In DataWorks, batch synchronization nodes do not support automatic parsing to add scheduling dependencies. If a workflow includes a batch synchronization node whose generated table is a dependency for a descendant node, you must manually add that table to the batch synchronization node's output. This allows the automatic parsing feature to identify the correct ancestor node when the descendant node queries the table.
Common pitfalls
The output name of the dependent ancestor node of the current node: test.table_1 does not exist. The current node cannot be committed. Make sure that the ancestor node that has this output name has been committed! and the error code is 1201111368.Method 1: Manually add table to output
test.table_1, and click Add. The table is then added to the output list, and its addition method is displayed as Manually Added.Method 2: Align node and table names
- When you create a batch synchronization node, DataWorks automatically generates an Output for it in the format
projectname.nodename. - When an SQL node references the generated table of the batch synchronization node, DataWorks automatically generates a Parent Nodes for the SQL node in the format
projectname.tablename. - To prevent errors, ensure that the name of the Parent Nodes in the SQL node matches the name of the Output of the batch synchronization node.
projectname.nodename is created at the same time as the node. If you rename the node after it is created, the name of this projectname.nodename Output does not change. This method works only when you initially create the batch synchronization node. It will not work if you try to align the names by renaming an existing node.Error analysis
| Step | Description | Scheduling dependency |
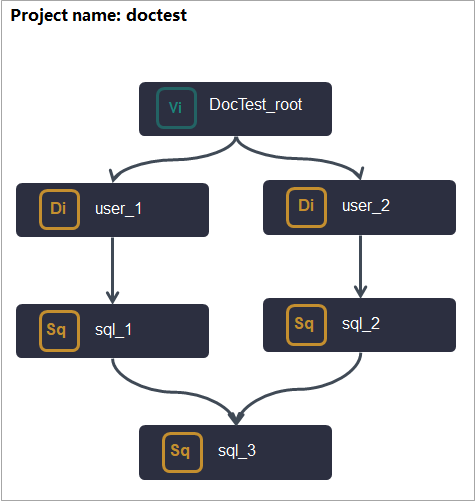
| 1 | Create the required nodes based on your workflow plan. For example, create a virtual node, a batch synchronization node, and a MaxCompute node. |
After you create nodes, DataWorks automatically generates two Output configurations for each: one named in the projectname.nodename format and the other suffixed with _out.For example, for the batch synchronization node user_1, the system generates the following outputs after the node is created:
|
| 2 | Connect the nodes with lines to define their running order and dependencies. | After you connect the nodes on the workflow page, DataWorks automatically adds dependency configurations based on the connections. For example, once connected, the MaxCompute node sql_1 becomes a descendant node of the batch synchronization node user_1. DataWorks automatically adds the output of user_1 that is named |
| 3 | Develop task code for each node. | As you write code for a node, DataWorks automatically parses I/O commands and adds a corresponding Output or a Parent Nodes. For example, if the MaxCompute node sql_1 needs to use data from the table |
- The batch synchronization node user_1 does not support automatic parsing. Therefore, the generated table, table_1, is not automatically added to the Output of node user_1. This means that node user_1 does not have an output named
doctest.table_1. - For the descendant node sql_1, automatic parsing adds a Parent Nodes with a name that follows the
projectname.tablenameformat. In this example, the name isdoctest.table_1. However, becausedoctest.table_1is not an output of user_1, this dependency cannot be matched to the node ID of user_1. - When you commit the sql_1 node, the system detects its upstream dependency on
doctest.table_1. Because this dependency is not associated with a node ID, the system cannot find the ancestor node and reports that the output name of the dependent ancestor node does not exist.