When I commit a node, the system reports an error that the output name of the dependent ancestor node does not exist. What do I do?
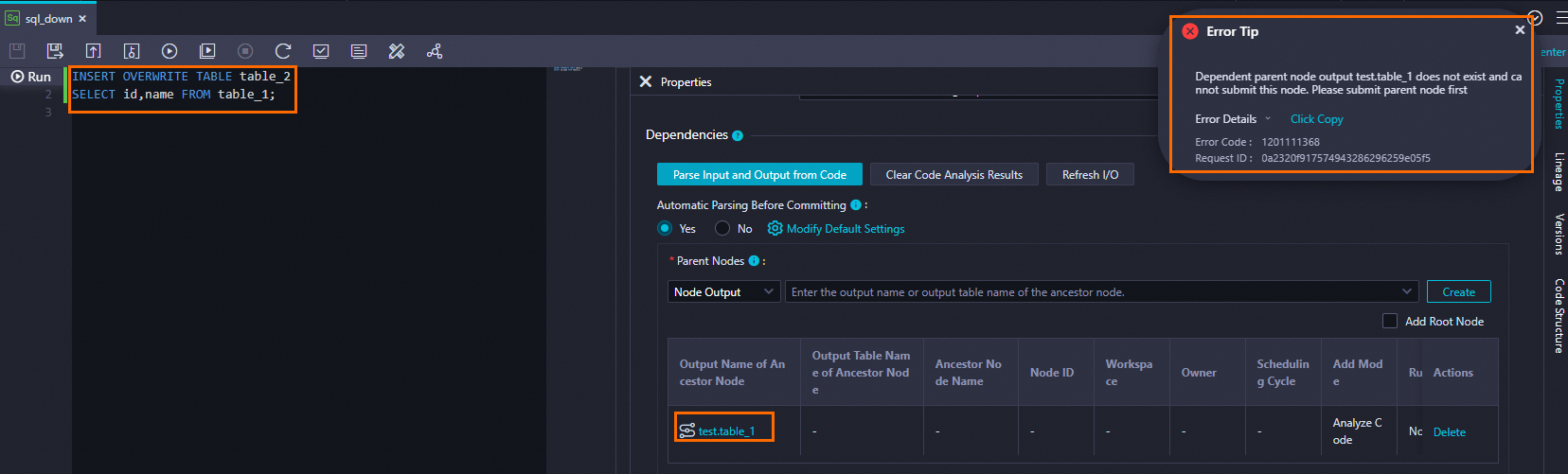
When you commit a node, DataWorks validates the Parent Node Output Name for each scheduling dependency against all registered node outputs. If no node is registered with that output name, the commit fails with this error — even if the underlying table exists in your database.
Node Output Name Does Not Exist means no node has been configured with that output name. It does not mean the table itself is missing. The error also occurs when a node produces the table but the table has not been added as an output of that node.
The error shown in the figure means DataWorks cannot find any node registered with the output name xc_ods_user_info_d_133. The following three causes cover the most common scenarios.
Does any node produce this table through a recurring schedule?
If the table is not produced by a DataWorks recurring schedule, DataWorks cannot auto-parse it and register a node output for it. This applies to:
Tables uploaded from a local machine to DataWorks
Dimension tables
Tables produced outside DataWorks scheduling
Tables produced by one-time tasks
When a node runs a SELECT statement on such a table, DataWorks finds no matching node output and the commit fails.
Solution: Delete the scheduling dependency that references this table. In the example above, delete the dependency where Parent Node Output Name is xc_ods_user_info_d_133.
For instructions, see Configure dependencies for recurring schedules.
After deleting the dependency, recommit the node. DataWorks displays a prompt indicating a mismatch between the data lineage and the scheduling dependencies. Confirm that only the non-recurring table dependency is missing, then force the commit to proceed. For details on this mismatch prompt, see Node commit prompt: Inputs and outputs do not match code data lineage analysis.
Does a node produce this table but lack it as a registered output?
DataWorks auto-parses code and registers the output table as a node output for most node types. However, automatic parsing is not supported for:
Offline nodes
AnalyticDB for PostgreSQL nodes
AnalyticDB for MySQL nodes
EMR nodes
If the table is produced by one of these node types but was never manually added as that node's output, DataWorks finds no registered output name to match the dependency, causing the commit to fail.
Solution: On the node that produces the table, manually add the table as Output Of This Node. In the example above, add xc_ods_user_info_d_133 as the output of the producing node.
For instructions, see Configure dependencies for recurring schedules.
After adding the output, recommit the node. If the error no longer appears, the dependency configuration is correct.
Do multiple nodes share the same output name?
Duplicate node output names cause the commit to fail because DataWorks cannot identify a unique producing node. This happens in two scenarios:
Multiple nodes produce the same table. DataWorks cannot determine which node is the authoritative source.
Two nodes in the same project share the same name. DataWorks automatically adds two Node Outputs when a node is created. One of these outputs is named according to the
projectname.nodenamenaming convention. If two nodes share a name, their auto-generated outputs are identical.
Solution: Enforce unique naming across your project:
Each table must be produced by exactly one node. Add the output table as an output of that node only.
Ensure all node names are unique within the same project.
After making changes, verify that no two nodes share the same Output Of This Node name, then recommit to confirm the error is resolved.