The cost-based SQL diagnostics engine in Database Autonomy Service (DAS) analyzes SQL statements, recommends indexes, and suggests query rewrites — estimating performance gains before any change is applied. It evaluates optimization candidates using the same cost model as the database optimizer, so recommendations are grounded in actual execution cost rather than heuristics.
Why SQL optimization is hard
Around 80% of database performance issues trace back to SQL. Yet SQL optimization is one of the most time-consuming tasks in database management: the optimal execution plan depends on data volume, statistics, index combinations, and query structure — all of which change constantly.
Developers often spend hours identifying slow queries, analyzing execution plans, and testing index changes. The cost-based SQL diagnostics engine automates this process, turning a manual, expertise-dependent workflow into one that runs continuously at scale.
How the engine works
The engine is an optimizer that runs independently of the database kernel. It collects statistics automatically and calculates execution plan costs without relying on the database's built-in What-If Tool (WIT) capability — a limitation common in open source databases such as MySQL.
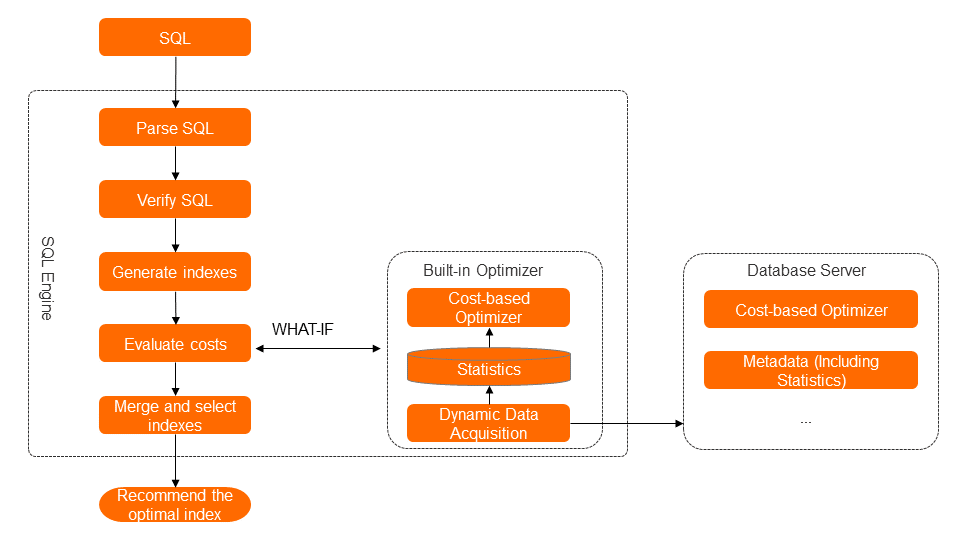
The engine processes each SQL statement through four steps:
SQL parsing and verification: Parse the SQL statement, verify syntax, identify predicates, sorting fields, aggregation fields, and query fields, and build a syntax tree. Check that all referenced tables and fields match the database schema.
Candidate index generation: Generate multiple index combinations from the syntax tree.
Cost-based evaluation: Use a built-in optimizer — independent of the database kernel — to fetch database statistics (cached in the diagnostics engine) and calculate the cost of each candidate index and each candidate SQL rewrite. Select the option with the lowest cost.
Index merging and optimal index selection: When diagnosing multiple SQL statements against the same instance, consolidate index recommendations. Identify overlapping indexes, indexes with shared prefixes, and redundant candidates to produce a minimal, effective index set.
Cost-based vs. rule-based recommendations
Two approaches exist for SQL optimization recommendations: rule-based and cost-based. DAS uses the cost-based method.
Rule-based method
The rule-based method applies fixed patterns to generate candidate indexes without evaluating cost. For a query like:
SELECT *
FROM t1
WHERE time_created >= '2017-11-25'
AND consuming_time > 1000
ORDER BY consuming_time DESC;The rule-based method generates multiple candidates with no way to rank them:
IX1(time_created)
IX2(time_created, consuming_time)
IX3(consuming_time)
IX4(consuming_time, time_created)If the query involves table joins or subqueries, the ambiguity grows further. The rule-based method cannot determine which index actually reduces execution cost.
Cost-based method
The cost-based method evaluates every candidate against database statistics and selects the one with the lowest calculated cost — the same way the database optimizer works. For non-deterministic polynomial (NP) problems where exhaustive evaluation is infeasible, the engine evaluates as many candidates as possible to find a near-optimal solution.
This approach requires two capabilities that open source databases like MySQL lack by default:
WIT capability: Needed to simulate the cost of a hypothetical index without creating it. DAS implements this independently of the database kernel.
Statistics: Needed to calculate execution plan costs accurately. DAS collects and caches statistics automatically.
Capability validation
The engine's recommendation quality is continuously measured against a signature-based test case library. Each test case is described by its signature — a fingerprint of the SQL pattern, schema, statistics, and environment parameters involved.
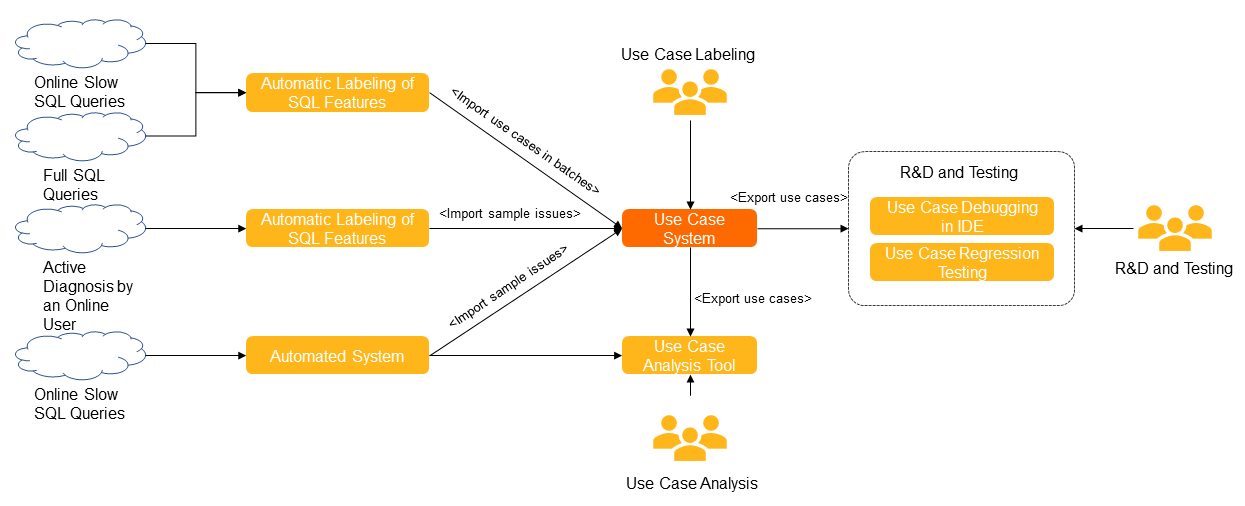
Test cases are sourced from SQL statements executed across Alibaba Group's internal services. All extracted data — including statistical information — is encrypted and masked through an automated process.
The library is evaluated along four dimensions:
Signature coverage: which signatures in the library are covered by existing test cases
Gap analysis: which signatures are not yet covered or fail SQL verification
Regression tracking: which signatures show recurring failures over time
Coverage rate by capability level
This feedback loop continuously drives improvements to the engine's recommendation accuracy.
Optimization modes
Before its release on Alibaba Cloud, the engine ran on Alibaba Group's internal services for years, diagnosing an average of approximately 50,000 SQL statements per day. DAS exposes this capability in two modes:
Custom optimization: Submit specific SQL statements for diagnosis. The engine returns index recommendations and SQL rewrite suggestions with estimated performance improvement.
Automatic optimization: DAS monitors instance workloads, identifies slow queries, diagnoses them, and generates optimization suggestions. After validating each suggestion, DAS schedules the optimization, applies it online, and monitors post-change performance. The entire process runs without manual intervention.
Rollback cases from automatic optimization, failed diagnostics, and user-reported issues are automatically fed back into the test case library to improve future recommendations.
Supported database engines
The cost-based SQL diagnostics engine supports the following database engines:
ApsaraDB RDS for MySQL
PolarDB for MySQL
ApsaraDB RDS for PostgreSQL
PolarDB for PostgreSQL (Compatible with Oracle)