Time Series Database (TSDB) is a distributed, highly reliable and cost-effective database built to ingest, store, and query time series data at scale. It is designed for Internet of Things (IoT) monitoring, enterprise-level energy management, production safety monitoring, and electric power detection.
TSDB addresses two core challenges in time series workloads: high-frequency data collection from large numbers of device endpoints, and the storage cost of retaining that data at scale. With TSDB, you can:
Write at high throughput — ingest millions of data points within seconds
Compress storage efficiently — reduce storage footprint with a high compression ratio
Downsample historical data — aggregate older data to lower resolution over time
Fill data gaps — interpolate missing values in irregular time series
Query across dimensions — aggregate across tags, metrics, and time windows simultaneously
Visualize query results — surface insights directly from query output
How it works
The following diagram shows the TSDB architecture.
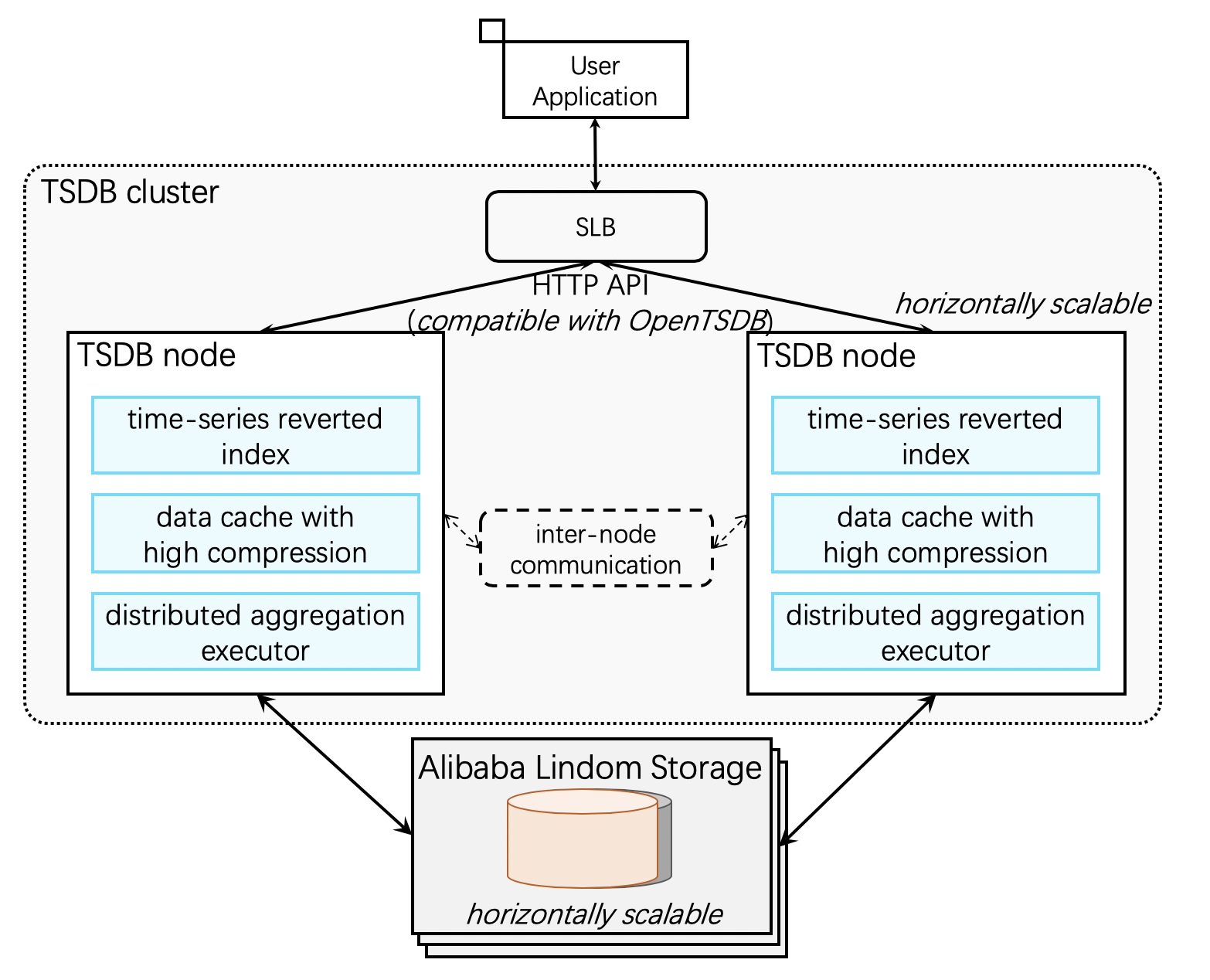
Data flows from device endpoints into TSDB's distributed write layer, which replicates data across multiple nodes for durability. The storage engine compresses data as it is persisted. The read layer serves queries, aggregations, and visualizations. TSDB's elastic architecture lets you conveniently and dynamically adjust the cluster based on business traffic.
Use cases
IoT monitoring — collect sensor readings from large numbers of devices at high frequency; detect anomalies in real time
Enterprise-level energy management systems (EMS) — track energy consumption across facilities; run time-windowed aggregations to identify waste
Production safety monitoring — ingest alerts and status signals from industrial equipment; correlate events across time
Electric power detection — monitor grid metrics continuously; query historical trends for capacity planning
TSDB Edge
TSDB Edge (Time Series Database Edge) is a lightweight version of TSDB deployed on the device side. It addresses the storage and read/write efficiency problems caused by large numbers of device collection points operating at high data collection frequency.
Key capabilities:
Up to 15:1 compression ratio — reduces on-device storage cost
Fast writes and high throughput — sustains high-frequency data collection without backpressure
High availability (HA) — local storage reliability through HA support
Edge storage and computing — process and store data locally without depending on a central connection
Edge-to-center data synchronization — sync data to the central TSDB instance when connectivity is available
Breakpoint resumption — resumes interrupted data transmission from where it left off; data is cached at the edge during outages
One-key installation — deploys independently with no external component dependencies