This topic describes how to run Spark Streaming jobs to process Kafka data in real-time from an E-MapReduce (EMR) Dataflow cluster that contains the Kafka service.
Prerequisites
EMR is activated.
The required roles are assigned to EMR by using your Alibaba Cloud account. For more information, see Assign roles.
Step 1: Create a DataLake cluster and a Dataflow cluster
Create a DataLake cluster and a Dataflow cluster that belong to the same security group. The Dataflow cluster must contain the Kafka service. For more information, see Create a cluster.
Create a DataLake cluster.
NoteIn this example, Spark 3 is deployed in the DataLake cluster.

Create a Dataflow cluster.
NoteMake sure that the Kafka service is selected. The system selects the Kafka-Manager and ZooKeeper services on which the Kafka service depends.

Step 2: Obtain the required JAR package and upload it to the DataLake cluster
Obtain the JAR package spark-streaming-demo-1.0.jar.
Upload the JAR package to the
/home/emr-userpath of the master node in the DataLake cluster.
Step 3: Create a topic on the Dataflow cluster
In this example, a topic named test is created.
Log on to the master node of the Dataflow cluster. For more information, see Log on to a cluster.
Run the following command to create a topic:
kafka-topics.sh --create --bootstrap-server core-1-1:9092,core-1-2:9092,core-1-3:9092 --replication-factor 2 --partitions 2 --topic demoNoteAfter you create the topic, keep the logon window open for later use.
Step 4: Run a Spark Streaming job
In this example, a WordCount job is run for streaming data.
Log on to the master node of the DataLake cluster. For more information, see Log on to a cluster.
Run the following command to go to the emr-user directory:
cd /home/emr-userRun the following command to submit a WordCount job for streaming data:
spark-submit --class com.aliyun.emr.KafkaApp1 ./spark-streaming-demo-1.0.jar <Internal IP address of a Kafka broker>:9092 demogroup1 demoThe following table describes key parameters.
Parameter
Description
<The internal IP address of a Kafka broker component in the Kafka cluster>:9092The internal IP address and port number of a broker in the Dataflow cluster. The default port number is 9092. Example:
172.16.**.**:9092,172.16.**.**:9092,172.16.**.**:9092.To view the internal IP addresses of all brokers, go to the Status tab of the Kafka service page, find KafkaBroker, and then click the
 icon to the left of KafkaBroker.
icon to the left of KafkaBroker. demogroup1The name of the Kafka consumer group. You can modify the name based on your business requirements.
demoThe topic name.
Step 5: Use Kafka to publish messages
In the command-line interface (CLI) of the Dataflow cluster, run the following command to start the Kafka producer:
kafka-console-producer.sh --topic demo --bootstrap-server core-1-1:9092,core-1-2:9092,core-1-3:9092Enter text information in the logon window of the Dataflow cluster. Text statistics are displayed in the logon window of the DataLake cluster in real time.
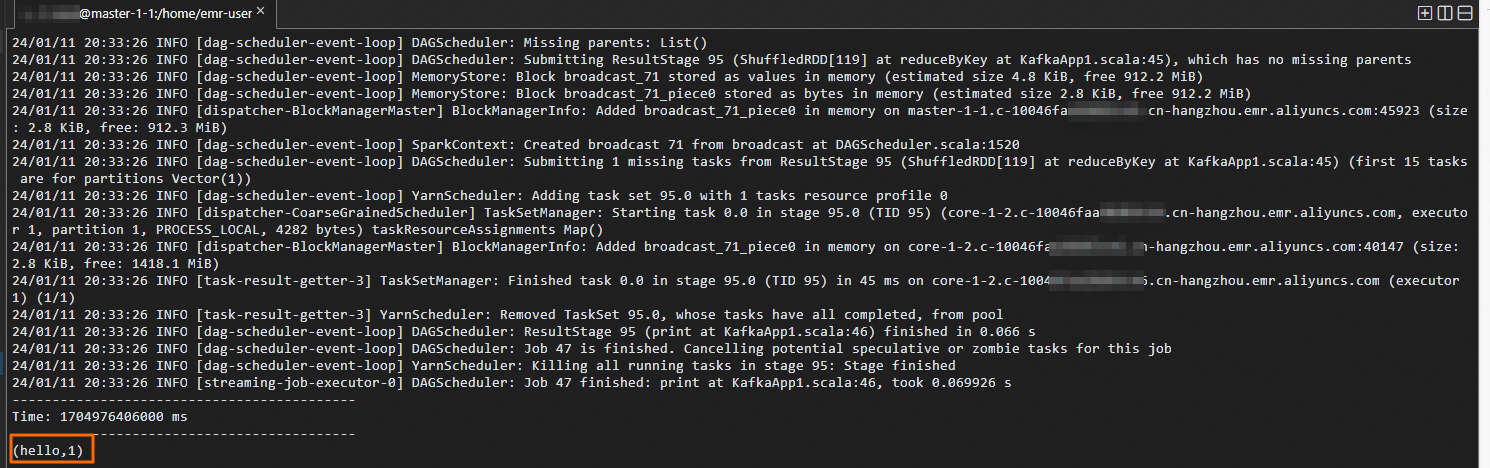
For example, enter the information shown in the following figure to the logon window of the Dataflow cluster.

The information shown in the following figure is displayed in the logon window of the DataLake cluster.
Step 6: View the status of the Spark Streaming job
On the EMR on ECS page, click the name of the DataLake cluster.
On the page that appears, click Access Links and Ports.
Access the web UI of Spark. For more information, see Access the web UIs of open source components.
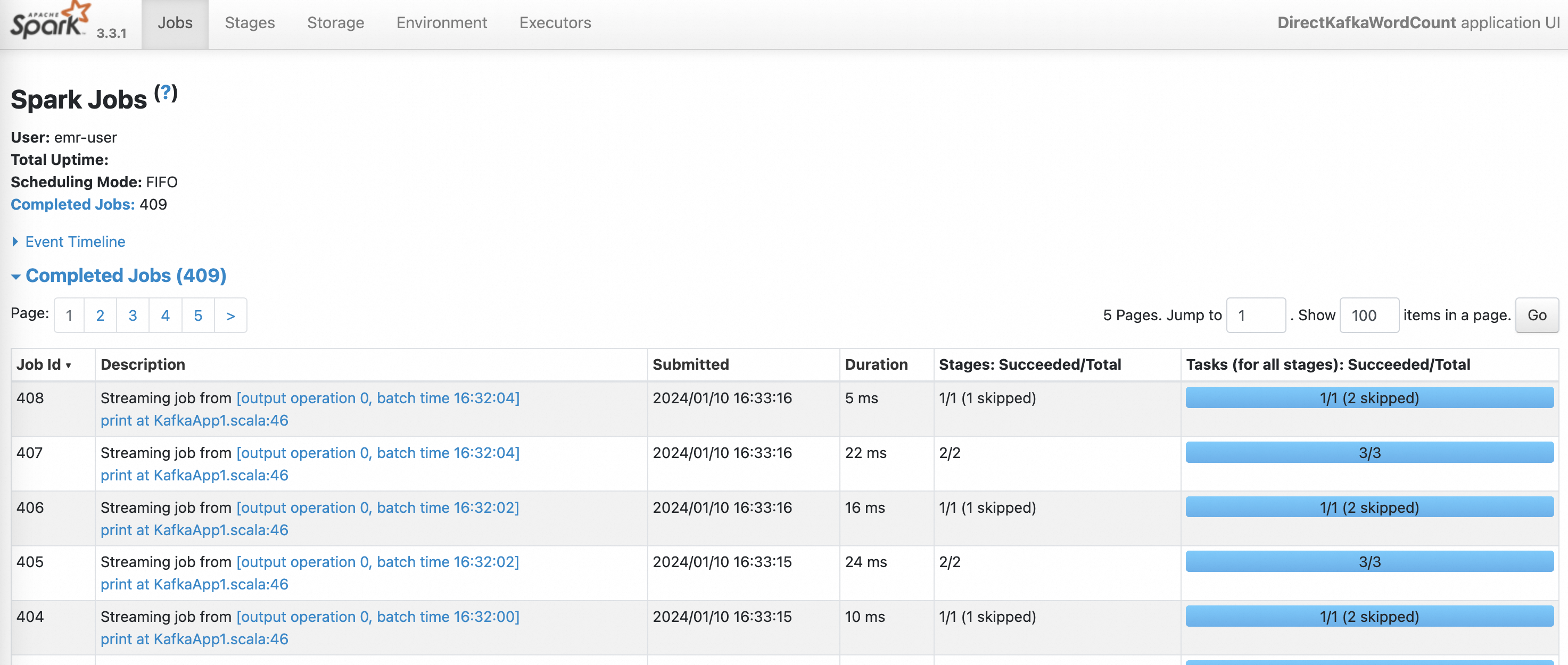
On the History Server page, click the App ID of the Spark Streaming job that you want to view.
You can view the status of the Spark Streaming job.