MXNet allows you to perform distributed training by using KVStore and Horovod. AIACC-Training 1.5 can accelerate distributed training in MXNet by using KVStore and by calling Horovod APIs of all versions.
Quick start
Adapt and run training code
Horovod APIs are similar to the operations used in Horovod. If you have used Horovod to perform distributed training, you need to only change your training code in the import module to the following code:
import perseus.mxnet as hvdFor more information about how to adapt your training code to use Horovod APIs, see Adapt to Horovod APIs.
If you want to perform distributed training by using KVStore, you must adapt your training code to use KVStore APIs. For more information, see Adapt to KVStore APIs.
Example
AIACC-Training provides a sample of the adapted code in its software package. You can perform the following operations to start distributed training.
Go to the directory in which the sample code is stored.
cd `echo $(python -c "import perseus; print(perseus)") | cut -d\' -f 4 | sed "s/\_\_init\_\_\.py//"`examples/Start distributed training.
The following sample code shows how to start distributed training for a Mixed National Institute of Standards and Technology (MNIST) model. In this example, one machine that is configured with eight GPUs is used.
perseusrun -np 8 -H localhost:8 python $examples_path/mxnet_mnist.py
Adapt MXNet
Adapt to KVStore APIs
The following APIs are added to Perseus KVStore to support the data and model parallelism in InsightFace:
local_rank: returns the numerical identifier of the current GPU on the process. The numerical identifier can be used to create a GPU context. In Python, you can directly use the value of local_rank as a GPU ID to create a GPU context. This method is more convenient than the typical method of obtaining the numerical identifier of the current GPU from the started shell script and passing the numerical identifier to Python code described in Example.init(key_name, ndarray, param_only = false): You can add theparam_onlyparameter to init(). You can set the param_only parameter to the following values:true: synchronizes parameters other than gradients. If you need to synchronize parameters such as feature map data and AllReduce precision data at a time, or if you do not want to use KVStore to update parameters, you can add the
param_onlyparameter to init() and set param_only to true.false: synchronizes gradients.
push(key_name, ndarray, op = PerseusOp.Sum): You can add theopoutput parameter that is used to synchronize softmax layers to push(). Valid values: Sum, Max, and Min. Default value: Sum.
Use Perseus KVStore.
The following sample code provides an example that you can use to adapt your training code. To adapt the training code, perform the following operations: Add the
import perseus.mxnetmodule after the first plus sign (+), and replace the code after the minus sign (-) by using the code that is used to generate KVStore after the second plus sign (+).diff --git a/example/image-classification/common/fit.py b/example/image-classification/common/fit.py index 9412b6f..3a6e9a0 100755 --- a/example/image-classification/common/fit.py +++ b/example/image-classification/common/fit.py @@ -22,6 +22,7 @@ import time import re import math import mxnet as mx +import perseus.mxnet as perseus_kv def _get_lr_scheduler(args, kv): @@ -146,7 +147,8 @@ def fit(args, network, data_loader, **kwargs): # kvstore - kv = mx.kvstore.create(args.kv_store) + kv = perseus_kv.create(args.kv_store) if args.kv_store == dist_sync_perseus else mx.kvstore.create(args.kv_store) if args.gc_type != 'none': kv.set_gradient_compression({'type': args.gc_type, 'threshold': args.gc_threshold})Bind the current process to a GPU.
AIACC-Training is compatible with KVStore APIs and reloads KVStore to support distributed training in MXNet. After you use AIACC-Training, you need to only modify the context settings in the model code to bind a process to a GPU.
The following sample code shows how to use local_rank to bind the current process to a GPU that corresponds to the value of
kv.local_rank. local_rank is a new API that is added to Perseus KVStore.ctx = [] cvd = os.environ['DEVICES'].strip() if 'perseus' in args.kv_store: import perseus.mxnet as perseus ctx.append(mx.gpu(kv.local_rank))Start distributed training.
Message Passing Interface (MPI) is the preferred choice for starting distributed training in frameworks. In Perseus, single-machine multi-GPU training and multi-machine multi-GPU training are started in a similar way by using MPI. Perseus no longer supports single-machine multi-GPU training performed in a single process in MXNet. The following sample code shows how to start distributed training. In this example, four machines are used and each machine is configured with eight GPUs.
Prepare the
config.shtraining script.You must run the
mpiruncommand to use the script. Therefore, you must specify the MPI environment variable that is used to infer the GPU ID of the process, and pass the ID to the model code to create the GPU context. Sample script:#!/bin/sh let GPU=OMPI_COMM_WORLD_RANK % OMPI_COMM_WORLD_LOCAL_SIZE export OMP_NUM_THREADS=4 MXNET_VISIBLE_DEVICE=$GPU python train_imagenet.py \ --network resnet \ --num-layers 50 \ --kv-store dist_sync_perseus \ --gpus $GPU …Run the following command to start the training script:
mpirun –np 32 –npernode 8 –hostfile mpi_host.txt ./config.shIn the preceding command, mpi_host.txt is a regular MPI machine file and is similar to the host file of MXNet SSHLauncher. Sample code of mpi_host.txt:
192.168.0.1 192.168.0.2 192.168.0.3 192.168.0.4After you start training, each GPU works as a process and returns its independent output. The overall training performance is evaluated by the output of each machine.
By default, open source MXNet occupies all CPU resources in your system. This increases the CPU time required to start training jobs. To accelerate the startup speed, you can configure the following environment variables:
export MXNET_USE_OPERATOR_TUNING=0 export MXNET_USE_NUM_CORES_OPERATOR_TUNING=1 export OMP_NUM_THREADS=1
Adapt to Horovod APIs
This section describes how to call Horovod APIs to perform distributed training in MXNet and how to adapt your original training code for AIACC-Training.
AIACC-Training for MXNet supports Horovod APIs. Horovod APIs are similar to the operations used in Horovod. If you have used Horovod to perform distributed training, you need to only change your training code in the import module to the following code:
import perseus.mxnet as hvdIf your training code is not written to perform distributed training, you can perform the following operations to upgrade your code to the code for distributed training that is compatible with Horovod APIs.
In the first part of the main() function, run the following command to initialize the Perseus Horovod module.
NoteMake sure that you run the command before you call other Perseus APIs.
hvd.init()Bind the current process to a GPU.
# rank and size rank = hvd.rank() num_workers = hvd.size() local_rank = hvd.local_rank() # Horovod: pin GPU to local rank context = mx.gpu(local_rank)Create an optimizer.
In most cases, the learning rate of a model must be multiplied by the value of hvd.size().
NoteYou do not need to increase the learning rate of specific models, such as the Bidirectional Encoder Representations from Transformers (BERT) model. You can determine whether to increase the learning rate based on the training convergence results.
learning_rate = ... optimizer_params = {'learning_rate': learning_rate * hvd.size()} opt = mx.optimizer.create(optimizer, **optimizer_params)Broadcast parameters.
# Horovod: fetch and broadcast parameters params = net.collect_params() if params is not None: hvd.broadcast_parameters(params)Reload the optimizer.
# Horovod: create DistributedTrainer, a subclass of gluon.Trainer trainer = hvd.DistributedTrainer(params, opt)Start training.
In this example, four machines are used and each machine is configured with eight GPUs. Sample code:
mpirun –np 32 –npernode 8 –hostfile mpi_host.txt ./train.shIn the preceding command, mpi_host.txt is a regular MPI machine file and is similar to the host file of MXNet SSHLauncher. Sample code of mpi_host.txt:
192.168.0.1 192.168.0.2 192.168.0.3 192.168.0.4After you start training, each GPU works as a process and returns its independent output. The overall training performance is evaluated by the output of each machine.
Use SyncBatchNorm
To implement Synchronized Batch Normalization (SyncBatchNorm) in Perseus, use the official MXNet code src/operator/contrib/sync_batch_norm-inl.h and load libperseus_MXNet.so to call the communication APIs of Perseus. This way, SyncBatchNorm is implemented within operators. SyncBatchNorm supports local and global modes.
Background information
In scenarios in which the batch size is small, such as object detection scenarios, the mean value and variance calculated by BatchNorm on each GPU have large deviations. This results in an accuracy loss. SyncBatchNorm can adjust internal deviations of statistics and ensure the performance of the batch normalization (BN) layer. Even if in large scale distributed training scenarios, SyncBatchNorm can achieve higher precision than BatchNorm. Compared with BatchNorm, SyncBatchNorm can improve convergence precision when overall training performance is ensured.
Procedure
Use the perseus-MXNet-sync-bn.patch patch.
patch -p1 < perseus-mxnet-sync-bn.patchCompile the MXNet source code.
make USE_OPENCV=1 USE_BLAS=openblas USE_CUDA=1 USE_CUDA_PATH=/usr/local/cuda USE_CUDNN=1 USE_DIST_KVSTORE=1 USE_NCCL=1 USE_LIBJPEG_TURBO=1 MPI_ROOT=/usr/local -j24Invoke SyncBatchNorm().
PerseusSyncBatchNorm is implemented based on the official MXNet code. Therefore, PerseusSyncBatchNorm is compatible with SyncBatchNorm. To change the synchronization mode, change SyncBatchNorm to PerseusSyncBatchNorm and add the
comm_scopeparameter to the command. For example, you can setcomm_scope to 0 when you use mx.gluon.contrib.nn.PerseusSyncBatchNorm() or set comm_scope to 0 when you use mx.sym.contrib.PerseusSyncBatchNorm().Change the mode.
The following information describes local and global modes:
Local mode: local average. After the mean value and variance are calculated forward and backward each time, the results are synchronized among GPUs on a single machine. This is the default mode. To use the local mode, set comm_scope to 0 when you use PerseusSyncBatchNorm().
Global mode: global average. After the mean value and variance are calculated forward and backward each time, the results are synchronized among GPUs on all machines. To use the global mode, set comm_scope to 1 when you use PerseusSyncBatchNorm().
Test the precision
The following figure compares the precision between BatchNorm and PerseusSyncBatchNorm. In this example, a Faster R-CNN model implemented based on GluonCV and adapted to Perseus is used. One machine configured with eight GPUs is used, and the batch size of each GPU is 2.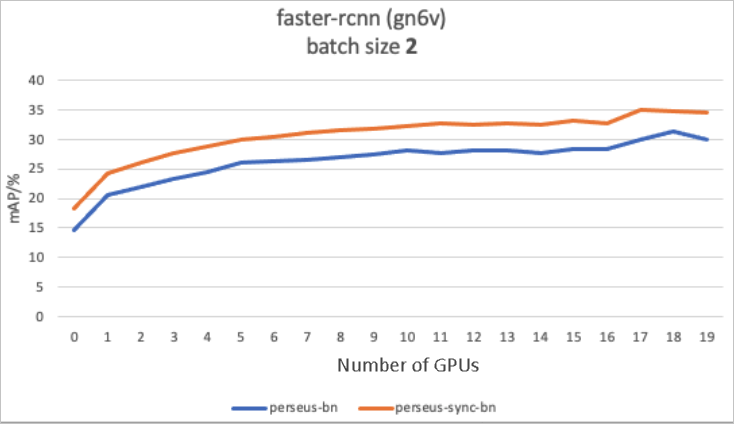
In the preceding figure, the precision achieved by PerseusSyncBatchNorm is higher than the precision achieved by BatchNorm from the 1st epoch to the 20th epoch. The highest mAP rises from 31.3% to 34.6%.
FAQ
What do I do when the memory of a GPU is occupied by other processes?
For example, you use a machine that is configured with eight GPUs. If the memory of GPU 0 is occupied by the remaining seven processes and the GPU memory occupied by each process ranges from 200 MB to 500 MB, no memory is available on GPU 0.
GPU memory in MXNet is allocated based on the built-in cpu_pinned memory mechanism. By default, the memory of GPU 0 is allocated to the processes. You can bind processes to different GPUs. For more information, see Step 2.
What do I do if the system reports the Undefined symbols error?
The error indicates that the symbols related to N-dimensional array (NDArray) are not defined.
The system reports the error because MXNet 1.4 or earlier is installed in your pip. As a result, the symbols required by Perseus are not exported from libMXNet.so. You can upgrade MXNet to MXNet 1.4 or later, or recompile MXNet and install it again.
What do I do if the system takes a long period of time to start the training script?
You can perform the following operations to accelerate the startup speed of the training script:
Check the CPU load. If the CPU load is heavy, you can configure the following environment variables:
export MXNET_USE_OPERATOR_TUNING=0 export MXNET_USE_NUM_CORES_OPERATOR_TUNING=1 export OMP_NUM_THREADS=1Reduce the number of threads for the preprocess function.
Perseus runs training jobs as a single process in which single-machine single-GPU training is performed. If the default number of threads is too large, you can reduce the number of threads for the preprocess function proportionally based on the number of GPUs on the machine. For example, if the default number of threads for the preprocess function is 24, and the number of GPUs on your machine is 8, you can reduce the number of threads for the preprocess function to 3 or 4.
What do I do if training is performed on a single machine but fails to be performed on multiple machines?
The system reports the create cusolver handle failed error because specific machines that you use for a training job are occupied by another training job. In this case, you can run nvidia-smi by using mpirun to check whether the machines are occupied.