Data Transmission Service (DTS) supports data migration, change tracking, and data synchronization in various scenarios.
Data migration with minimized downtime
Transmission mode: data migration
In traditional data transmission scenarios, you must stop writing data to the source database during data migration to ensure data consistency. The data migration process may take hours or days to complete. It depends on the amount of data and network conditions. This time-consuming process may significantly affect your business.
DTS minimizes downtime during data migration. Your application can remain operational in this process. Downtime occurs only when you switch the application to the destination database. The switchover time can be reduced to minutes. The following figure shows a complete data migration process in DTS.
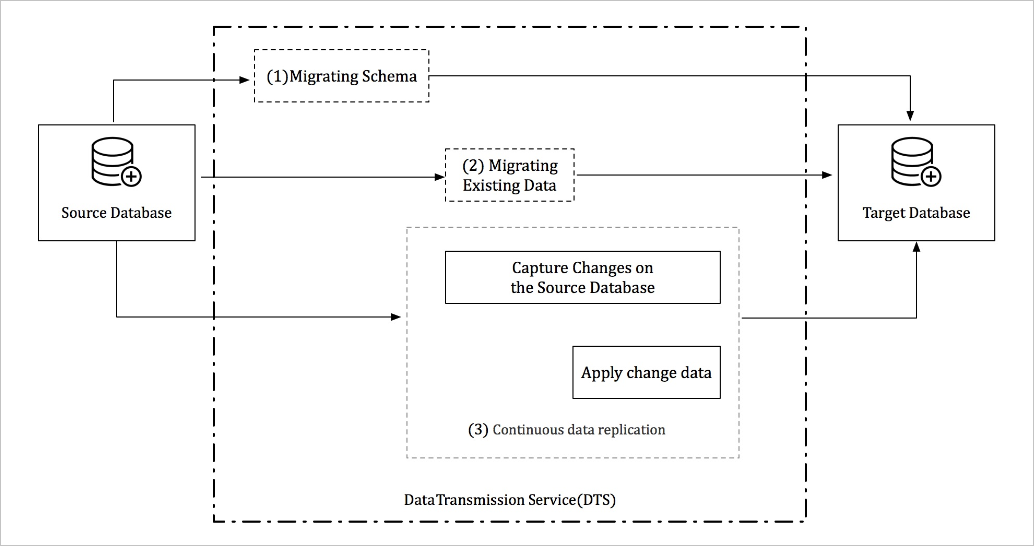
A complete data migration process consists of schema migration, full data migration, and incremental data migration. During incremental data migration, changes in the source database are synchronized to the destination database in real time. After the data migration is complete, you can verify whether the data and schema migrated to the destination database are fully compatible with your application. If the compatibility verification succeeds, you can switch the application to the destination database without service interruption.
Geo-disaster recovery
Transmission mode: data synchronization
If your application is deployed within a single region, the service may be interrupted due to force majeure factors, such as power outages and network failures.
In that case, you can set up a disaster recovery center in another region to improve service availability. DTS keeps synchronizing data and replicas between the two regions. If a failure occurs in the primary region of your application, you can turn to the facilities in the disaster recovery region to process user requests.
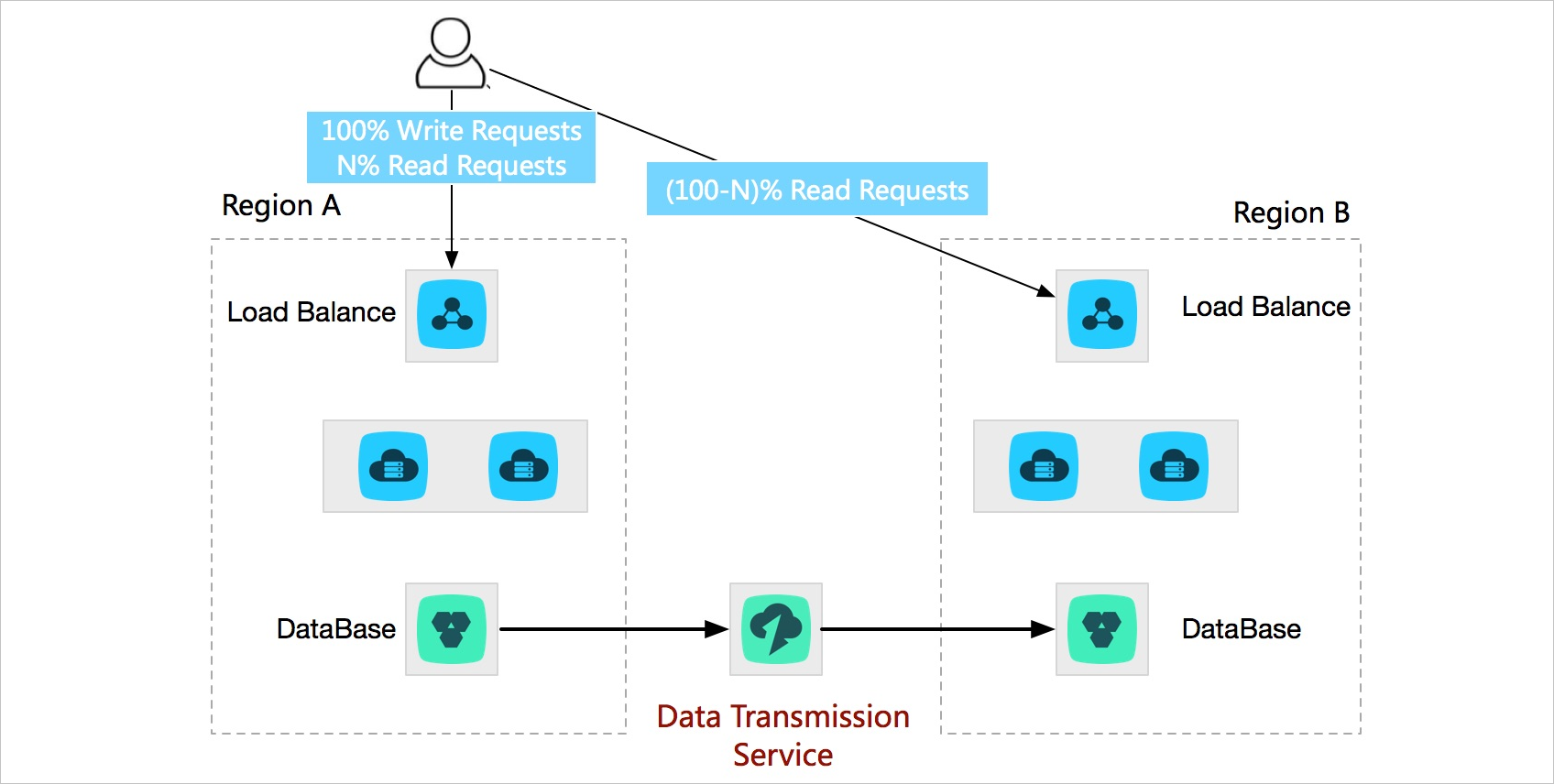
Active geo-redundancy
As your business grows, you may encounter the following issues if you deploy your business in a single region:
- Users are distributed across a wide range of geographical locations and distant users have high access latency. This compromises user experience.
- Business scalability is limited by the capacity of infrastructure in a single region, such as power supply and network bandwidth.
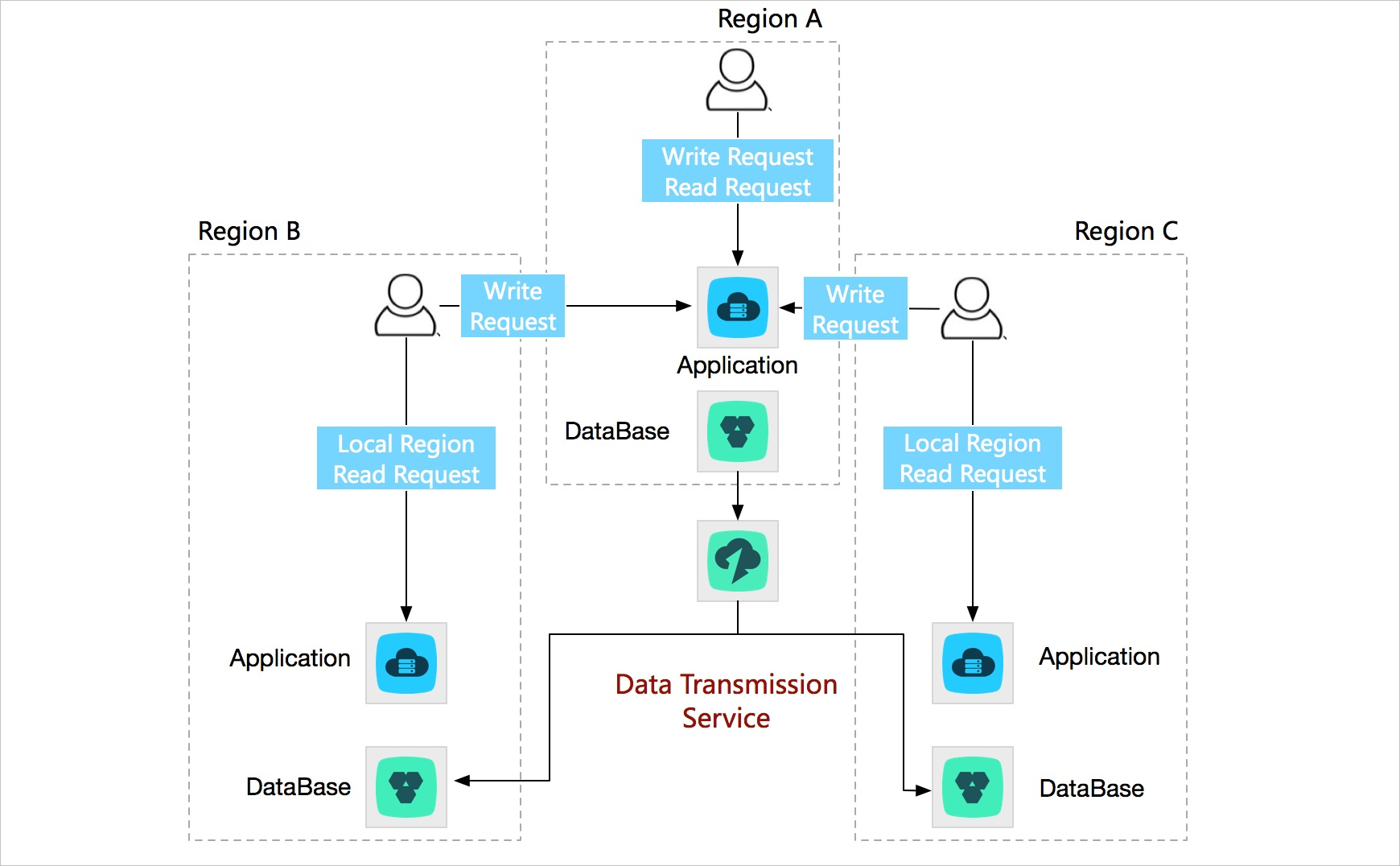
To resolve these issues, you can build multiple business units in the same city or different cities. DTS enables two-way real-time data synchronization between business units to ensure global data consistency. If a failure occurs in a business unit, you can switch to another business unit. This way, your service can be recovered within seconds. This helps ensure the high availability of your service.
You can also distribute traffic across business units based on a specific dimension. For example, you can reschedule the traffic of each business unit by region to allow users to access the nearest node. This reduces network latency and improves user experience. In addition, business scalability is no longer limited by the capacity of infrastructure in a single region because business units are distributed across different regions.
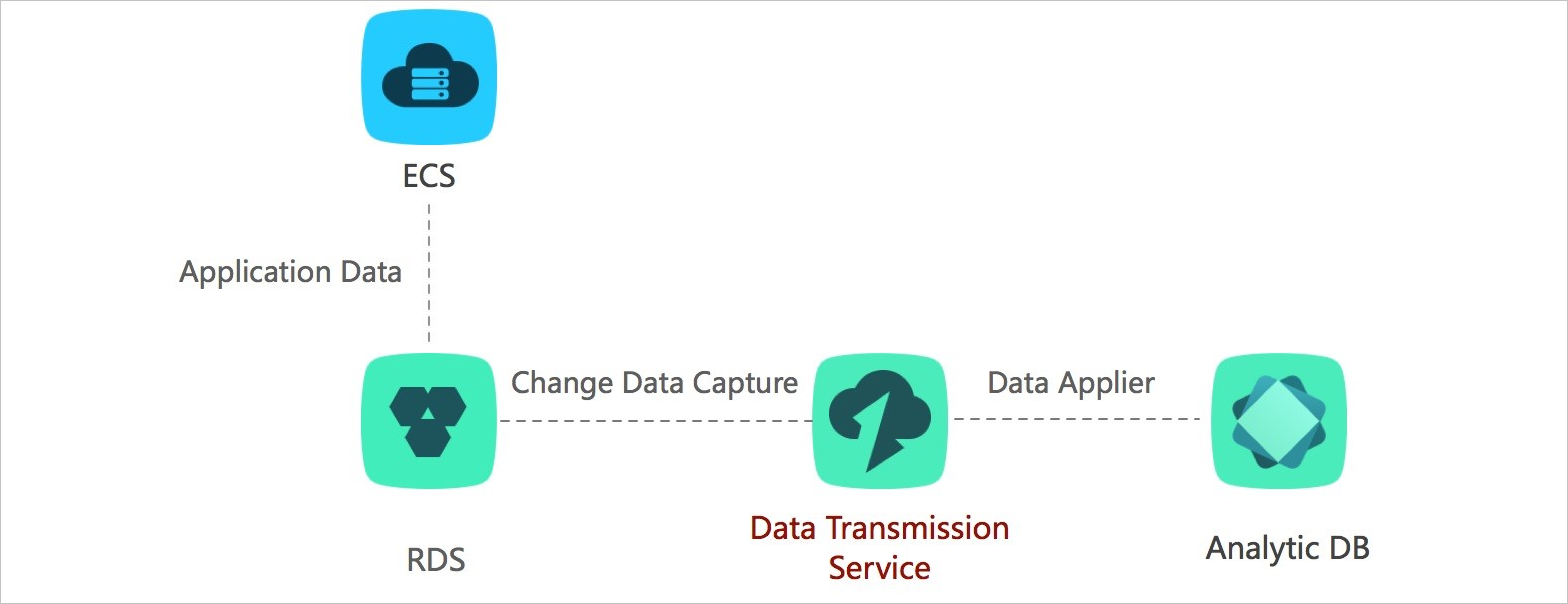
Custom BI system built with ease
Transmission mode: data synchronization
Self-managed business intelligence (BI) systems cannot meet increasing requirements for real-time capability. Alibaba Cloud provides comprehensive BI systems. DTS allows you to synchronize data in real time from a self-managed database to an Alibaba Cloud storage system that supports BI analysis, such as MaxCompute. This helps you quickly build a custom BI system that meets your business requirements on Alibaba Cloud.
Real-time data analysis
Transmission mode: change tracking
Data analysis gives enterprises insights into their business and improves user experience. Real-time data analysis allows enterprises to adjust marketing strategies in response to changing market trends and customer demands.
DTS provides the change tracking feature. It allows you to track the incremental data of your application in real time without affecting online business. In addition, you can use DTS SDKs to synchronize the tracked incremental data to the analysis system for real-time analysis.
Lightweight cache update policies
Transmission mode: change tracking
To accelerate access and improve concurrent read performance, a cache layer is designed in the business architecture to receive all read requests. The memory read mechanism of the cache layer can improve read performance. The data in the cache memory is not persistent. If the cache memory fails, data loss occurs in the cache memory.
DTS provides the change tracking feature. The feature can help you track the incremental data in databases in an asynchronous manner and update the cached data. This way, you can implement lightweight cache update policies.
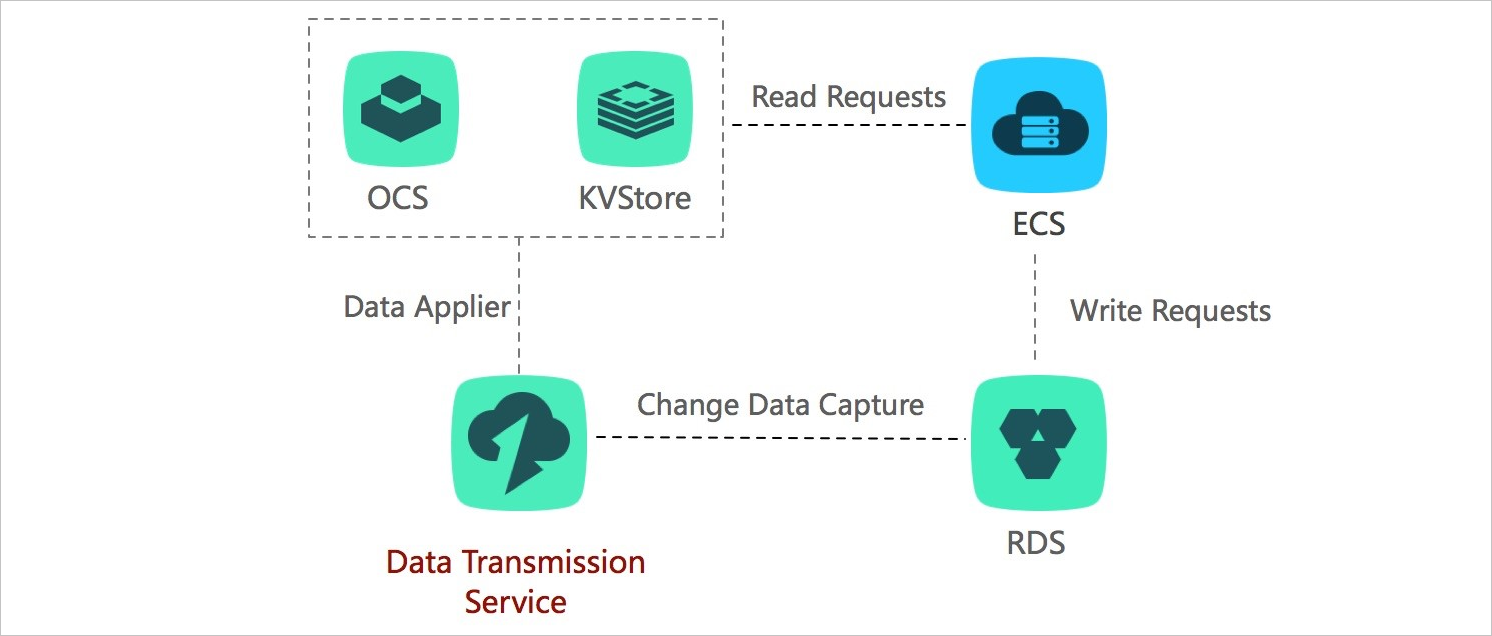
This architecture has the following benefits:
- Quick update with low latency
After a data update is complete, the updated data is returned. For this reason, you do not need to consider the cache invalidation process. The entire update process is quick with low latency.
- Implementation with ease
Doublewrite logic is not required when you use DTS to implement this architecture. You need only to start asynchronous threads to track incremental data and update cached data.
- Cached data updates without performance degradation
DTS tracks incremental data by parsing incremental logs in databases. This does not affect your business or the databases.
Business decoupling
Transmission mode: change tracking
The e-commerce industry involves many types of business logic, such as ordering, inventory, and logistics. If all these types of business logic are included in the ordering process, an order result is not returned until all the changes in the business logic are complete. This may cause the following issues:
- The ordering process takes a long period of time and results in poor user experience.
- The business system is unstable because each downstream fault affects service availability.
To improve user experience and service performance, you can use the change tracking feature of DTS to decouple different types of business logic. This is achieved by means of real-time notifications and asynchronous communication between different types of business logic. This makes the business logic simple and reliable. The following figure shows the architecture of business decoupling.
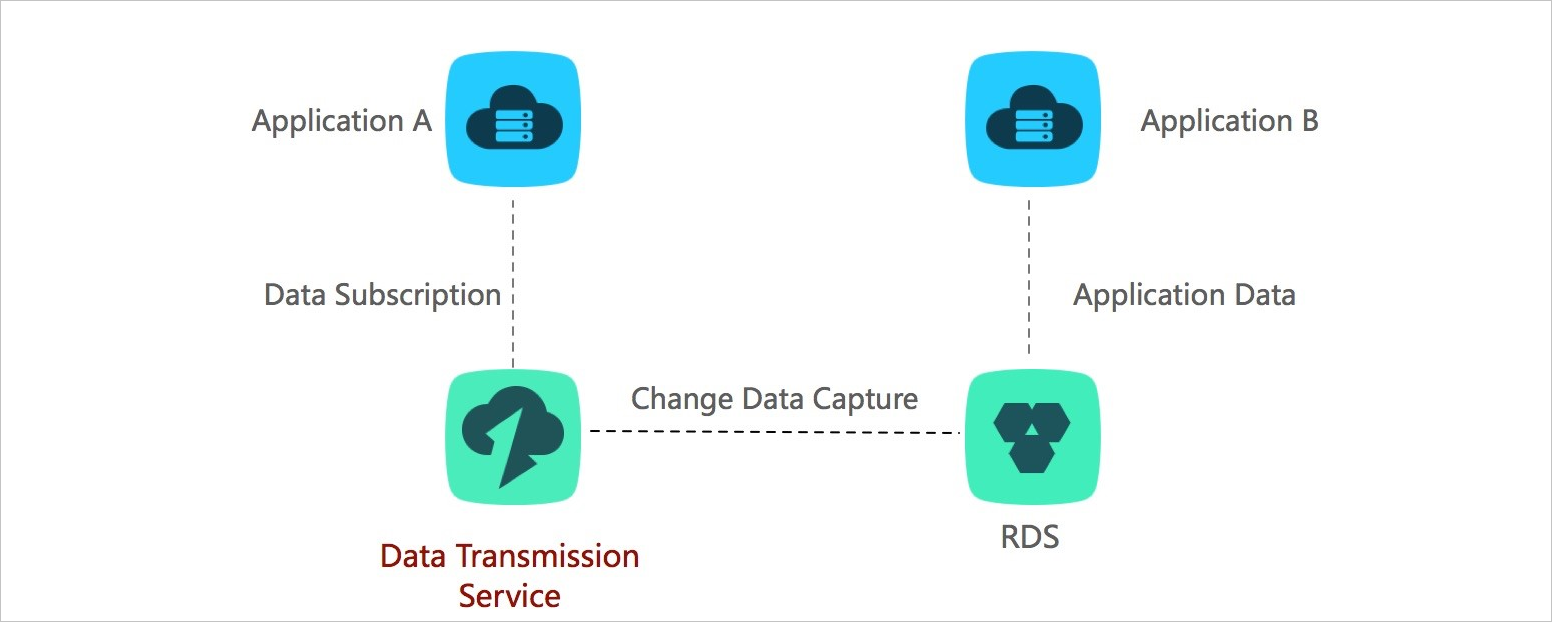
In this scenario, the ordering system returns the result after the buyer places an order. The underlying layer obtains the data changes that are generated in the ordering system in real time by using the change tracking feature. You can use DTS SDKs to track these data changes and trigger different types of downstream business logic, such as inventory and logistics. This makes the entire business system simple and reliable.
This scenario has been applied to a wide range of businesses in Alibaba Group. Tens of thousands of downstream businesses in the Taobao ordering system are using the change tracking feature to track real-time data changes and trigger business logic.
Scalable read capability
Transmission mode: data synchronization
A single database instance may not have sufficient resources to deal with a large number of read requests. You can use the real-time data synchronization feature of DTS to create read-only instances and distribute read requests across these read-only instances. This allows you to scale out the read capability and relieve the pressure on the primary database instance.
Task scheduling for a data warehouse
Transmission mode: data migration
If you have large online applications that process large amounts of transactional data every day, you may want to migrate the data to your data warehouse on a regular basis. For example, you may want to perform data migration during off-peak hours to migrate the transactional data of the previous day to your data warehouse. In that case, you can use the data migration feature of DTS, which is ideal for this scenario.