This topic describes how to use Intel MPI Benchmarks (IMB) and a Message Passing Interface (MPI) library to test the communication performance of an Elastic High Performance Computing (E-HPC) cluster.
Background information
IMB is a software application that is used to measure the performance of point-to-point and global communication in an HPC cluster for various granularities of messages.
MPI is a standardized and portable message-passing standard for parallel computing. MPI supports multiple programming languages and provides benefits such as high performance, concurrency, portability, and scalability.
Preparations
Create an SCC-based E-HPC cluster. For more information, see Create a cluster by using the wizard.
Configure the following parameters.
Parameter
Description
Hardware settings
Deploy a tiny cluster that consists of one management node and two compute nodes. Specify an Elastic Compute Service (ECS) instance type that has eight or more vCPUs as the compute node. In this example, two ecs.c7.2xlarge instances are used.
Software settings
Deploy a CentOS 7.6 public image and the PBS scheduler.
Create a cluster user. For more information, see Create a user.
The user is used to log on to the cluster, compile LAMMPS, and submit jobs. In this example, the following information is used to create the user:
Username: mpitest
User group: sudo permission group
Install software. For more information, see Install software.
Install the following software:
Intel MPI 2018
Intel MPI Benchmarks 2019
Step 1: Connect to the cluster
Connect to the cluster by using one of the following methods: This example uses mpitest as the username. After you connect to the cluster, you are automatically logged on to the /home/mpitest.
Use an E-HPC client to log on to a cluster
The scheduler of the cluster must be PBS. Make sure that you have downloaded and installed an E-HPC client and deployed the environment required for the client. For more information, see Deploy an environment for an E-HPC client.
Start and log on to your E-HPC client.
In the left-side navigation pane, click Session Management.
In the upper-right corner of the Session Management page, click terminal to open the Terminal window.
Use the E-HPC console to log on to a cluster
Log on to the E-HPC console.
In the upper-left corner of the top navigation bar, select a region.
In the left-side navigation pane, click Cluster.
On the Cluster page, find the cluster and click Connect.
In the Connect panel, enter a username and a password, and click Connect via SSH.
Step 2: Submit a job
Run the following command to create a job script file named IMB.pbs:
vim IMB.pbsSample script:
#!/bin/sh #PBS -j oe #PBS -l select=2:ncpus=8:mpiprocs=1 export MODULEPATH=/opt/ehpcmodulefiles/ module load intel-mpi/2018 module load intel-mpi-benchmarks/2019 echo "run at the beginning" /opt/intel/impi/2018.3.222/bin64/mpirun -genv I_MPI_DEBUG 5 -np 2 -ppn 1 -host compute000,compute001 /opt/intel-mpi-benchmarks/2019/IMB-MPI1 pingpong > IMB-pingpong # Replace the parameters with the actual configuration.# In this example, two compute nodes are used for the test. Each node uses eight vCPUs and one MPI to run high-performance computing jobs. Specify the
#PBS -l select=2:ncpus=8:mpiprocs=1parameter based on the actual node configuration.Specify the parameters of the
/opt/intel/impi/2018.3.222/bin64/mpiruncommand in the script based on your requirements. Set the following parameters:-ppn: the number of processes per node.
-host: the job node list.
-npmin: the minimum number of processes that can be run.
-msglog: the range of segment granularities.
NoteYou can run the
/opt/intel-mpi-benchmarks/2019/IMB-MPI1 -hcommand to view the parameter descriptions of IMB and the communication modes that IMB supports.Examples:
Example 1: Test the performance of all-reduce communication between N nodes. On each node, two processes are started to obtain the time consumed to communicate messages of various message granularities.
/opt/intel/impi/2018.3.222/bin64/mpirun -genv I_MPI_DEBUG 5 -np <N*2> -ppn 2 -host <node0>,...,<nodeN> /opt/intel-mpi-benchmarks/2019/IMB-MPI1 -npmin 2 -msglog 19:21 allreduceExample 2: Test the performance of all-to-all communication among N nodes. On each node, a process is started to obtain the time consumed to communicate messages of various granularities.
/opt/intel/impi/2018.3.222/bin64/mpirun -genv I_MPI_DEBUG 5 -np <N> -ppn 1 -host <node0>,...,<nodeN> /opt/intel-mpi-benchmarks/2019/IMB-MPI1 -npmin 1 -msglog 15:17 alltoall
Run the following command to submit the job:
qsub imb.pbsThe following command output is returned, which indicates that the generated job ID is 0.scheduler:
0.manager
Step 3: View the job result
View the running state of the jobs.
qstat -x 0.managerA response similar to the following code is returned, where an
Rin theScolumn indicates that the job is running, and anFin theScolumn indicates that the job is completed.Job id Name User Time Use S Queue ---------------- ---------------- ---------------- -------- - ----- 0.manager imb.pbs mpitest 00:00:04 F workqView the job result.
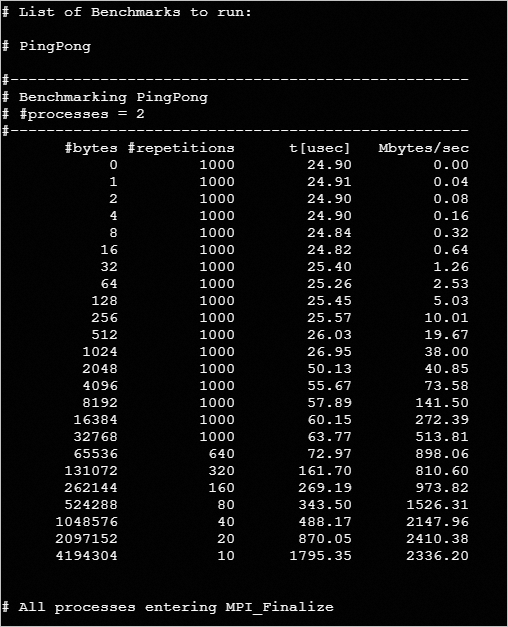
cat /home/mpitest/IMB-pingpongThe following results are generated in the test: