Business data changes over time. To analyze business data, you must consider how to store and manage the data. A dimension that slowly changes over time is a slowly changing dimension (SCD). Granularity-based slowly changing dimensions (G-SCDs) are defined in E-MapReduce (EMR) based on data warehousing scenarios. This topic describes the G-SCD solution and also describes how to process dimensional data by using the G-SCD solution.
Background information
Introduction to SCDs
An SCD is a dimension that slowly changes over time. To store and manage current data and historical data in a data warehouse, you must appropriately process SCDs. SCDs are considered one of the most important extract, transform, load (ETL) tasks that are used to track dimensional changes.
| Type | Description |
|---|---|
| Type 1: Overwrite historical values | Use new values to overwrite historical values. The historical values are not retained. You cannot use this type of SCD to analyze historical changes. |
| Type 2: Add a dimension row | Retain all historical values. Each time an attribute value changes, a record is added and marked as the valid record. The validity fields of the original valid record are modified. In most cases, you can use the fields that specify the start time and end time as the validity fields of records. |
| Type 3: Add an attribute column | Add a field to retain the original value of an existing field. A column is added to record the original value of an attribute, and the original attribute field records the new value. This way, you can analyze the historical information of the attribute. |
G-SCD solution
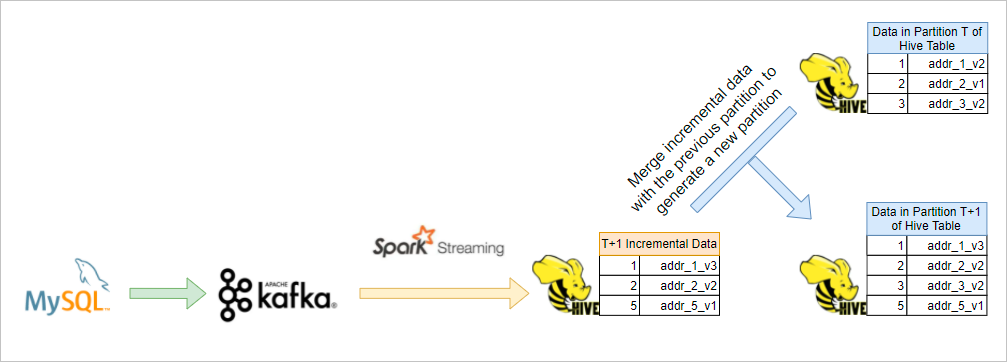
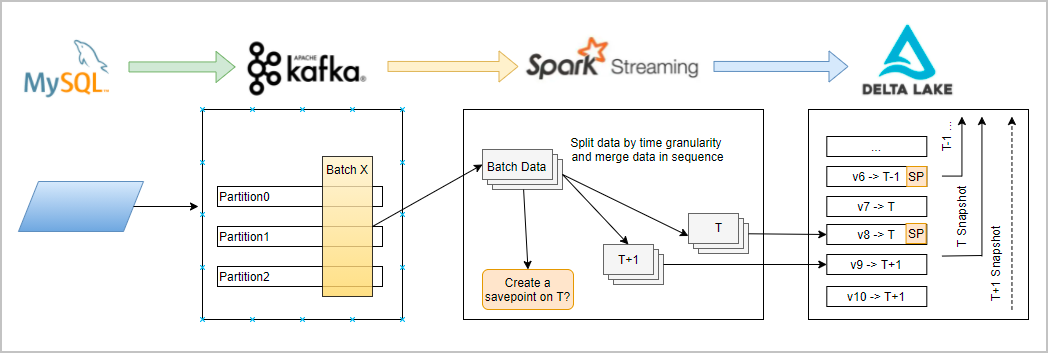
The three methods in which SCDs are used to process new values may not be suitable for some business scenarios. EMR provides the G-SCD solution, which supports SCDs based on fixed granularities or business snapshots in data warehousing scenarios. A G-SCD generates business snapshots based on a fixed time granularity. The granularity can be days, hours, or minutes. A G-SCD also allows you to query the data that is generated in a specified time range based on the configured time granularity.
| Solution | Disadvantage |
|---|---|
| Solution 1: Build an incremental data table of the T+1 point in time in streaming mode and merge data in the incremental data table with data in the T partition of an offline table. This way, a T+1 partition is generated in the offline table. | A large number of storage resources are required. |
| Solution 2: Store an offline base table, separately store incremental data tables, and merge the base table with incremental data tables only when users query data. | The query performance is poor. |
| Solution | Similarity | Difference |
|---|---|---|
| Type 2 SCD | All historical information is retained. | Each time an attribute value changes, a record is added. |
| G-SCD | The G-SCD solution does not add records to retain information. Instead, the solution uses the Time Travel feature of Delta Lake to trace snapshot data. The Time Travel feature supports data versioning. |
- Integration of stream processing and batch processing: You do not need to separately manage incremental data tables and base tables.
- Low costs of storage resources: You do not need to retain all historical data based on a time granularity.
- High query performance: You can use the Optimize, Z-ordering, and Data Skipping features of Delta Lake to improve query performance.
- High SQL compatibility: The G-SCD solution is compatible with the SQL statements that you can use in the SCD solution of Hive. In the G-SCD solution, a field functions in a similar manner to a partition field. You can use this field to query snapshot data that corresponds to a specified time range.
Prerequisites
An EMR cluster is created. For more information, see Create a cluster.
Limits
- Messages in each Kafka partition must be stored in the order in which they are sent.
- Messages that have the same key must be stored in the same Kafka partition.
Procedure
- Step 1: Create a G-SCD tableCreate a G-SCD table and configure the table parameters based on your business requirements.
- Step 2: Process dataWrite data to the table in streaming mode or batch mode based on your business requirements. This topic provides an example on how to run two batch-write jobs to simulate the data write process of the G-SCD solution. In the example, the two batch-write jobs can achieve the same effect as a streaming write job.
- Step 3: Check whether data is written to the tableExecute query statements to check whether data is written to the table.
Step 1: Create a G-SCD table
CREATE TABLE target (id Int, body String, dt string)
USING delta
TBLPROPERTIES (
"delta.gscdTypeTable" = "true",
"delta.gscdGranularity" = "1 day",
"delta.gscdColumnFormat" = "yyyy-MM-dd",
"delta.gscdColumn" = "dt"
);| Parameter | Description |
|---|---|
| delta.gscdTypeTable | Specifies whether the table is a G-SCD table. In this example, set the parameter to true. If you set this parameter to false, a common table is created, and you cannot use the features of the G-SCD solution. |
| delta.gscdGranularity | The time granularity based on which business snapshots are created. For example, you can set this parameter to 1 day, 1 hour, or 30 minutes. |
| delta.gscdColumnFormat | The time format of a business snapshot. Valid values:
|
| delta.gscdColumn | The field that specifies the version of a business snapshot. You must define this field in the table schema. This field must be of the STRING type. |
Step 2: Process data
Write data to the table in streaming mode or batch mode based on your business requirements.
- Write data in streaming mode
CREATE TABLE IF NOT EXISTS gscd_kafka_table USING kafka OPTIONS( kafka.bootstrap.servers = 'localhost:9092', subscribe = 'xxxxxx' ); CREATE SCAN gscd_stream ON gscd_kafka_table USING STREAM OPTIONS ( `watermark.time` = 'floor(ts/1000)' --- Define the watermark time expression for source data. Unit: seconds. ); CREATE STREAM delta_job OPTIONS ( triggerType = 'ProcessingTime', checkpointLocation = '/path/to/checkpoint' ) MERGE INTO gscd_target_table AS target USING ( SELECT *, from_unixtime(ts/1000, 'yyyy-MM-dd') AS dt FROM gscd_stream ) AS source ON source.id = target.id AND target.dt = source.dt WHEN MATCHED THEN update set * WHEN NOT MATCHED THEN insert *;Important When you define the watermark time expression in the CREATE SCAN statement, take note of the following points:- To make sure that savepoints can be automatically created in the streaming job, you must define a watermark time expression in the
CREATE SCANstatement. - The watermark.time parameter specifies the time value of the input source of the streaming job. Unit: seconds.
- The generated watermark time is used as the value of the field that is specified by the delta.gscdColumn parameter. When the watermark time reaches the value of delta.gscdGranularity (1 day in this example), a savepoint is automatically created.
- In each partition, the watermark time increases as new messages are sent.
- To make sure that savepoints can be automatically created in the streaming job, you must define a watermark time expression in the
- Write data in batch mode
In most cases, you can run a streaming job to write data. However, if a data exception occurs in a streaming job, the G-SCD solution allows you to roll back data and write the restored data in batch mode. After the data is written, you must execute the CREATE SAVEPOINT statement to permanently retain the current version of the data.
MERGE INTO GSCD("2021-01-01") gscd_target_table USING gscd_source_table ON source.id = target.id WHEN MATCHED THEN UPDATE SET body = source.body WHEN NOT MATCHED THEN INSERT(id, body) VALUES(source.id, source.body);In the preceding SQL statement,
GSCD ("2021-01-01")indicates the G-SCD to which you want to write data. Each G-SCD corresponds to a time range.Important You are not allowed to use one batch-write job to write data to multiple G-SCDs. If you want to write data to multiple G-SCDs, you must split the data in advance and run multiple jobs.
The following example shows how to use the G-SCD solution to process dimensional data.
- Prepare source data.
CREATE TABLE s1 (id Int, body String) USING delta; CREATE TABLE s2 (id Int, body String) USING delta; INSERT INTO s1 VALUES (1, "addr_1_v1"), (2, "addr_2_v1"), (3, "addr_3_v1"); INSERT INTO s2 VALUES (2, "addr_2_v2"), (4, "addr_1_v1"); - Run two batch-write jobs to simulate the data write process of the G-SCD solution. The two batch-write jobs can achieve the same effect as a streaming write job.
Step 3: Check whether data is written to the table
Execute query statements to check whether data is written to the table. Perform the following steps to query the data that is written in Step 2: Process data:
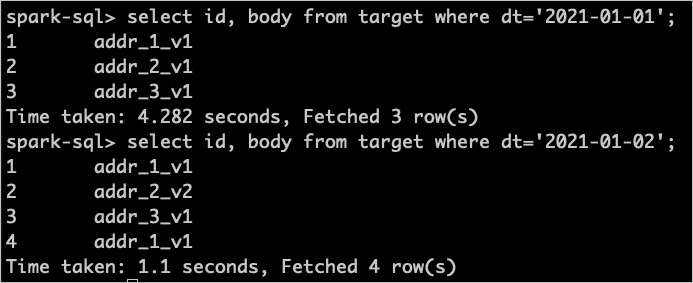
- Execute the following statement to query the data that is written in the first batch-write job:
select id, body from target where dt = '2021-01-01';Important- You can use common SQL syntax to query data.
- In the query statement, you must configure the field specified by the gscdColumn parameter as a query condition. In this example,
dt = '2021-01-01'is used.
- Execute the following statement to query the data that is written in the second batch-write job:
select id, body from target where dt = '2021-01-02';If the data that you write is returned, the data is written to the table. The following figure shows the query results in this example.