job
Log on to the Flink cluster in SSH mode. For more information, see Log on to a cluster.
Upload the flink-clickhouse-demo-1.0.0.jar package to the root directory of the Flink cluster.
NoteIn this example, the flink-clickhouse-demo-1.0.0.jar package is uploaded to the root directory. You can upload the package to a directory based on your business requirements.
Submit the job.
Sample code:
Stream processing job
flink run -m yarn-cluster \ -c com.aliyun.emr.StreamingJob \ flink-clickhouse-demo-1.0.0.jar \ --dbName clickhouse_database_name \ --tableName clickhouse_table_name_all \ --ckHost ${clickhouse_host} \ --password ${password};Batch processing job
flink run -m yarn-cluster \ -c com.aliyun.emr.BatchJob \ flink-clickhouse-demo-1.0.0.jar \ --dbName clickhouse_database_name \ --tableName clickhouse_table_name_all \ --ckHost ${clickhouse_host} \ --password ${password};
Parameter
Description
dbName
The name of the ClickHouse database. Default value: default. In this example, a database named clickhouse_database_name is used.
tableName
The name of the table in the ClickHouse database. In this example, a table named clickhouse_table_name_all is used.
ckHost
The private or public IP address of the master node of the ClickHouse cluster. For more information about how to obtain the IP address, see the Obtain the IP address of the master node section in this topic.
password
The password that is used to access the ClickHouse cluster.
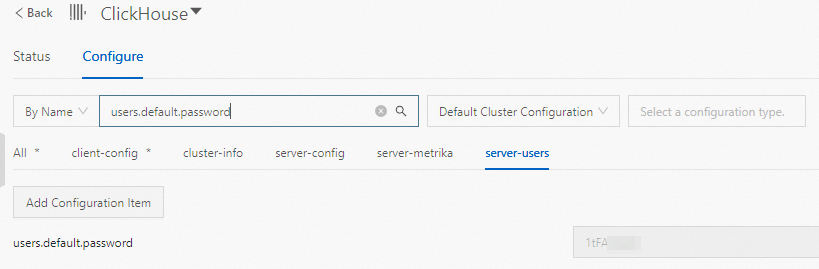
On the Configure tab of the ClickHouse service page, you can view the users.default.password parameter to obtain the password.
Obtain the IP address of the master node
Go to the Nodes tab.
Log on to the EMR console. In the left-side navigation pane, click EMR on ECS.
In the top navigation bar, select the region where your cluster resides and select a resource group based on your business requirements.
On the EMR on ECS page, find the cluster that you want to manage and click Nodes in the Actions column.
On the Nodes tab, find the master node group, click the
 icon, and then copy the IP address in the Public IP Address column.
icon, and then copy the IP address in the Public IP Address column.