When Spark jobs run large shuffles, the standard shuffle implementation can cause write amplification, connection storms, and NodeManager instability. Celeborn is a remote shuffle service that offloads intermediate shuffle data to a dedicated storage layer, replacing the standard shuffle with a push-based model that improves stability, reduces resource contention, and supports compute-storage separation.
How Celeborn works
The standard shuffle implementation has several limitations:
-
Write amplification: Large shuffle write tasks can cause data overflow, leading to write amplification.
-
Connection reset: Shuffle read tasks generate many small network packets, which can trigger connection resets.
-
High disk and CPU load: Shuffle read tasks produce many small I/O requests and random reads, increasing disk and CPU load.
-
Connection explosion: With thousands of mappers (M) and reducers (N), the number of connections grows to M x N, making jobs difficult to run.
-
YARN instability: When shuffle data volume is extremely large, NodeManager restarts, disrupting YARN-based task scheduling.
Celeborn addresses these issues by using a push-based shuffle model:
-
Reduces mapper memory pressure by using push-based shuffle instead of pull-based shuffle.
-
Supports I/O aggregation, reducing read-side connections from M x N to N and converting random reads to sequential reads.
-
Uses a two-replica mechanism to reduce fetch failures.
-
Supports compute-storage separation, so the shuffle service can run on dedicated hardware.
-
Eliminates dependency on local disks for Spark on Kubernetes workloads.
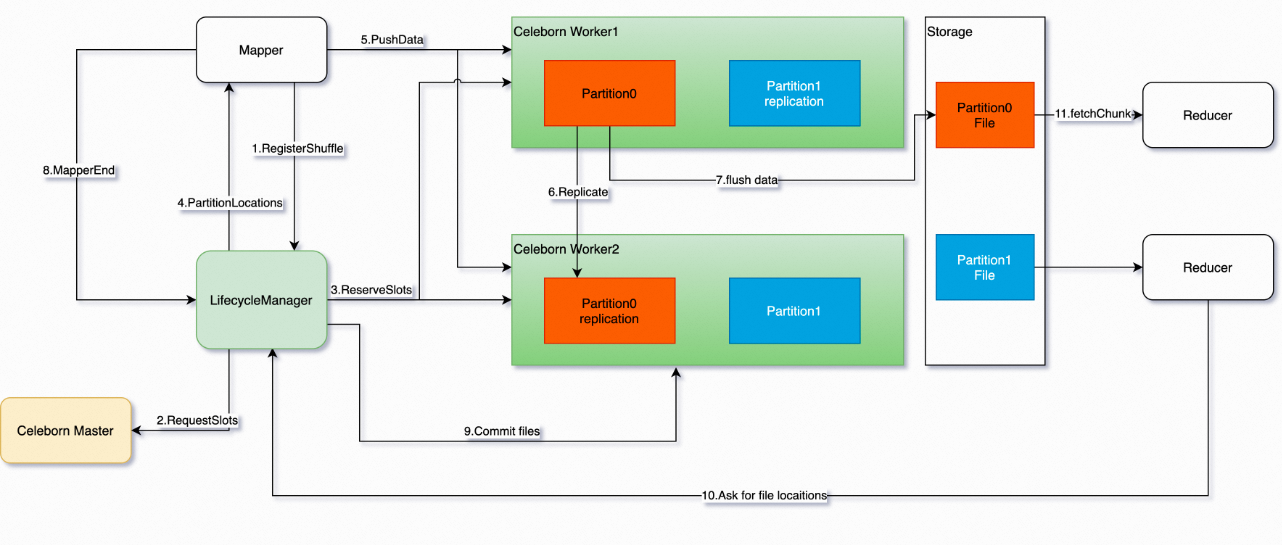
The following figure shows the Celeborn architecture.
Prerequisites
Before you begin, ensure that you have:
-
An E-MapReduce (EMR) DataLake cluster or a custom cluster with the Celeborn service selected. For more information, see Create a cluster.
Supported versions
Celeborn is supported on the following cluster types and versions:
| Cluster | Minimum version |
|---|---|
| DataLake cluster | EMR V3.45.0 or later, EMR V5.11.0 or later |
| Custom cluster | EMR V3.45.0 or later, EMR V5.11.0 or later |
Enable Celeborn for Spark
You can enable Celeborn for Spark in two ways: through the EMR console with one click (recommended), or by manually setting Spark parameters.
Enable with one click (recommended)
For EMR V5.11.1 or later and EMR V3.45.1 or later:
On the Status tab of the Spark service page, go to the Service Overview section and turn on enableCeleborn.
For EMR V5.11.0 and EMR V3.45.0:
-
On the Status tab of the Spark service page, go to the Components section and find the SparkThriftServer component.
-
In the Actions column, move the pointer over the
 icon and select enableCeleborn.
icon and select enableCeleborn.
After you click enableCeleborn, EMR automatically updates the Spark parameters described in the next section, restarts the SparkThriftServer component, and modifies the spark-defaults.conf and spark-thriftserver.conf configuration files.
-
enableCeleborn: all Spark jobs in the cluster use Celeborn.
-
disableCeleborn: all Spark jobs in the cluster stop using Celeborn.
Configure Spark parameters manually
To enable Celeborn manually, add the following parameters to your Spark configuration:
# Shuffle manager — class name changed in Celeborn 0.4.0:
# Celeborn 0.3.x or earlier: org.apache.spark.shuffle.celeborn.RssShuffleManager
# Celeborn 0.4.x or later: org.apache.spark.shuffle.celeborn.SparkShuffleManager
spark.shuffle.manager org.apache.spark.shuffle.celeborn.SparkShuffleManager
# Kryo serializer is required — Java serializer does not support relocation
spark.serializer org.apache.spark.serializer.KryoSerializer
# Disable the external shuffle service — required to use Celeborn
# Note: Setting this to true means Celeborn is NOT used.
# Celeborn does not affect Spark dynamic allocation.
spark.shuffle.service.enabled false
# Shuffle writer mode:
# hash (default): higher memory usage when partition count is large
# sort: fixed memory usage, better for workloads with many partitions
spark.celeborn.shuffle.writer hash
# Two-replica replication — reduces fetch failures
spark.celeborn.push.replicate.enabled true
# Celeborn master endpoint
# Format: <celeborn-master-ip>:9097 (use the public IP address of the master node)
# For high-availability clusters, specify all master node IPs
spark.celeborn.master.endpoints <celeborn-master-ip>:9097
# Adaptive Query Execution (AQE) settings
# Disable local shuffle reader for better Celeborn performance
spark.sql.adaptive.enabled true
spark.sql.adaptive.localShuffleReader.enabled false
spark.sql.adaptive.skewJoin.enabled trueAlibaba Cloud Spark and open source Spark 3.5 are compatible with Celeborn.
Spark parameter reference
| Parameter | Description | Default |
|---|---|---|
spark.shuffle.manager |
Shuffle manager class. Use org.apache.spark.shuffle.celeborn.SparkShuffleManager for Celeborn 0.4.x or later, and org.apache.spark.shuffle.celeborn.RssShuffleManager for Celeborn 0.3.x or earlier. |
— |
spark.serializer |
Must be set to org.apache.spark.serializer.KryoSerializer. |
— |
spark.shuffle.service.enabled |
Must be set to false. If set to true, Celeborn is not used. |
— |
spark.celeborn.shuffle.writer |
Write mode. hash: variable memory proportional to partition count. sort: fixed memory, stable for large partition counts. |
hash |
spark.celeborn.push.replicate.enabled |
Enables two-replica replication to reduce fetch failures. Valid values: true (default) and false. |
true |
spark.celeborn.master.endpoints |
Celeborn master endpoint in the format <celeborn-master-ip>:9097, where <celeborn-master-ip> is the public IP address of the master node. For high-availability clusters, specify all master node IPs. |
— |
spark.sql.adaptive.enabled |
Enables Adaptive Query Execution (AQE). | — |
spark.sql.adaptive.localShuffleReader.enabled |
Set to false to disable the local shuffle reader and get full Celeborn performance. |
— |
spark.sql.adaptive.skewJoin.enabled |
Enables skew join optimization in AQE. | — |
Configure Celeborn parameters
View and modify Celeborn parameters on the Configure tab of the Celeborn service page.
Parameter values vary by node group.
| Parameter | Description | Default |
|---|---|---|
celeborn.worker.flusher.threads |
Number of threads used when writing data to disk. | HDD: 1, SSD: 8 |
CELEBORN_WORKER_OFFHEAP_MEMORY |
Off-heap memory size for each worker node. | Calculated from cluster settings |
celeborn.application.heartbeat.timeout |
Heartbeat timeout for your application. After this period elapses, application resources are released. | 120s |
celeborn.worker.flusher.buffer.size |
Flush buffer size. When the buffer reaches this size, flushing is triggered. | 256K |
celeborn.metrics.enabled |
Enables monitoring. | true |
CELEBORN_WORKER_MEMORY |
Heap memory size for each core node. | 1g |
CELEBORN_MASTER_MEMORY |
Heap memory size for the master node. | 2g |
Restart the CelebornMaster component
After modifying Celeborn parameters, restart the CelebornMaster component to apply the changes.
-
On the Status tab of the Celeborn service page, find the CelebornMaster component. In the Actions column, move the pointer over the
icon and select restart_clean_meta.NoteFor non-high-availability clusters, click Restart in the Actions column instead.
-
In the dialog box, turn off Rolling Execution, set the Execution Reason, and click OK.
-
In the confirmation dialog box, click OK.