This topic lists common issues when using ALB Ingress.
Feature questions
How does ALB Ingress differ from Nginx Ingress?
Use ALB Ingress. Unlike Nginx Ingress, which requires you to manage the infrastructure yourself, ALB Ingress is built on Alibaba Cloud Application Load Balancer (ALB) and is fully managed. It requires no operations or maintenance. ALB Ingress provides more powerful Ingress traffic management and high-performance gateway services. For a detailed comparison of Nginx Ingress, ALB Ingress, and MSE Ingress, see Comparison of Nginx Ingress, ALB Ingress, and MSE Ingress.
Does ALB Ingress support both public and private network access?
Issue
In real-world scenarios, you need to access ALB Ingress over both the public and private networks. But you are unsure whether ALB Ingress supports both simultaneously.
Solution
Yes. To use both public and private network access, create a public ALB instance. The instance creates an elastic IP address (EIP) in each zone. ALB uses these EIPs for public network communication. The instance also provides a private virtual IP address (VIP). Use this private VIP to access ALB over the private network. If you require only private network access, create a private ALB instance.
How do I ensure ALB Ingress uses a fixed ALB domain name?
After you create an ALB instance with AlbConfig, ALB Ingress references the AlbConfig through an IngressClass. This enables ALB Ingress to use the domain name of the corresponding ALB instance. As long as the IngressClass and AlbConfig associated with ALB Ingress remain unchanged, the domain name stays the same.
Why can’t I find the ALB Ingress Controller pod in my cluster?
Issue
When you search for the ALB Ingress Controller pod in your cluster, you find no related pods in the kube-system namespace. You cannot view the ALB Ingress Controller component using standard methods.
Solution
You can see the ALB Ingress Controller pod in the kube-system namespace only in ACK dedicated clusters. ACK Basic Edition, ACK Pro Edition, and ACK Serverless fully manage the ALB Ingress Controller component. So you cannot see the pod in those clusters. For instructions on upgrading an ACK dedicated cluster to an ACK managed cluster Pro Edition, see Hot migrate an ACK dedicated cluster to an ACK managed cluster Pro Edition.
How do I support attaching IP-type servers?
Issue
You want to attach backend pods to ALB by IP address. But by default, the Service does not automatically create an IP-based server group. This limits traffic distribution to backend services.
Solution
Add the annotation alb.ingress.kubernetes.io/server-group-type: Ip to the Service. This creates an IP-based server group for the Service. Then you can register backend pods with ALB by IP address.
You cannot change the server group type after creation. In Flannel network mode, switching the Service type—for example, between ClusterIP and NodePort—switches the node attachment type between IP and ECS. This prevents nodes from joining the original server group. So you cannot directly change the Service type.
To change the server group type, create a new Service. In its annotations, specify
alb.ingress.kubernetes.io/server-group-type: Ip. This avoids affecting existing server group node attachments.If the Service referenced by the Ingress does not exist yet, the ALB Ingress Controller creates the server group before it can read the Service annotations. It then configures the server group as instance type by default. This causes IP-based server attachment to fail. To avoid this, create the Service before creating the Ingress.
After you set the annotation
alb.ingress.kubernetes.io/server-group-type: Ip, do not delete it. Deleting it causes inconsistency between the server group type and the Service. This leads to reconciliation failures and prevents backend nodes from joining the server group.
apiVersion: v1
kind: Service
metadata:
annotations:
alb.ingress.kubernetes.io/server-group-type: Ip
name: tea-svc
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
selector:
app: tea
type: ClusterIPWhat is the purpose of the default server group kube-system-fake-svc-80 used by ALB backends?
A listener must have a default forwarding rule. Forwarding rules currently support only forwarding to a server group. So the kube-system-fake-svc-80 server group is required to enable listeners. This server group does not handle business traffic, but you must not delete it.
How do I configure domain name resolution for Ingress?
This example shows how to add a DNS record with the record type set to
CNAME, the host record set to@(which indicates that the root domain, such asingress-demo.com, is resolved directly), and the record value set to the Ingress endpoint address.In a browser, go to http://ingress-demo.com/coffee to verify that the domain name resolution is effective.
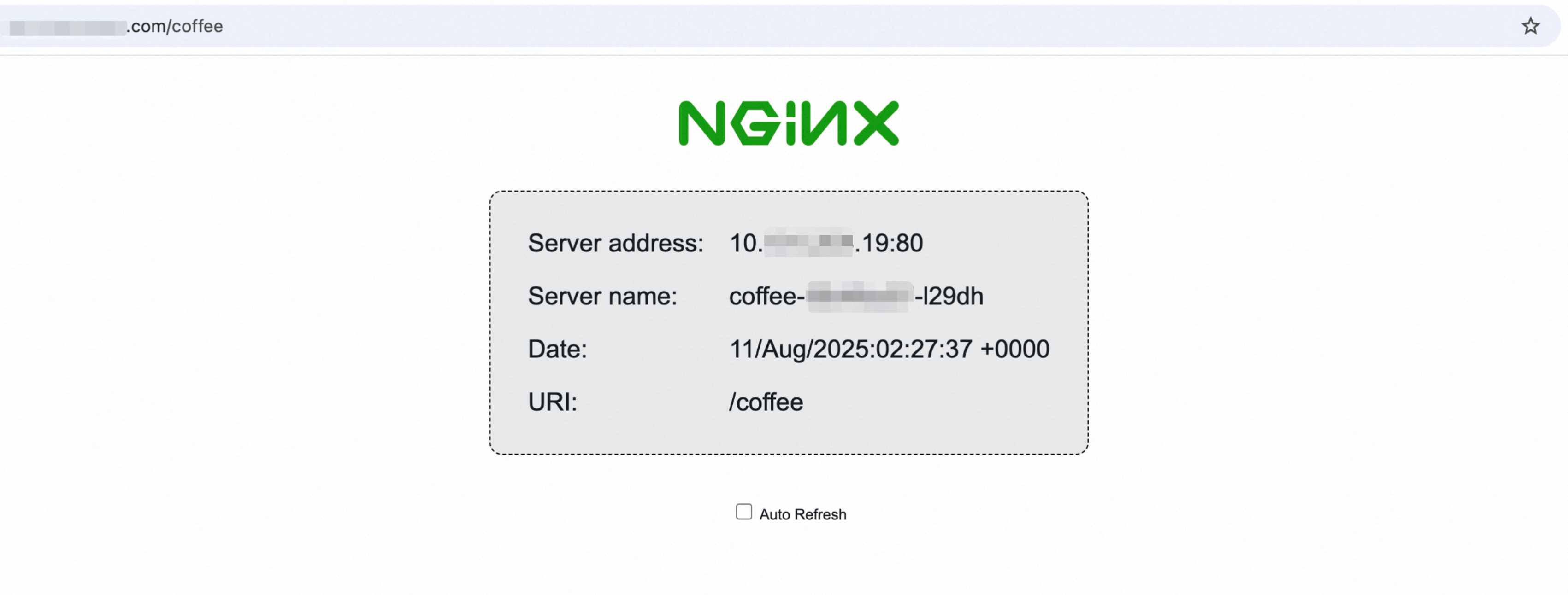
Replace the domain name with your actual registered domain name for verification. If the domain name resolution does not work, see Quickly troubleshoot DNS resolution failures.
How do I configure HTTPS encryption for Ingress?
Purchase an official certificate, complete the certificate request, and confirm that your certificate is in the Issued status.
This example shows how to download the PEM-formatted certificate file for the
ingress-demo.comdomain name. The server type is set to Other.Create a secret to store the certificate files.
On the Clusters page, click the name of your cluster. In the navigation pane on the left, click .
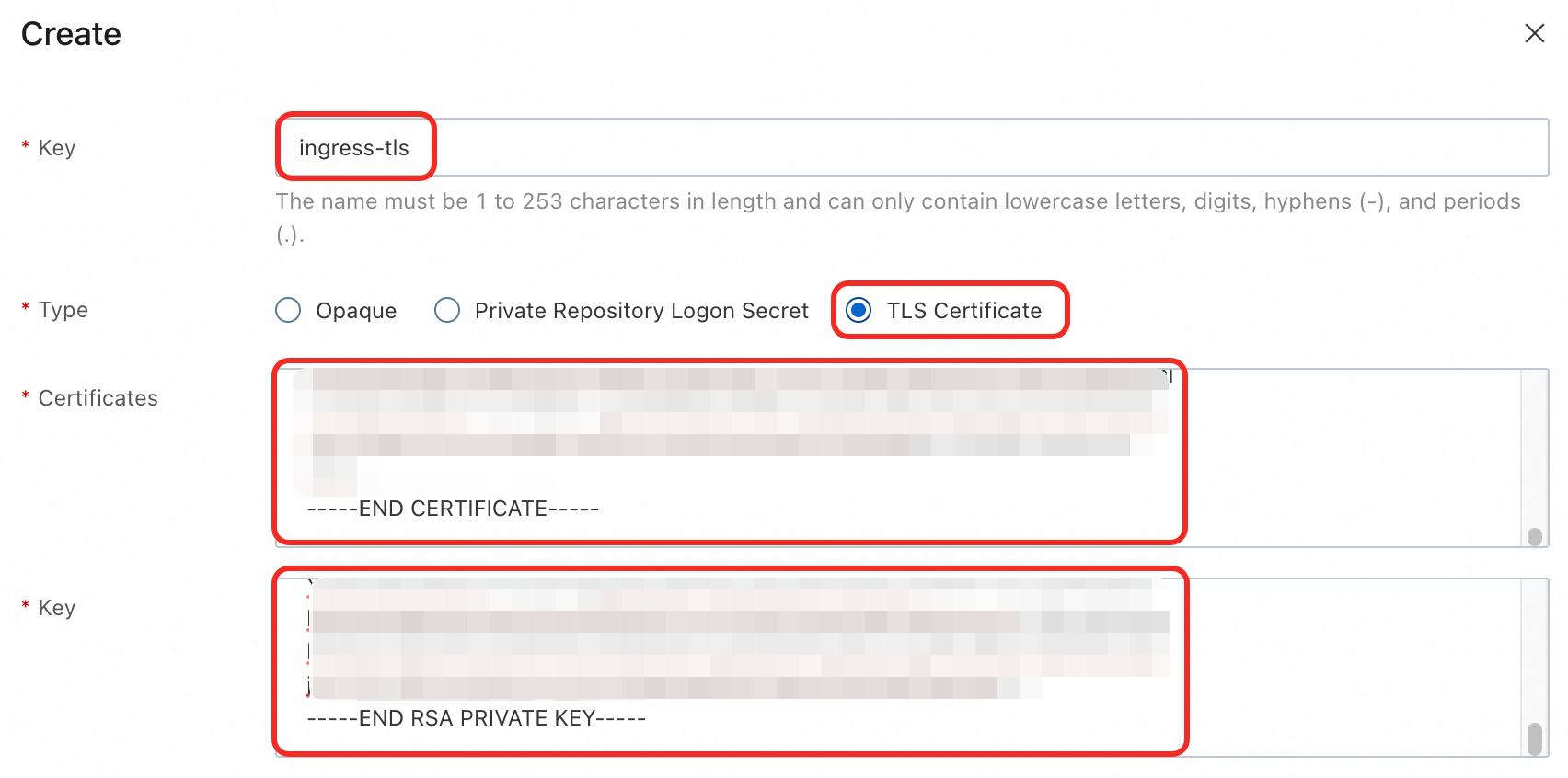
On the Secrets page, select the
defaultnamespace and click Create in the upper-left corner. Add the following configuration and click OK.Name:
ingress-tlsType: TLS Certificate
Certificate: The content of the downloaded certificate file (.pem).
Key: The content of the downloaded private key file (.key).
Update the AlbConfig to add an
HTTPS:443listener for the ALB instance.In the navigation pane on the left, choose . On the Resource Objects tab, search for and click AlbConfig.
In the list of AlbConfig resource objects, find the target resource
alband click Edit YAML in the Actions column.Add the
spec.listeners.port: 443andspec.listeners.protocol: HTTPSfields, and then click OK.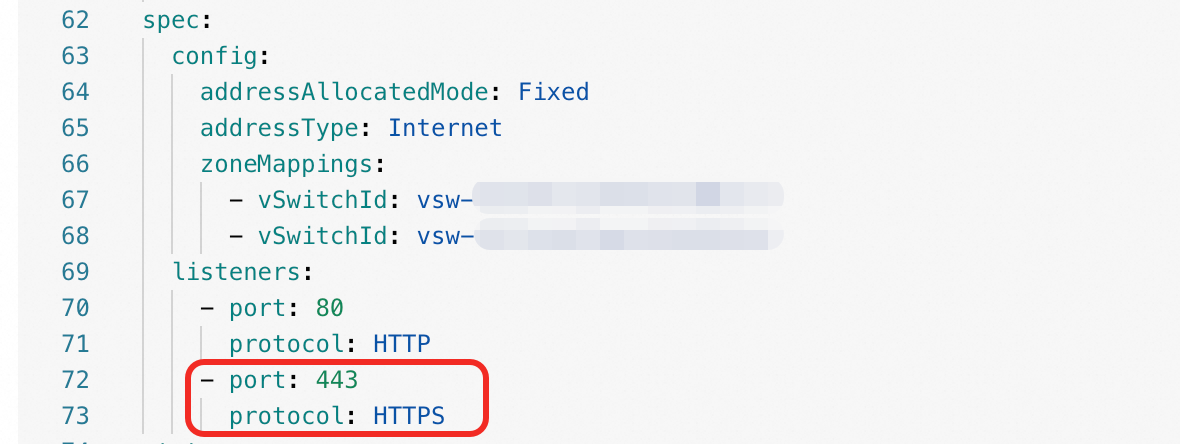
Update the Ingress to add a TLS configuration and associate the
HTTPS:443listener.In the navigation pane on the left, choose . In the Actions column of the target Ingress, click Update.
Add the following configuration and click OK.
TLS Settings: Enabled
Domain Name:
ingress-demo.comSecret:
ingress-tlsAnnotation:
alb.ingress.kubernetes.io/listen-ports: [{"HTTP": 80}, {"HTTPS": 443}]
In a browser, go to
https://ingress-demo.com/coffeeto verify that HTTPS access is encrypted.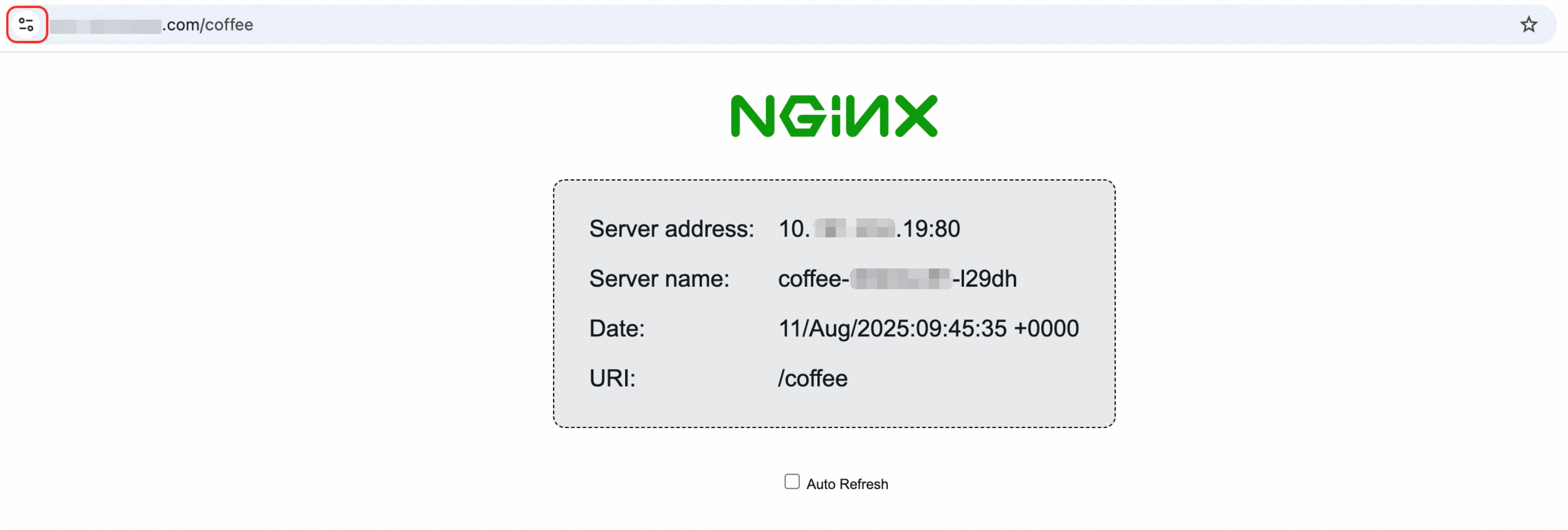
Replace the domain name with your actual registered domain name for verification.
For more information about how to configure HTTPS certificates, see Configure HTTPS certificates for encrypted communication.
Usage anomalies
Why does my ALB instance downgrade from WAF Enhanced Edition to Standard Edition?
Root cause
After you manually enable WAF protection for your ALB instance in the WAF console, the ALB Ingress Controller detects during reconciliation that the actual edition of the ALB instance does not match the edition field declared in AlbConfig. If AlbConfig does not explicitly specify edition: StandardWithWaf, the Controller reverts the instance to the default Standard Edition. This downgrades WAF to Standard Edition.
Solution
To keep WAF Enhanced Edition, explicitly set the edition field to StandardWithWaf in AlbConfig when you create a new ALB instance or upgrade or downgrade an existing one.
Why do I get HTTP error codes such as 503, 502, and 404 when accessing the Ingress domain name?
Root cause
503 (Service Temporarily Unavailable) error
No matching routing rule: The request path does not match the routing rule configured in the Ingress.
No healthy backend pods: All pods associated with the service are not ready or do not exist. This results in an empty endpoint object.
502 (Bad Gateway) error
An HTTP or HTTPS listener receives a client connection request. If the ALB instance cannot forward the request to a pod or receive a response from a pod, the instance sends an HTTP 502 Bad Gateway status code to the client.
404 (Not Found) error
This usually means the request matched a routing rule defined in the Ingress, but does not match the actual service URL provided by the application in the pod.
400 (Bad Request) error
This can occur for various reasons, such as an HTTP request being sent to an HTTPS listener.
For more information about HTTP error codes, see ALB status codes.
Solution
Check the Ingress status. Run the
kubectl describe ingress <ingress-name> -n <namespace>command and inspect the Events section for error messages. For example, if you see an event similar tolistener does not exist in alb, you must create the listener required for the Ingress resource in the AlbConfig.... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedBuildModel **** ingress listener is not exist in alb, port: 443, protocol: HTTPS Warning FailedBuildModel **** ingress listener not found for (443/HTTPS), with ingresses 1 ...Check the backend endpoints. Run the
kubectl get endpoints <service-name> -n <namespace>command to confirm that theENDPOINTSfield contains at least one healthy pod IP address and port. If the field is empty, verify that the service'sselectormatches thelabelson your pods, and ensure the pods are in theRunningstate.Check the pod status and logs. First, run the
kubectl get pod -l <app=your-app> -n <namespace>command to check the status of your application pods. Then, runkubectl logs <pod-name> -n <namespace>to inspect the logs of a specific pod for any startup failures or request processing errors.Test network connectivity. From within another pod or directly from a node, use
curlto access the backend service's ClusterIP or a direct pod IP. This verifies that the service is reachable from within the cluster.
After configuring Ingress TLS, why is HTTPS still inaccessible?
Root cause
The ALB instance is not listening on port 443. You have configured TLS encryption for the Ingress, but the corresponding
HTTPS:443listener has not been created.The certificate is configured incorrectly. The secret type is not
kubernetes.io/tlsorIngressTLS, or the content oftls.crtandtls.keyin thedatafield is incorrect or mismatched.The certificate update has not taken effect. You updated the certificate in the Alibaba Cloud Certificate Management Service, but you did not update the certificate ID specified in the AlbConfig, or the automatic certificate discovery reconciliation was not triggered. As a result, the ALB instance still references the old certificate.
Solution
Check the listener port. Run the
kubectl describe albconfig <alb-name> -n <namespace>command to check whether thespec.listeners.port: 443andspec.listeners.protocol: HTTPSconfigurations are missing.Check the Ingress configuration. Check whether the Ingress configuration is missing the
alb.ingress.kubernetes.io/listen-ports: [{"HTTP": 80}, {"HTTPS": 443}]annotation. This annotation associates the Ingress with the HTTP and HTTPS listeners.Check the secret configuration. Check the
secretNamefield ofspec.tlsin the Ingress configuration to confirm that the correct secret is referenced. Run thekubectl get secret <secret-name> -n <namespace> -o yamlcommand to confirm the secret type and data integrity.
Why are my ALB Ingress rules not taking effect?
Issue
After you create new ALB Ingress rules, they do not take effect as expected. Traffic does not forward to the intended backend services.
Root cause
ALB instances maintain routing rules in serial order. If multiple ALB Ingress resources use the same ALB instance, a misconfiguration in one ALB Ingress prevents all other ALB Ingress changes from taking effect.
Solution
If your ALB Ingress does not take effect, a previous ALB Ingress may be misconfigured. Fix the misconfigured ALB Ingress first. Then your new ALB Ingress will take effect.
ALB Ingress reports no anomalous activity, but changes do not take effect. What should I do?
Issue
After you change ALB Ingress configuration or associate it with AlbConfig, no anomalous activity appears. But the changes do not take effect.
Solution
This may happen if the binding between IngressClass and AlbConfig is incorrect. Check the parameters field in your IngressClass. For step-by-step instructions, see Associate AlbConfig with Ingress using IngressClass.
ALB Ingress forwarding rules are deleted immediately after creation, causing 503 status codes. What should I do?
Issue
ALB Ingress forwarding rules are deleted right after creation. This returns 503 status codes and stops traffic distribution.
Solution
Check whether all Ingress resources linked to the forwarding rules have the canary: true annotation. Canary releases require a baseline version to route traffic. So you do not need to add canary: true to the baseline Ingress. For instructions on using ALB Ingress for phased releases, see Implement phased releases with ALB Ingress.
Canary releases support only two Ingress resources and have limited conditions. We recommend custom forwarding rules for richer traffic routing options. For instructions, see Customize ALB Ingress forwarding rules.
AlbConfig reports “listener is not exist in alb, port: xxx”
Issue
Requests to ports other than port 80 fail to connect. AlbConfig reports “listener is not exist in alb, port: xxx”. So those ports are not listening or forwarding traffic.
Solution
The default AlbConfig includes only a listener for port 80. To listen on other ports, add listener configurations for those ports in AlbConfig. For instructions, see Create listeners.
After configuring HTTP and HTTPS listeners in AlbConfig, why can’t I access them?
Issue
I configured HTTP and HTTPS listeners in AlbConfig. But I cannot access either port. Traffic is not being listened to or forwarded.
Solution
Confirm that you added the alb.ingress.kubernetes.io/listen-ports annotation to the Ingress resource. This annotation tells ALB Ingress to listen on both HTTP (port 80) and HTTPS (port 443). For example:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: https-ingress
annotations:
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80},{"HTTPS": 443}]' # Add this annotation to make ALB Ingress work with multiple listeners.
spec:
#...Why do manual configuration changes in the ALB console get lost? Why are rules deleted and access logs disabled?
Issue
After I manually change configurations in the ALB console, those changes disappear or get deleted. Access logs also get disabled.
Solution
ALB Ingress updates configurations by changing resources in your cluster. These configurations are stored in the cluster’s API server as ALB Ingress or AlbConfig resources. Manual changes in the ALB console do not update the API server. So those changes do not take effect. When reconciliation runs, it overwrites console configurations with the values from Ingress or AlbConfig. To avoid this, update configurations by changing ALB Ingress or AlbConfig resources.
Why does an error message appear during the tuning process: Specified parameter array contains too many items, up to 15 items, Certificates is not valid?
Issue
During reconciliation, I get the error “Specified parameter array contains too many items, up to 15 items, Certificates is not valid”. So ALB Ingress cannot associate with the required certificates.
Solution
Starting with ALB Ingress Controller v2.11.0-aliyun.1, certificate pagination is supported. If you see this error, your current ALB Ingress Controller version does not support certificate pagination. And your use case tries to associate more than 15 certificates in one reconciliation. To fix this, upgrade your ALB Ingress Controller to the latest version. For version information, see ALB Ingress Controller. For upgrade instructions, see Manage ALB Ingress Controller components.
After I configure an ALB instance in the console, why does running kubectl apply to update AlbConfig ACL settings delete some listeners?
Issue
After I create and configure an ALB instance in the console, I run kubectl apply to update the AlbConfig ACL settings. Some listeners are unexpectedly deleted. So their ports or rules stop working.
Solution
We recommend that you use the kubectl edit command to directly update the configuration of resources. If you must use the kubectl apply command to update resources, run the kubectl diff command before you run kubectl apply to preview the changes, verify that the changes match your expectations, and then use kubectl apply to apply the changes to your Kubernetes cluster.
The kubectl apply command performs an overwrite update on AlbConfig. So when you use kubectl apply to update AlbConfig ACL settings, include the full listener configuration in your YAML file. Otherwise, listeners not listed will be deleted.
If listeners are deleted after running kubectl apply, restore them as follows.
Check whether your YAML file lists all listeners.
If it is missing deleted listeners, continue to the next step. Otherwise, skip.
Run the following command to edit the AlbConfig and add back the deleted listeners.
kubectl -n <namespace> edit albconfig <albconfig-name> # Replace <namespace> and <albconfig-name> with the namespace and name of your AlbConfig resource.
Performance tuning
How do I reduce server reconciliation time during pod scaling in a Service?
Issue
In Kubernetes, server reconciliation takes too long when pods attached to a Service scale. This affects real-time elasticity. Investigation shows that reconciliation time increases with the number of associated Ingress resources.
Solution
To improve server tuning efficiency, you can apply the following optimization measures:
Limit Ingress count: Attach no more than 30 Ingress resources to one Service.
Combine Ingress rules: If you have many Ingress resources, attach multiple Services to one Ingress. Define multiple forwarding rules in that Ingress to improve server reconciliation performance.
When using the Flannel plugin and Local-mode Services, how do I auto-assign node weights?
Issue
When using the Flannel plugin with Local-mode Services, traffic distribution across nodes is uneven. Some nodes carry higher loads than others. How do I auto-assign node weights based on pod count per node to achieve balanced traffic distribution?
Solution
Starting with ALB Ingress Controller v2.13.1-aliyun.1, node weight auto-assignment is supported. Upgrade to the latest version to use this feature. For more information, see Upgrade ALB Ingress Controller components.
In Flannel clusters, when a Service is in Local mode, node weights are calculated as shown in the diagram below. In this example, application pods (app=nginx) run on three ECS instances. Service A exposes them externally.
Total number of backend pods in the Service | Description |
Pod count ≤ 100 | The ALB Ingress Controller sets each node’s weight to the number of pods on that node. Example: As shown above, the three ECS instances have 1, 2, and 3 pods. Their weights are set to 1, 2, and 3. So traffic is distributed in a 1:2:3 ratio across the three ECS instances. This achieves more balanced pod load distribution. |
Pod count > 100 | The ALB Ingress Controller calculates node weight as the percentage of total pods running on that node. Example: If the three ECS instances have 100, 200, and 300 pods, their weights are set to 16, 33, and 50. So traffic is distributed in a 16:33:50 ratio across the three ECS instances. This achieves more balanced pod load distribution. |