The Personal Resource Optimization page lists the optimizable nodes and tables under the logged on personal account.
Procedure
- On the DataStudio page that appears, click
 in the upper-left corner and choose . The Personal Resource Optimization page appears by default.
To view the optimization information of other workspaces, select one from the top drop-down list. You can also click All my projects.
in the upper-left corner and choose . The Personal Resource Optimization page appears by default.
To view the optimization information of other workspaces, select one from the top drop-down list. You can also click All my projects. The Personal Resource Optimization page consist of the Personal Asset Overview and Personal Resource Optimization sections.
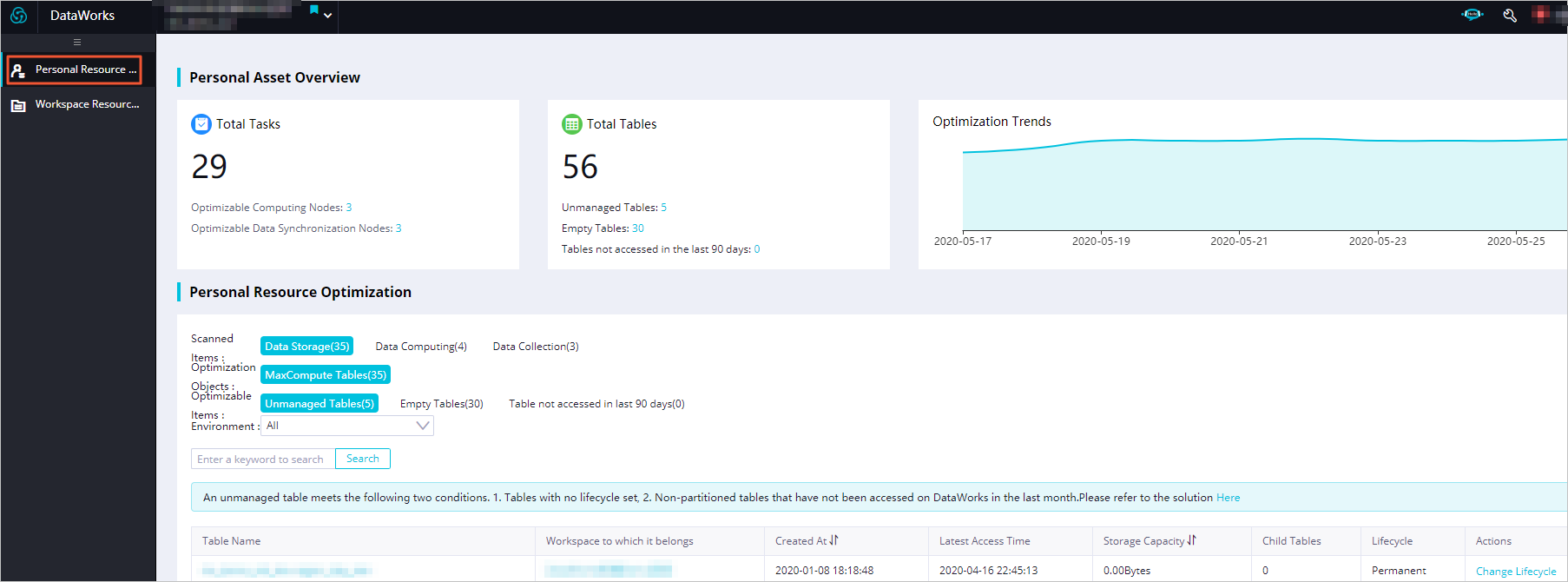
The Personal Resource Optimization page consist of the Personal Asset Overview and Personal Resource Optimization sections.- You can view the total number of nodes and total number of tables under your personal
account in the Personal Asset Overview section.
The Optimization Trends chart displays the variation trend of the optimizable items in the last 10 days. You can view the number of optimizable items detected on different days.Note The data in the Optimization Trends chart is not generated in real time. The date on the rightmost side of the chart indicates the latest date when the statistics are updated.
- The Personal Resource Optimization section lists optimizable items of the Data Storage, Data Computing, and Data Collection types. They refer to MaxCompute tables, MaxCompute nodes, and data synchronization
nodes that write data to MaxCompute, respectively.
 Note The standard workspace mode provided by DataWorks isolates the development environment from the production environment. That is, a DataWorks workspace corresponds to a MaxCompute project in the development environment and a MaxCompute project in the production environment. You can filter projects by Environment.
Note The standard workspace mode provided by DataWorks isolates the development environment from the production environment. That is, a DataWorks workspace corresponds to a MaxCompute project in the development environment and a MaxCompute project in the production environment. You can filter projects by Environment.Scanned item Optimization object Optimizable item Description Data Storage MaxCompute Tables Unmanaged Tables An unmanaged table refers to a table that meets both of the following conditions: - The lifecycle of the table is not specified.
- The table is a non-partitioned table that has not been accessed for the last 30 days in DataWorks.
Tables that meet the preceding conditions are recognized as unmanaged tables. You can set a lifecycle for each unmanaged table to complete the optimization. For more information about the lifecycle, see Lifecycle.
Note When the lifecycle of a table expires, data in the table will become invalid. We recommend that you exercise caution when performing this operation.Empty Tables An empty table refers to a table with no data. We recommend that you do not delete empty tables directly. You can audit tables that were created a long time ago based on the table creation time to determine whether to delete the tables. Data Computing MaxCompute Nodes Conflict Task When you write the data of multiple nodes to the same table, unexpected results may be returned. We recommend that you do not write the data of multiple nodes to the same partition of the same table in the data development process. This helps avoid data quality issues caused by any failed node when you perform retroactive executions. The idempotence of data must be taken into account. We recommend that you pause one of the ancestor nodes and adjust the dependencies of its descendant nodes based on the number of descendant nodes of each ancestor node.
Data Tilt Data skew occurs on nodes where some node instances process more data and take much more time than the others. This prolongs the overall execution time of the nodes, leading to latency. For more information about the solution to data skew, see Optimize long tail computing.
Data Collection Data Synchronization Nodes Empty Import The volume of the data imported by certain data synchronization nodes is always 0. We recommend that you pause these nodes or bring them offline. Consistent Import Certain data synchronization nodes have imported the same volume of data for 15 consecutive days. Check whether the source data is no longer updated. Also, check whether the nodes have been paused. We recommend that you stop scheduling any computing and storage resources for the paused nodes.
Same Origin Import Certain data synchronization nodes share the same data stores and import duplicate data to MaxCompute. This leads to waste of storage and scheduling resources. You can resolve this issue by merging nodes. OSS Synchronization Optimization Certain data synchronization nodes transmit data to Object Storage Service (OSS) over the Internet. This consumes Internet traffic and charges you an additional fee. We recommend that you change the endpoint of the data store to an internal IP address. To perform this operation, click the DataWorks icon in the DataWorks console, click in the left-side navigation pane, and then click Data Sources. This cuts the consumption of Internet traffic and improves the data transmission speed. For more information, see Configure endpoints.
- You can view the total number of nodes and total number of tables under your personal
account in the Personal Asset Overview section.