Hash join is a join execution method introduced in MySQL Community Edition 8.0. Analytic queries that join large tables often bottleneck on sequential join processing. PolarDB for MySQL 8.0 supports two parallel hash join strategies—simple hash join and shuffle hash join—that distribute join work across multiple workers to reduce query latency. More parallel execution policies are under development and will be released in the future.
Choose a strategy
| Strategy | Minimum revision | Best for |
|---|---|---|
| Simple hash join | 8.0.2.1.0 | Joins where the hash table fits in memory |
| Shuffle hash join | 8.0.2.2.0 | Joins where the hash table would spill to disk |
Use shuffle hash join when simple hash join causes disk I/O due to a large hash table.
PolarDB only supportsEXPLAIN FORMAT=TREEto verify which hash join strategy is active. OtherEXPLAINformats do not show hash join usage.
Simple hash join
Prerequisites
Before you begin, ensure that you have:
-
A PolarDB for MySQL 8.0 Cluster Edition cluster with revision version 8.0.2.1.0 or later
To check your revision version, see Query the engine version.
How it works
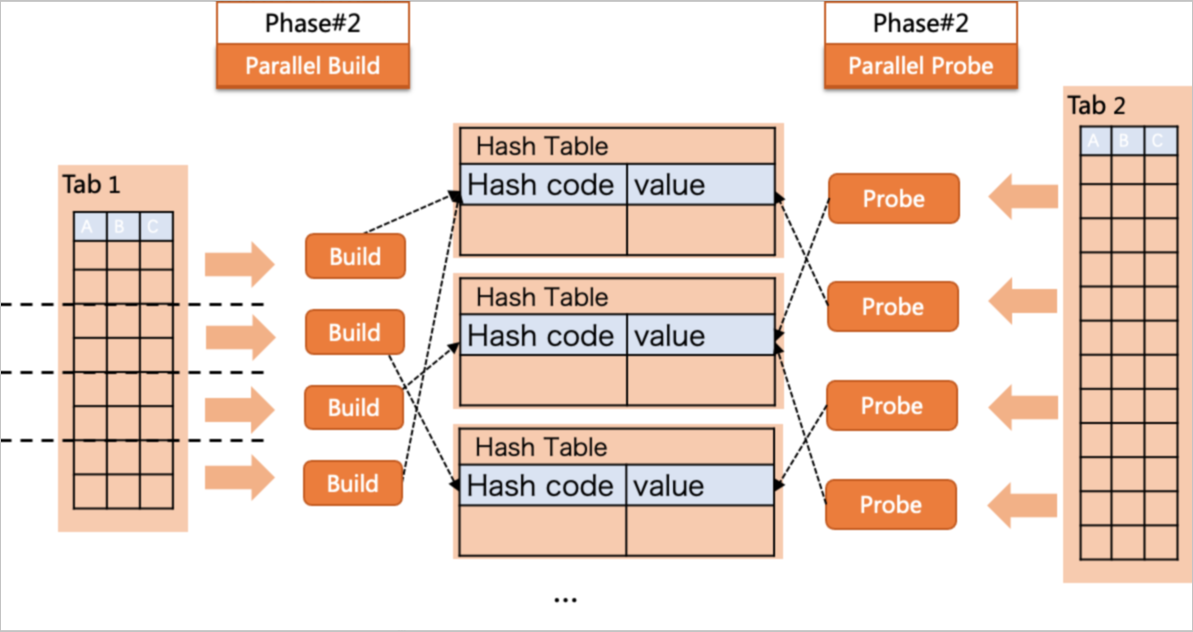
With a degree of parallelism (DOP) of 4, four workers scan table t1 in parallel. Each worker builds a local hash table from its portion of t1 data, then probes that hash table against t2 rows. A leader node runs a Gather operation to collect and merge results from all workers.
This strategy is effective when the hash table fits within memory. If the combined hash table grows too large and triggers disk I/O, use shuffle hash join instead.
Verify that simple hash join is used
Example
Create two tables and insert 1,000 rows into each:
CREATE TABLE t1 (c1 INT, c2 INT);
CREATE TABLE t2 (c1 INT, c2 INT);
INSERT t1(c1, c2)
WITH RECURSIVE seq AS (
SELECT 1 AS a, 1 AS b
UNION ALL
SELECT a + 1, b + 1 FROM seq WHERE a < 1000
)
SELECT a, b FROM seq;
INSERT INTO t2 SELECT * FROM t1;Run EXPLAIN FORMAT=TREE with PQ_DISTRIBUTE hints to confirm simple hash join is selected:
EXPLAIN FORMAT=TREE SELECT /*+ PQ_DISTRIBUTE(t1 PQ_NONE) PQ_DISTRIBUTE(t2 PQ_NONE) */ * FROM t1 JOIN t2 ON t1.c1 = t2.c2;Expected output:
EXPLAIN FORMAT=TREE
EXPLAIN
-> Gather (slice: 1; workers: 4) (cost=10.82 rows=4)
-> Parallel inner hash join (t2.c2 = t1.c1) (cost=0.57 rows=1)
-> Parallel table scan on t2, with parallel partitions: 1 (cost=0.03 rows=1)
-> Parallel hash
-> Parallel table scan on t1, with parallel partitions: 1 (cost=0.16 rows=1)Reading the execution plan
| Node | Role |
|---|---|
Parallel table scan on t1 |
Each worker scans a partition of t1 (build side) |
Parallel hash |
Each worker builds a local hash table from its t1 partition |
Parallel inner hash join |
Each worker probes its hash table against t2 rows (probe side) |
Gather (workers: 4) |
The leader collects results from all four workers |
Shuffle hash join
Prerequisites
Before you begin, ensure that you have:
-
A PolarDB for MySQL 8.0 Cluster Edition cluster with revision version 8.0.2.2.0 or later
To check your revision version, see Query the engine version.
How it works
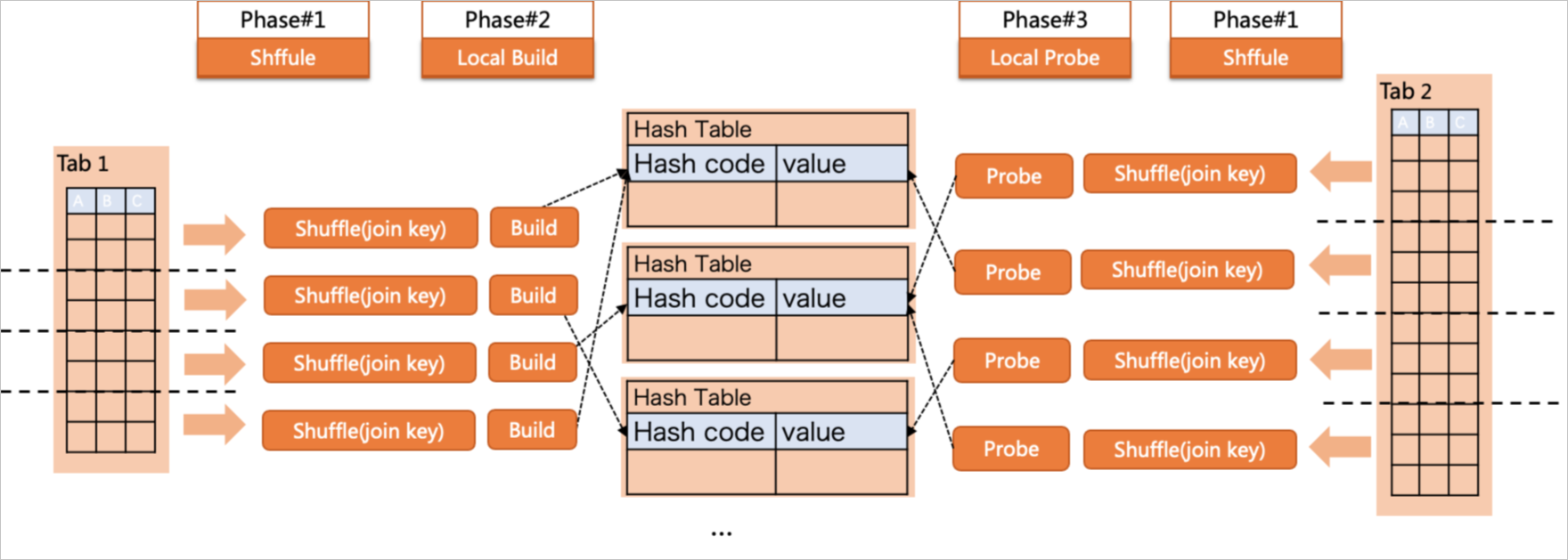
Shuffle hash join (also known as partition hash join) addresses the memory pressure of simple hash join. Instead of each worker building a hash table from the full dataset, workers first repartition both tables by join key. Each worker then independently builds a small hash table from only its assigned partition.
With a DOP of 2, execution proceeds in three phases:
-
Build phase: Workers scan
t1, repartition rows by join key, and each worker builds a small hash table from its assigned partition. -
Probe phase: Workers scan
t2, repartition rows by the same join key, and probe the matching hash table partition. -
Gather: The leader collects and merges results from all workers.
Because each hash table covers only a subset of the data, shuffle hash join handles large datasets without spilling to disk.
Verify that shuffle hash join is used
Example
Use the same t1 and t2 tables from the simple hash join example. Run EXPLAIN FORMAT=TREE without hints—PolarDB automatically selects shuffle hash join when appropriate:
EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c2;Expected output:
EXPLAIN FORMAT=TREE
EXPLAIN
| -> Gather (slice: 1; workers: 2) (cost=33.38 rows=4)
-> Inner hash join (t2.c1 = t1.c1) (cost=23.08 rows=2)
-> Repartition (hash keys: t2.c1; slice: 2; workers: 1) (cost=11.35 rows=2)
-> Parallel table scan on t2, with parallel partitions: 1 (cost=0.65 rows=4)
-> Hash
-> Repartition (hash keys: t1.c1; slice: 3; workers: 1) (cost=11.35 rows=2)
-> Parallel table scan on t1, with parallel partitions: 1 (cost=0.65 rows=4)Reading the execution plan
| Node | Role |
|---|---|
Repartition (hash keys: t1.c1) |
Redistributes t1 rows to workers by join key (build side) |
Hash |
Each worker builds a small hash table from its assigned t1 partition |
Repartition (hash keys: t2.c1) |
Redistributes t2 rows to the corresponding worker by join key (probe side) |
Inner hash join |
Each worker probes its hash table against its assigned t2 rows |
Gather (workers: 2) |
The leader collects results from all workers |