Hash join is a new join execution method introduced in MySQL Community Edition 8.0. It can significantly improve the execution performance of analytic queries. PolarDB for MySQL 8.0 supports the parallel execution of hash joins. More parallel execution policies are under development and will be released in the future. This topic describes how to use hash joins for parallel queries in PolarDB.
Simple hash join
Prerequisites
A PolarDB for MySQL 8.0 of Cluster Edition cluster is used and the revision version of the cluster is 8.0.2.1.0 or later. For more information about how to check the cluster version, see Query the engine version.
Parallel execution policy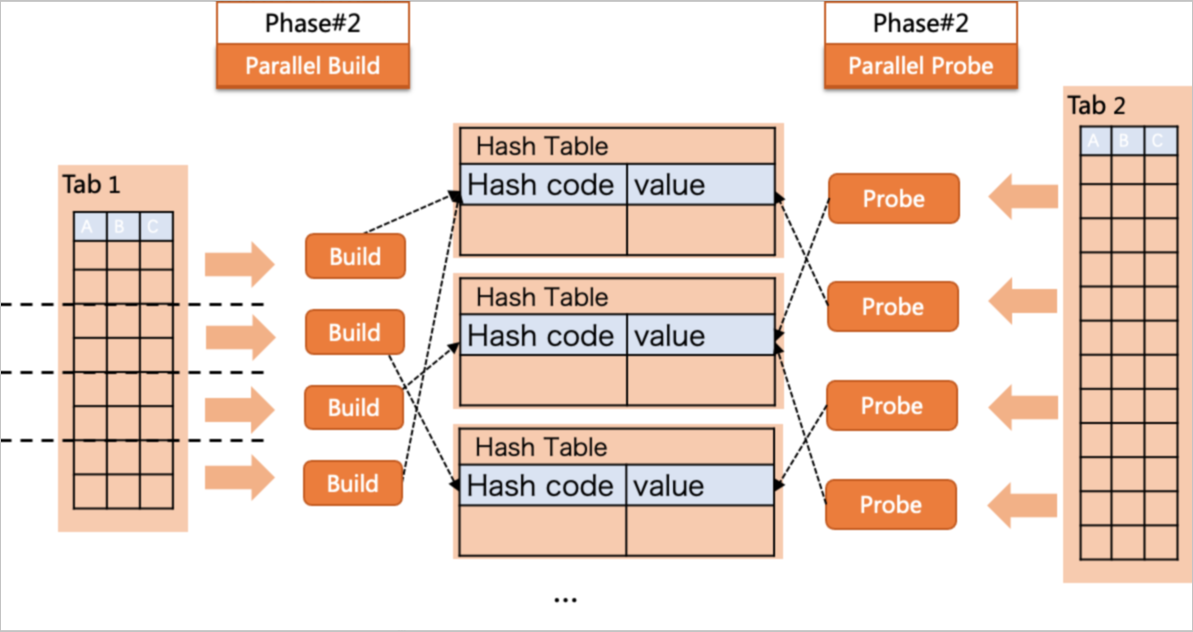
In the preceding execution plan, the degree of parallelism (DOP) is set to 4, which indicates that PolarDB uses four workers to perform parallel queries. First, four workers scan table t1 in parallel. Each worker uses only part of the data in table t1 to create a hash table. Then, a JOIN operation is performed between the four hash tables and table t2. Finally, a leader gathers the joined results to generate the final query results.
Usage
Syntax:
In PolarDB, you can execute only the
EXPLAIN FORMAT=TREEstatement to check whether hash joins are used.Examples:
In the following example, two tables are created and data is inserted into the tables.
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;Query the execution plan of the following SELECT statement:
EXPLAIN FORMAT=TREE SELECT /*+ PQ_DISTRIBUTE(t1 PQ_NONE) PQ_DISTRIBUTE(t2 PQ_NONE) */ * FROM t1 JOIN t2 ON t1.c1 = t2.c2;The following example shows the execution plan for these two tables when hash joins are used:
EXPLAIN FORMAT=TREE EXPLAIN -> Gather (slice: 1; workers: 4) (cost=10.82 rows=4) -> Parallel inner hash join (t2.c2 = t1.c1) (cost=0.57 rows=1) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.03 rows=1) -> Parallel hash -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.16 rows=1)In the preceding execution plan, the DOP is set to 4, which indicates that PolarDB uses four workers to perform parallel queries. First, four workers scan table
t1in parallel. Each worker uses only part of the data in tablet1to create a hash table. Then, a JOIN operation is performed between the four hash tables and tablet2. Finally, a leader gathers the joined results to generate the final query results.
Shuffle Hash Join
Prerequisites
A PolarDB for MySQL 8.0 of Cluster Edition cluster is used and the revision version of the cluster is 8.0.2.2.0 or later. For more information about how to check the cluster version, see Query the engine version.
Parallel execution policy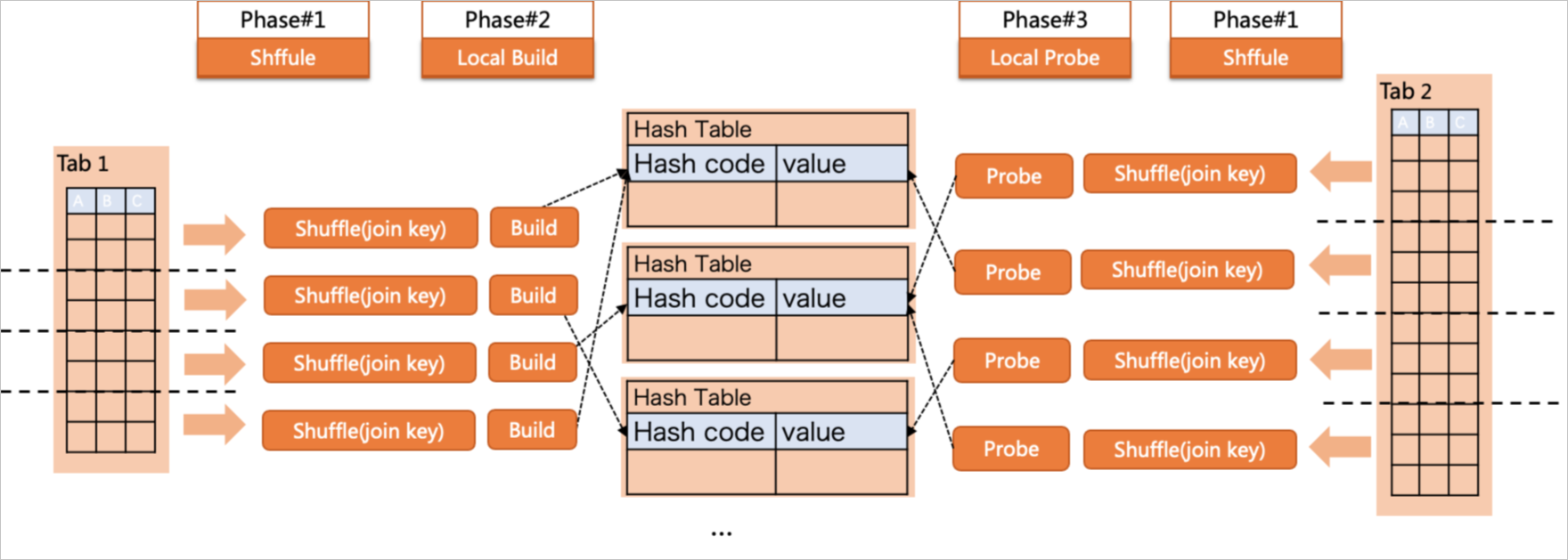
Parallel hash join implements parallel execution in both the build and probe phases. However, if the shared hash table is too large, I/O operations are performed to dump the data to a disk, which affects the parallel query efficiency. To resolve this issue, partition hash join is used. In the preceding execution plan, four workers scan table t1 in parallel, partition and distribute the data to workers of the next phase based on join keys, and build a small hash table in each partition. After the build phase is complete, the four workers scan table t2, partition the data based on join keys, and distribute the data to workers that have completed the building of small hash tables. After the probe operation is complete, a leader gathers the joined results to generate the final query results.
Usage
Syntax:
In PolarDB, you can execute only the
EXPLAIN FORMAT=TREEstatement to check whether hash joins are used.Examples:
In the following example, two tables are created and data is inserted into the tables.
CREATE TABLE t1 (c1 INT, c2 INT); CREATE TABLE t2 (c1 INT, c2 INT); INSERT t1(c1, c2) WITH RECURSIVE seq AS ( SELECT 1 AS a, 1 AS b UNION ALL SELECT a + 1, b + 1 FROM seq WHERE a < 1000 ) SELECT a,b FROM seq; INSERT INTO t2 SELECT * FROM t1;Query the execution plan of the following SELECT statement:
EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c2;The following example shows the execution plan for these two tables when hash joins are used:
EXPLAIN FORMAT=TREE EXPLAIN | -> Gather (slice: 1; workers: 2) (cost=33.38 rows=4) -> Inner hash join (t2.c1 = t1.c1) (cost=23.08 rows=2) -> Repartition (hash keys: t2.c1; slice: 2; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t2, with parallel partitions: 1 (cost=0.65 rows=4) -> Hash -> Repartition (hash keys: t1.c1; slice: 3; workers: 1) (cost=11.35 rows=2) -> Parallel table scan on t1, with parallel partitions: 1 (cost=0.65 rows=4)