Elastic GPU Service gives you GPU-accelerated instances with high compute density, low-latency networking, and flexible billing—plus DeepGPU, a free toolkit that accelerates training and inference workloads without requiring code changes.
Elastic GPU Service
Global deployment across 17 regions. Deploy GPU-accelerated instances at scale in 17 regions worldwide. Auto provisioning and auto scaling handle sudden demand spikes without manual intervention.
Up to 1,000 TFLOPS of mixed-precision compute. When combined with a high-performance CPU platform, GPU-accelerated instances deliver up to 1,000 trillion floating point operations per second (TFLOPS) of mixed-precision computing performance—enough for large-scale large language model (LLM) training and high-throughput inference.
Two-tier networking for every workload type. Each GPU-accelerated instance connects to a virtual private cloud (VPC) with up to 32 Gbit/s of internal bandwidth and 4.5 million packets per second (Mpps) for general workloads. For distributed training tasks, pair instances with Super Computing Cluster (SCC) to add up to 50 Gbit/s of Remote Direct Memory Access (RDMA) bandwidth between nodes—keeping gradient synchronization off the bottleneck.
Billing that matches your usage pattern. Choose from subscription, pay-as-you-go, preemptible instances, reserved instances, and storage capacity units (SCUs) to fit your cost model. Combine billing methods to cover both steady-state and burst workloads.
DeepGPU
DeepGPU is a free toolkit that accelerates GPU workloads on Elastic GPU Service. It includes Deepytorch, AIACC-ACSpeed (ACSpeed), AIACC-AGSpeed (AGSpeed), FastGPU, and cGPU.
FastGPU
FastGPU is a cluster deployment tool that automates infrastructure setup so you can run AI training and inference tasks without manually provisioning compute, storage, or network resources.
Clusters ready in 5 minutes. FastGPU deploys a fully configured cluster in 5 minutes. All resources are provisioned at the infrastructure layer and are directly accessible for debugging.
Resource lifecycle tied to task lifecycle. FastGPU releases GPU-accelerated instances automatically when a training or inference task ends. Preemptible instances are supported to reduce costs.
Full observability. FastGPU provides visualization, log management, and task tracing so every run is auditable.
cGPU
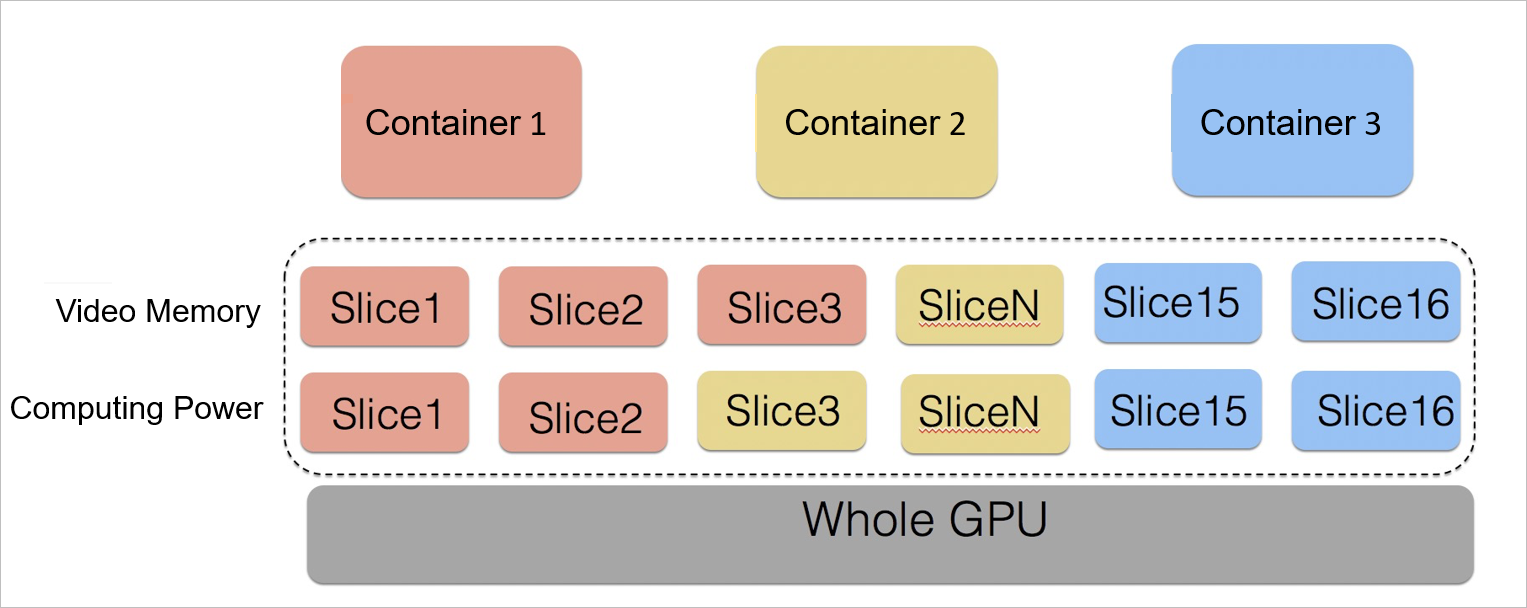
cGPU lets multiple containers share a single physical GPU with strict resource isolation, improving GPU utilization, reducing costs, and improving security.
Share one GPU across containers without exposing business data. Most AI workloads do not need an entire GPU. cGPU allocates GPU resources across containers while isolating each container's data, so you pay only for the GPU memory and computing power each workload actually uses.
Flexible allocation by GPU memory or computing power. Allocate resources based on GPU memory or computing power ratios to match each container's requirements.
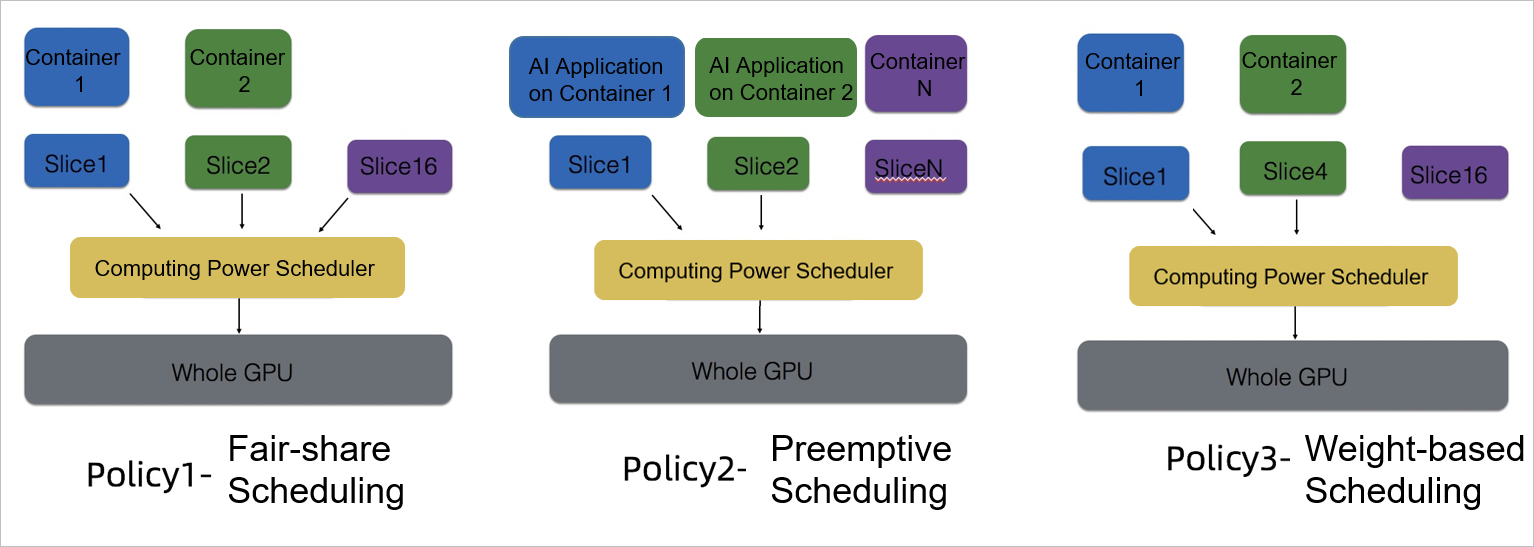
Three switchable scheduling policies for peak and off-peak hours. Switch between three computing power allocation policies in real time to match workload intensity—no restarts required.