You can run Spark jobs on elastic container instances in Kubernetes clusters. Elastic Container Instance provides scalable resources and ensures the automatic deployment and high availability of Spark jobs. This improves the running efficiency and stability of Spark jobs. This topic describes how to install Kubernetes Operator for Apache Spark in an Container Service for Kubernetes (ACK) Serverless cluster and run a Spark job on an elastic container instance.
Background information
Apache Spark is an open source program that is widely used to analyze workloads in scenarios such as big data computing and machine learning. You can use Kubernetes to run and manage resources on Apache Spark 2.3.0 and later.
Kubernetes Operator for Apache Spark is designed to run Spark jobs in Kubernetes clusters. It allows you to submit Spark tasks that are defined in custom resource definitions (CRDs) to Kubernetes clusters. Kubernetes Operator for Apache Spark provides the following benefits:
Compared with open source Apache Spark, Kubernetes Operator for Apache Spark provides more features.
Kubernetes Operator for Apache Spark can be integrated with the storage, monitoring, and logging components of Kubernetes.
Kubernetes Operator for Apache Spark supports advanced Kubernetes features such as disaster recovery and auto scaling. In addition, Kubernetes Operator for Apache Spark can optimize resource scheduling.
Preparations
Create an ACK Serverless cluster.
Create an ACK Serverless cluster in the ACK console. For more information, see Create an ACK Serverless cluster.
ImportantIf you need to pull an image over the Internet or if your training jobs need to access the Internet, you must configure an Internet NAT gateway.
You can use kubectl and one of the following methods to manage and access the ACK Serverless cluster:
If you want to manage the cluster from an on-premises machine, install and configure the kubectl client. For more information, see Connect to an ACK cluster by using kubectl.
Use kubectl to manage the ACK Serverless cluster on Cloud Shell. For more information, see Use kubectl to manage ACK clusters on Cloud Shell.
Create an OSS bucket.
You must create an Object Storage Service (OSS) bucket to store data, including the test data, test results, and logs. For more information, see Create buckets.
Install Kubernetes Operator for Apache Spark
Install Kubernetes Operator for Apache Spark.
In the left-side navigation pane of the ACK console, choose Marketplace > Marketplace.
On the App Catalog tab, enter ack-spark-operator in the search box, find ack-spark-operator, and click its icon.
In the upper-right corner of the page, click Deploy.
In the Deploy panel, select the cluster for which you want to install Kubernetes Operator for Apache Spark and follow the on-screen instructions to complete the configuration.
Create a ServiceAccount, Role, and RoleBinding.
A Spark job requires a ServiceAccount to acquire the permissions to create pods. Therefore, you must create a ServiceAccount, Role, and RoleBinding. The following YAML example shows how to create a ServiceAccount, Role, and RoleBinding. Replace the namespaces with the actual values.
apiVersion: v1 kind: ServiceAccount metadata: name: spark namespace: default --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: namespace: default name: spark-role rules: - apiGroups: [""] resources: ["pods"] verbs: ["*"] - apiGroups: [""] resources: ["services"] verbs: ["*"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: spark-role-binding namespace: default subjects: - kind: ServiceAccount name: spark namespace: default roleRef: kind: Role name: spark-role apiGroup: rbac.authorization.k8s.io
Build an image of the Spark job
You need to compile the Java Archive (JAR) package of the Spark job and use Dockerfile to package the image.
The following example shows how to configure Dockerfile when a Spark base image of ACK is used.
FROM registry.aliyuncs.com/acs/spark:ack-2.4.5-latest
RUN mkdir -p /opt/spark/jars
# If you want to read data from OSS or sink events to OSS, add the following JAR packages to the image.
ADD https://repo1.maven.org/maven2/com/aliyun/odps/hadoop-fs-oss/3.3.8-public/hadoop-fs-oss-3.3.8-public.jar $SPARK_HOME/jars
ADD https://repo1.maven.org/maven2/com/aliyun/oss/aliyun-sdk-oss/3.8.1/aliyun-sdk-oss-3.8.1.jar $SPARK_HOME/jars
ADD https://repo1.maven.org/maven2/org/aspectj/aspectjweaver/1.9.5/aspectjweaver-1.9.5.jar $SPARK_HOME/jars
ADD https://repo1.maven.org/maven2/org/jdom/jdom/1.1.3/jdom-1.1.3.jar $SPARK_HOME/jars
COPY SparkExampleScala-assembly-0.1.jar /opt/spark/jarsIt may be time-consuming to pull a large Spark image. You can use ImageCache to accelerate image pulling. For more information, see Manage image caches and Use ImageCache to accelerate the creation of pods.
You can also use Alibaba Cloud Spark base images. Alibaba Cloud provides the Spark 2.4.5 base image, which is optimized for resource scheduling and auto scaling in Kubernetes clusters. This base image accelerates resource scheduling and application startups. You can enable the scheduling optimization feature by setting the enableAlibabaCloudFeatureGates variable in the Helm chart to true. If you want to start up the application faster, you can set enableWebhook to false. 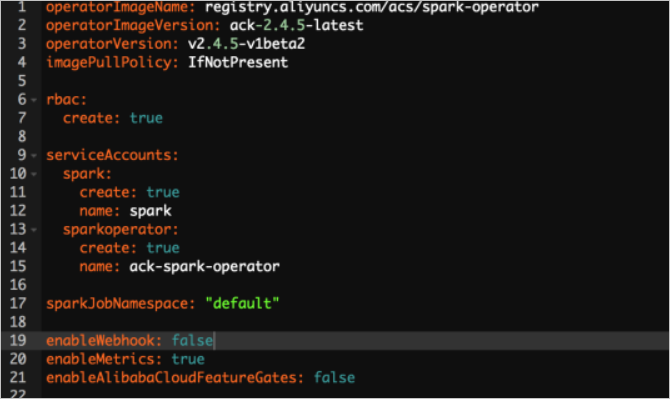
Create a Spark job template and submit the job
Create a YAML file for a Spark job and deploy the Spark job.
Create a file named spark-pi.yaml.
The following code provides a sample template of a typical Spark job. For more information, see spark-on-k8s-operator.
apiVersion: "sparkoperator.k8s.io/v1beta2" kind: SparkApplication metadata: name: spark-pi namespace: default spec: type: Scala mode: cluster image: "registry.aliyuncs.com/acs/spark:ack-2.4.5-latest" imagePullPolicy: Always mainClass: org.apache.spark.examples.SparkPi mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.11-2.4.5.jar" sparkVersion: "2.4.5" restartPolicy: type: Never driver: cores: 2 coreLimit: "2" memory: "3g" memoryOverhead: "1g" labels: version: 2.4.5 serviceAccount: spark annotations: k8s.aliyun.com/eci-kube-proxy-enabled: 'true' k8s.aliyun.com/eci-auto-imc: "true" tolerations: - key: "virtual-kubelet.io/provider" operator: "Exists" executor: cores: 2 instances: 1 memory: "3g" memoryOverhead: "1g" labels: version: 2.4.5 annotations: k8s.aliyun.com/eci-kube-proxy-enabled: 'true' k8s.aliyun.com/eci-auto-imc: "true" tolerations: - key: "virtual-kubelet.io/provider" operator: "Exists"Deploy a Spark job.
kubectl apply -f spark-pi.yaml
Configure log collection
If you want to collect the stdout logs of a Spark job, you can configure environment variables in the envVars field of the Spark driver and Spark executor. Then, logs are automatically collected. For more information, see Customize log collection for an elastic container instance.
envVars:
aliyun_logs_test-stdout_project: test-k8s-spark
aliyun_logs_test-stdout_machinegroup: k8s-group-app-spark
aliyun_logs_test-stdout: stdoutBefore you submit a Spark job, you can configure the environment variables of the Spark driver and Spark executor as shown in the preceding code to implement automatic log collection. 
Configure a history server
A Spark history server allows you to review Spark jobs. You can set the SparkConf field in the CRD of the Spark application to allow the application to sink events to OSS. Then, you can use the history server to retrieve the data from OSS. The following code provides sample configurations:
sparkConf:
"spark.eventLog.enabled": "true"
"spark.eventLog.dir": "oss://bigdatastore/spark-events"
"spark.hadoop.fs.oss.impl": "org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem"
# oss bucket endpoint such as oss-cn-beijing.aliyuncs.com
"spark.hadoop.fs.oss.endpoint": "oss-cn-beijing.aliyuncs.com"
"spark.hadoop.fs.oss.accessKeySecret": ""
"spark.hadoop.fs.oss.accessKeyId": ""
Alibaba Cloud provides a Helm chart for you to deploy Spark history servers. To deploy a Spark history server, log on to the Container Service ACK console, choose Marketplace > Marketplace in the left-side navigation pane. On the App Catalog tab, search for and deploy ack-spark-history-server. When you deploy the Spark history server, you must specify the OSS information in the Parameters section. The following code shows an example:
oss:
enableOSS: true
# Please input your accessKeyId
alibabaCloudAccessKeyId: ""
# Please input your accessKeySecret
alibabaCloudAccessKeySecret: ""
# oss bucket endpoint such as oss-cn-beijing.aliyuncs.com
alibabaCloudOSSEndpoint: "oss-cn-beijing.aliyuncs.com"
# oss file path such as oss://bucket-name/path
eventsDir: "oss://bigdatastore/spark-events"After you deploy the Spark history server, you can view its external endpoint on the Services page. You can access the external endpoint of the Spark history server to view historical Spark jobs. 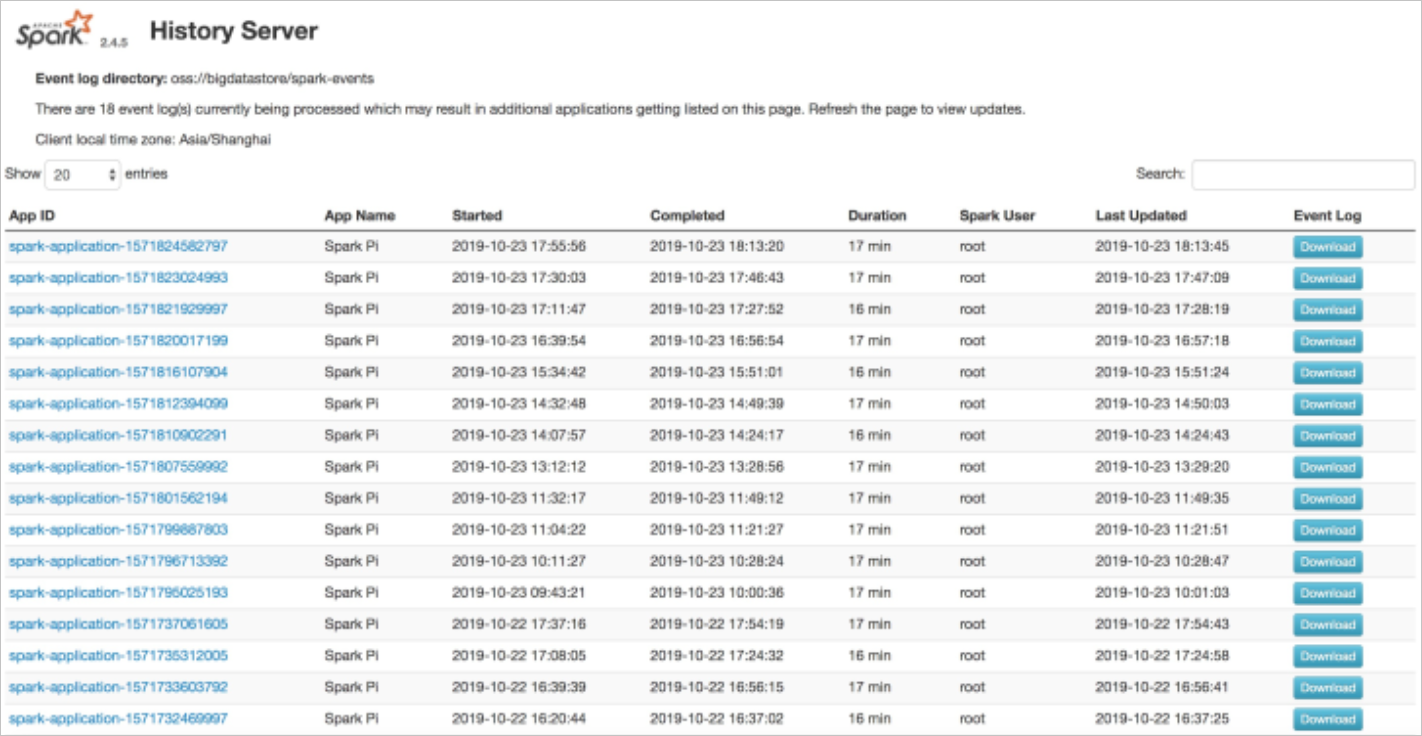
View the result of the Spark job
Query the status of the pods.
kubectl get podsExpected output:
NAME READY STATUS RESTARTS AGE spark-pi-1547981232122-driver 1/1 Running 0 12s spark-pi-1547981232122-exec-1 1/1 Running 0 3sQuery the real-time Spark user interface.
kubectl port-forward spark-pi-1547981232122-driver 4040:4040Query the status of the Spark application.
kubectl describe sparkapplication spark-piExpected output:
Name: spark-pi Namespace: default Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"sparkoperator.k8s.io/v1alpha1","kind":"SparkApplication","metadata":{"annotations":{},"name":"spark-pi","namespace":"default"...} API Version: sparkoperator.k8s.io/v1alpha1 Kind: SparkApplication Metadata: Creation Timestamp: 2019-01-20T10:47:08Z Generation: 1 Resource Version: 4923532 Self Link: /apis/sparkoperator.k8s.io/v1alpha1/namespaces/default/sparkapplications/spark-pi UID: bbe7445c-1ca0-11e9-9ad4-062fd7c19a7b Spec: Deps: Driver: Core Limit: 200m Cores: 0.1 Labels: Version: 2.4.0 Memory: 512m Service Account: spark Volume Mounts: Mount Path: /tmp Name: test-volume Executor: Cores: 1 Instances: 1 Labels: Version: 2.4.0 Memory: 512m Volume Mounts: Mount Path: /tmp Name: test-volume Image: gcr.io/spark-operator/spark:v2.4.0 Image Pull Policy: Always Main Application File: local:///opt/spark/examples/jars/spark-examples_2.11-2.4.0.jar Main Class: org.apache.spark.examples.SparkPi Mode: cluster Restart Policy: Type: Never Type: Scala Volumes: Host Path: Path: /tmp Type: Directory Name: test-volume Status: Application State: Error Message: State: COMPLETED Driver Info: Pod Name: spark-pi-driver Web UI Port: 31182 Web UI Service Name: spark-pi-ui-svc Execution Attempts: 1 Executor State: Spark - Pi - 1547981232122 - Exec - 1: COMPLETED Last Submission Attempt Time: 2019-01-20T10:47:14Z Spark Application Id: spark-application-1547981285779 Submission Attempts: 1 Termination Time: 2019-01-20T10:48:56Z Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SparkApplicationAdded 55m spark-operator SparkApplication spark-pi was added, Enqueuing it for submission Normal SparkApplicationSubmitted 55m spark-operator SparkApplication spark-pi was submitted successfully Normal SparkDriverPending 55m (x2 over 55m) spark-operator Driver spark-pi-driver is pending Normal SparkExecutorPending 54m (x3 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is pending Normal SparkExecutorRunning 53m (x4 over 54m) spark-operator Executor spark-pi-1547981232122-exec-1 is running Normal SparkDriverRunning 53m (x12 over 55m) spark-operator Driver spark-pi-driver is running Normal SparkExecutorCompleted 53m (x2 over 53m) spark-operator Executor spark-pi-1547981232122-exec-1 completedView the result of the Spark job in the log.
NAME READY STATUS RESTARTS AGE spark-pi-1547981232122-driver 0/1 Completed 0 1mIf the Spark application is in the Succeed state, or the Spark driver pod is in the Completed state, the result of the Spark job is available. You can print the log and view the result of the Spark job in the log.
kubectl logs spark-pi-1547981232122-driver Pi is roughly 3.152155760778804