DataHub is an Alibaba Cloud streaming data processing platform that lets you publish, subscribe to, and distribute data streams for real-time analytics and applications.
Product overview
DataHub is a streaming data processing platform provided by Alibaba Cloud. Its core capabilities — publish, subscribe, and distribute — let you build analytics and applications for streaming data.
Key capabilities
-
Data collection: Continuously collect, store, and process high-volume streaming data from mobile devices, applications, web services, and sensors.
-
Real-time processing: Process data streams (web access logs, application events) with Flink or custom applications to generate real-time charts, alerts, and statistics.
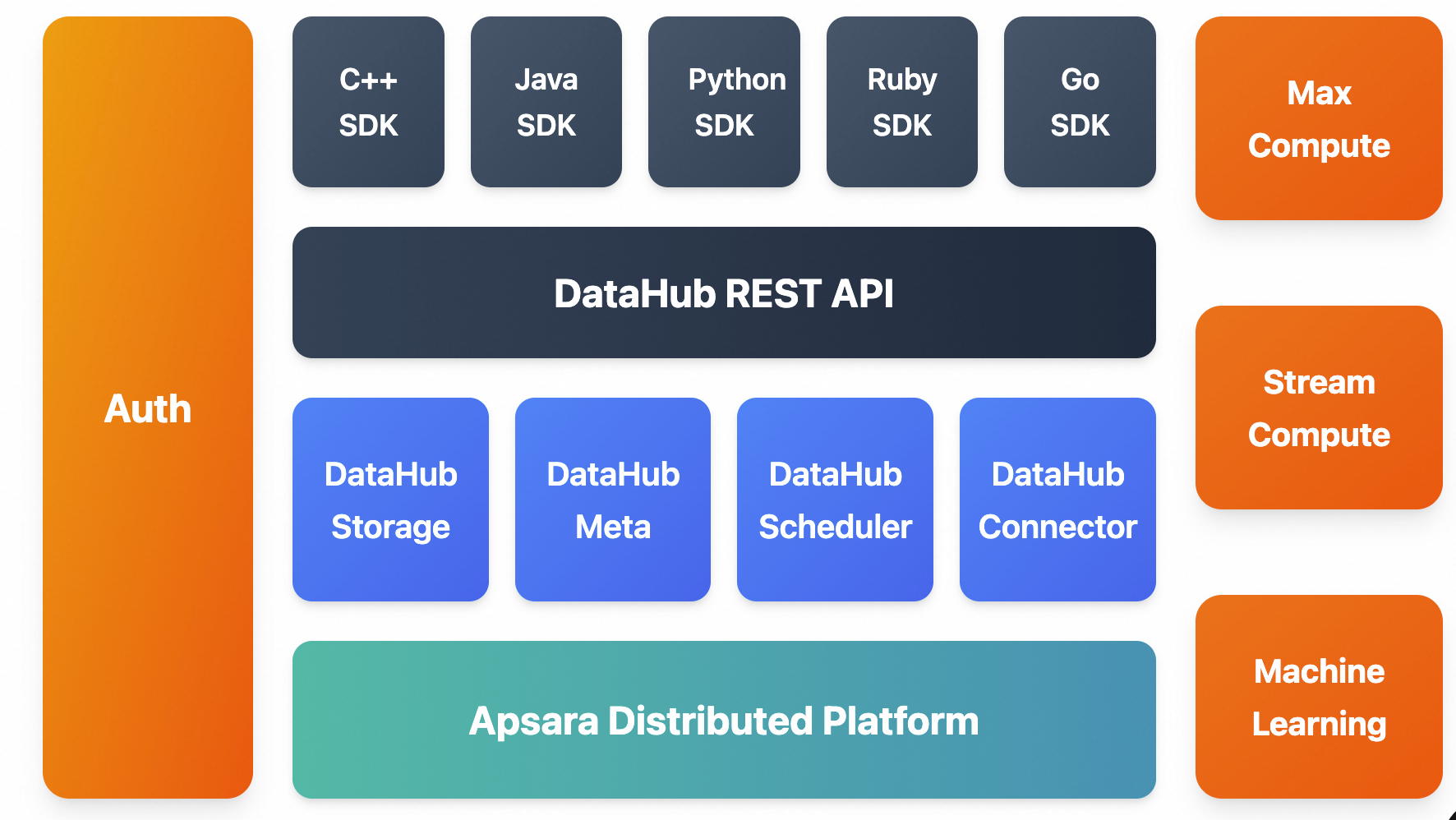
Overall architecture
-
Built on Apsara, Alibaba Cloud's proprietary distributed platform. Features high availability, low latency, high scalability, and high throughput.
-
Provides a unified REST API with SDKs for multiple languages.
-
Connects with MaxCompute, Flink, and other cloud services for SQL-based stream analytics.
-
Distributes streaming data to MaxCompute (formerly ODPS) and OSS.
Benefits
-
High throughput: Supports up to 160 million writes per day on a single Shard.
-
Timeliness: Collects and processes data from various sources in real time for rapid business response.
-
Ease of use
-
SDKs for C++, Java, Python, and Go.
-
RESTful API for custom integrations.
-
Client plug-ins for Fluentd, Logstash, and Flume.
-
Supports structured data with schemas (by creating a topic of the TUPLE type) and unstructured data (by creating a topic of the BLOB type).
-
-
High availability
-
Service availability is at least 99.9%.
-
Data durability is at least 99.999%.
-
It scales automatically without affecting external services.
-
Automatic backup for redundancy.
-
-
Dynamic scaling
Scale each Topic's throughput up or down, up to
256,000 Records/sper Topic. -
High security
-
Enterprise-grade, multilayer security with multi-user resource isolation.
-
Multiple authentication and authorization methods, including whitelists and Resource Access Management (RAM).
-
Scenarios
Combine DataHub with other Alibaba Cloud services to build end-to-end data processing solutions.
Stream computing (StreamCompute)
Real-time Compute for Apache Flink is an Alibaba Cloud stream computing engine that provides an SQL-like language for stream processing. DataHub integrates with Flink as both a data source and output destination. Real-time Computing (Stream Computing).
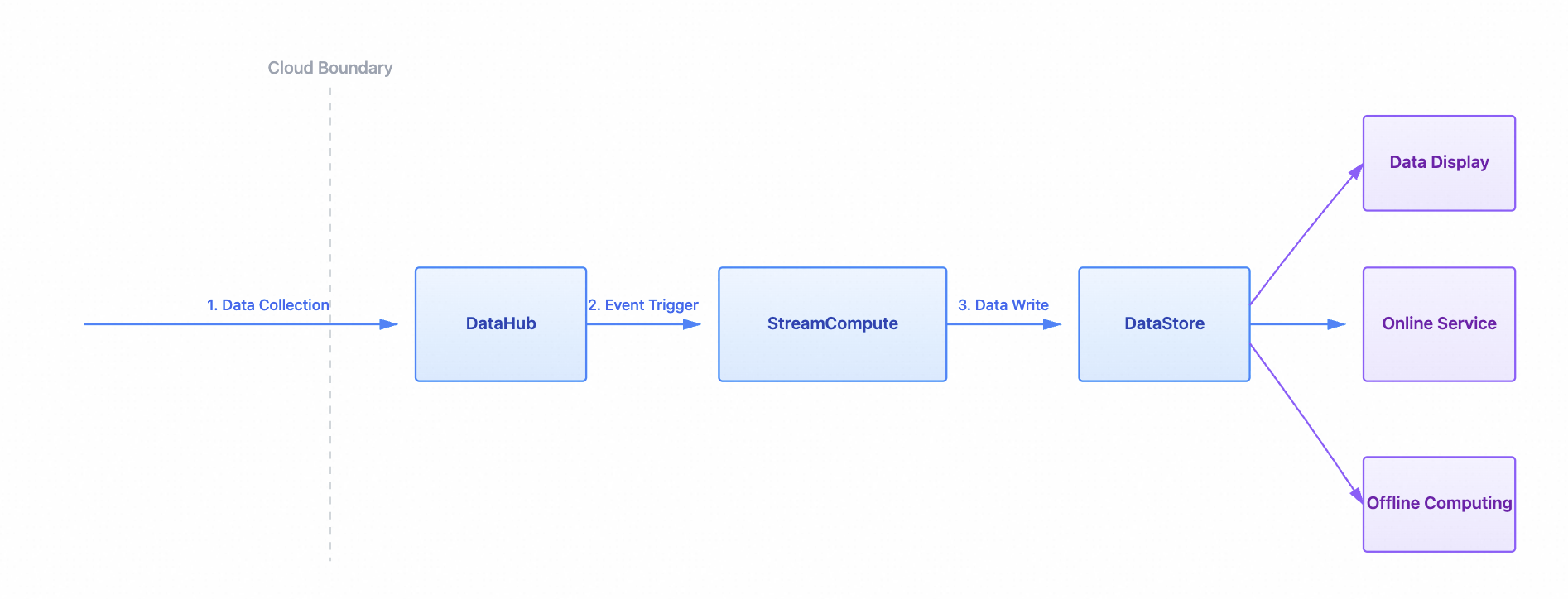
Stream processing applications
Custom applications subscribe to DataHub data, process it in real time, and output results. Results from one application can feed back into DataHub for another to process, forming a directed acyclic graph (DAG) workflow.
Streaming data archiving
Archive streaming data to MaxCompute (formerly ODPS). Create a DataHub connector to set up periodic sync tasks that archive streams automatically.