To configure Kafka Writer, you need to only select a table to which you want to write data and configure field mappings.
Prerequisites
A reader or conversion node is configured. For more information, see Data source types that support real-time synchronization.
Background information
Deduplication is not supported for data that you want to write to Kafka. If you reset the offset for your synchronization node or your synchronization node is restarted after a failover, duplicate data may be written to Kafka.
Procedure
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
In the Scheduled Workflow pane of the DataStudio page, move the pointer over the
 icon and choose .
icon and choose . Alternatively, find the desired workflow in the Scheduled Workflow pane, right-click the workflow name, and then choose .
In the Create Node dialog box, set the Sync Method parameter to End-to-end ETL and configure the Name and Path parameters.
Click Confirm.
On the configuration tab of the real-time synchronization node, drag Kafka in the Output section to the canvas on the right and connect the Kafka node to the configured reader or conversion node.
Click the Kafka node. In the panel that appears, configure the parameters.
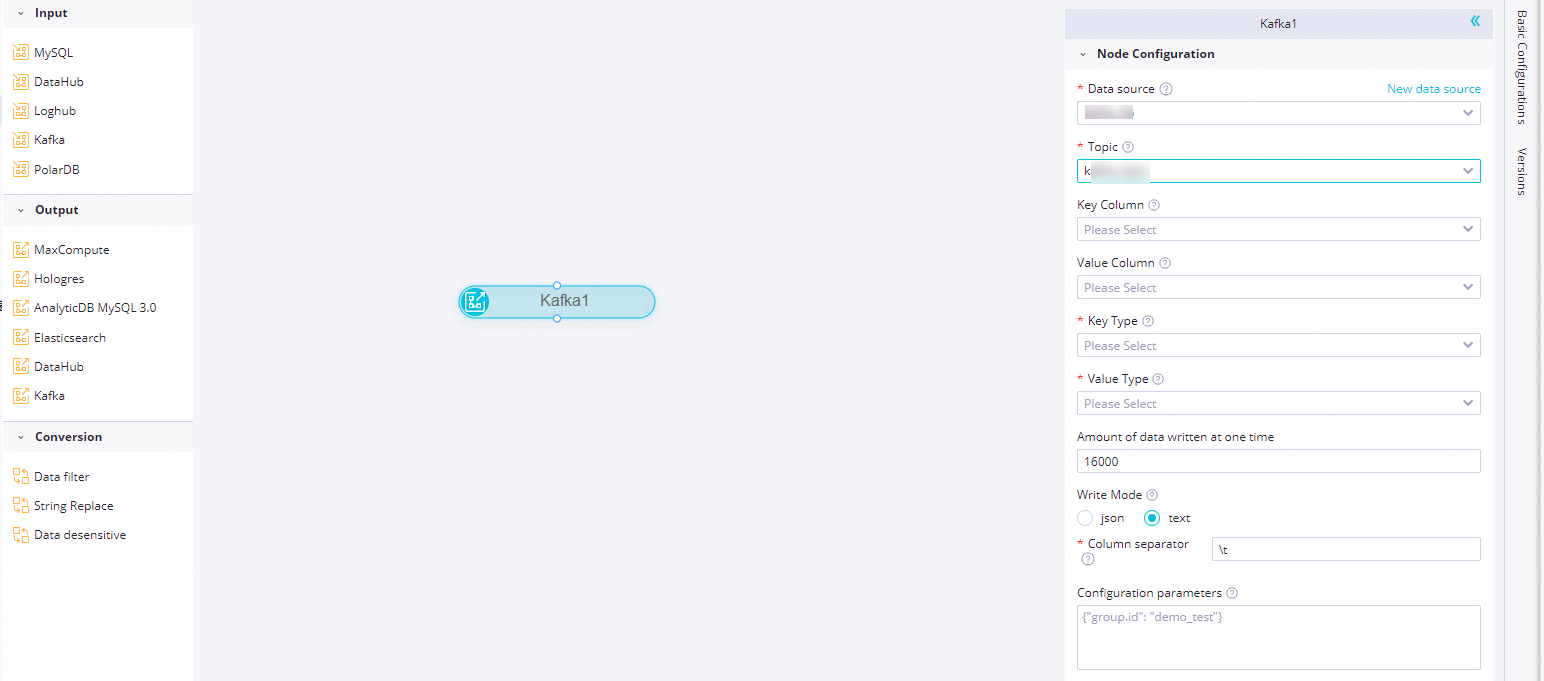
Parameter
Description
Data source
The name of the Kafka data source that you added to DataWorks. You can select only a Kafka data source. If no data source is available, click New data source on the right to go to the Data Sources page in Management Center to add a Kafka data source. For more information, see Add a Kafka data source.
Topic
The name of the Kafka topic to which you want to write data. Kafka maintains feeds of messages in categories called topics.
Each message that is published to a Kafka cluster is assigned a topic. Each topic contains a group of messages.
NoteKafka Writer in each data synchronization node can write data to only one topic.
Key Column
The name of the source column whose value in each row is used as a key in the destination Kafka topic. If you select multiple columns, the column values in each row are concatenated as a key by using commas (,). If you do not select a column, empty strings are used as keys in the destination Kafka topic.
Value Column
The names of the source columns whose values in each row are concatenated as a value in the destination Kafka topic. If you do not select a column, the values of all source columns in each row are concatenated as a value in the destination Kafka topic. The method used to concatenate the values of source columns depends on the write mode that you specify. For more information, see the parameter description that is provided in Kafka Writer.
Key Type
The data type of the keys in the Kafka topic. The value of this parameter determines the setting of key.serializer that is used to initialize a Kafka producer. Valid values: STRING, BYTEARRAY, DOUBLE, FLOAT, INTEGER, LONG, and SHORT.
Value Type
The data type of the values in the Kafka topic. The value of this parameter determines the setting of value.serializer that is used to initialize a Kafka producer. Valid values: STRING, BYTEARRAY, DOUBLE, FLOAT, INTEGER, LONG, and SHORT.
Amount of data written at one time
The number of bytes to write at a time. We recommend that you set this parameter to a value that is greater than 16000.
Write Mode
The write mode. You can use this parameter to specify the format in which Kafka Writer concatenates the values of value columns in the source. Valid values: text and json.
If you set this parameter to text, Kafka Writer concatenates the values of the columns by using the specified delimiter.
If you set this parameter to json, Kafka Writer concatenates the values of the columns as a JSON string.
For example, three columns col1, col2, and col3 are obtained as value columns from the reader, and the values of the columns in a specific row are a, b, and c. If the Write Mode parameter is set to text and the Column separator parameter is set to
#, the value stored in the destination Kafka topic isa#b#c. If the Write Mode parameter is set to json, the value stored in the destination Kafka topic is the string{"col1":"a","col2":"b","col3":"c"}.Column separator
The delimiter that is used to concatenate column values obtained from the reader if the Write Mode parameter is set to text. The values of the columns in each row are concatenated as a value in the destination Kafka topic. You can specify one or more characters as column delimiters. You can specify Unicode characters in the format of
\u0001. Escape characters such as\tand\nare supported. Default value:\t.Configuration parameters
The extended parameters that you can configure when you create a Kafka consumer. For example, you can configure the bootstrap.servers, acks, and linger.ms parameters. You can configure parameters in KafkaConfig to control the data read behavior of a Kafka consumer. For a real-time synchronization node that synchronizes data to Kafka, the default value of the acks parameter for a Kafka consumer is all. If you have higher requirements for performance, you can specify a different value for the acks parameter. Valid values of the acks parameter:
0: A Kafka consumer does not acknowledge whether data is written to the destination.
1: A Kafka consumer acknowledges that the write operation is successful if data is written to the primary replica.
all: A Kafka consumer acknowledges that the write operation is successful if data is written to all replicas.
In the top toolbar of the configuration tab of the real-time synchronization node, click the
 icon to save the node.
icon to save the node.