Overview
TCP health check is a network protocol used by GTM to perform health checks on target addresses. It primarily monitors metrics such as network reachability, port availability, and latency of IP addresses. When an IP address or port becomes abnormal, the system automatically blocks the abnormal IP address. When the IP address returns to normal, the system automatically removes the block.
Configuration method
Log on to Alibaba Cloud DNS - Global Traffic Manager.
On the instance list page of Global Traffic Manager, click the Actions column of the target instance, and then click the Configuration button.
On the Basic Configuration page, click the Address Pool tab, then click the "+" icon in front of the address pool, and then click Add next to Health Check.
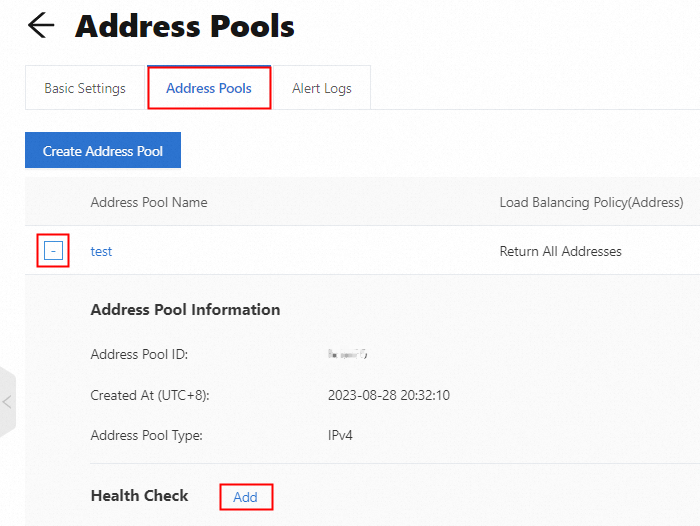
In the Modify Health Check dialog box, complete the configuration of Health Check Protocol, Health Check Interval, Health Check Port, Timeout Period, Consecutive Failures, Failure Ratio, and Monitoring Nodes, and then click OK.
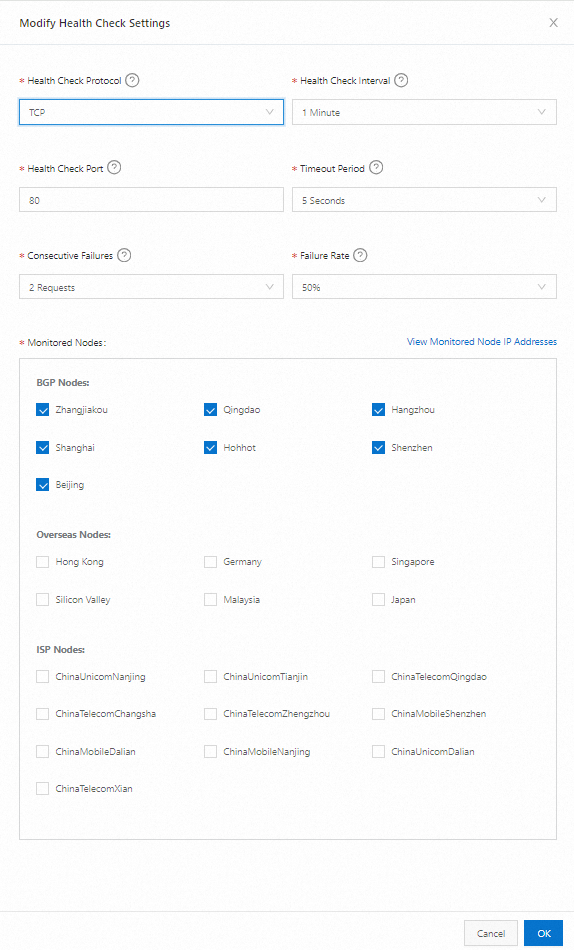
Parameters
Health Check Protocol
Select TCP to monitor the target IP address using the TCP protocol. This primarily monitors metrics such as network reachability, port availability, and latency of the IP address.
Health Check Interval
Select the time interval for each TCP monitoring. By default, a check is performed every 1 minute. The minimum health check interval supported is 15 seconds (available for Ultimate Edition users).
Health Check Port
Checks whether Telnet can be performed on this port of the target IP address. If Telnet is successful on the port, the service is considered normal. If Telnet fails on the port, the service is considered abnormal.
Timeout Period
For each TCP health check, the system calculates the return time of the sent TCP packet. If the packet does not return within the timeout period, the health check is considered timed out. The available timeout values are: 2 seconds, 3 seconds, 5 seconds, and 10 seconds.
Consecutive Failures
When performing TCP health checks, the system determines that the application service is abnormal only after multiple consecutive abnormal detections. This prevents monitoring accuracy from being affected by factors such as momentary network jitter. The available values for consecutive failures are: 1 time, 2 times, and 3 times.
1 time: The application service is determined to be abnormal when the health check detects one alarm.
2 times: The application service is determined to be abnormal when the health check detects two consecutive alarms.
3 times: The application service is determined to be abnormal when the health check detects three consecutive alarms.
Failure Ratio
When performing TCP health checks, this is the ratio of abnormal monitoring points to the total number of monitoring points. When the failure ratio exceeds the set threshold, the application service is determined to be abnormal. The available failure ratio thresholds are: 20%, 50%, 80%, and 100%.
Monitoring Nodes
The geographic location of the node that performs TCP health checks. The default monitoring nodes provided by the system are as follows:
Node Type | Geographic Location |
BGP Node | Zhangjiakou, Qingdao, Hangzhou, Shanghai, Hohhot, Shenzhen, Beijing |
International Node | China (Hong Kong), Germany, Singapore, California, Malaysia, Japan |
Carrier Node | Wuhan China Unicom, Dalian China Unicom, Nanjing China Unicom, Tianjin China Unicom, Qingdao China Telecom, Changsha China Telecom, Xi'an China Telecom, Zhengzhou China Telecom, Shenzhen China Mobile, Dalian China Mobile, Nanjing China Mobile |
If all addresses in the address pool are Alibaba Cloud addresses and you use blackhole filtering policy for fault testing, please select carrier nodes as monitoring nodes. (Reason: Blackhole filtering is an ACL policy that takes effect on the Internet between Alibaba Cloud network and carrier networks, but traffic between Alibaba Cloud IPs mostly flows within the cloud network, which reduces the detection effectiveness.)