Self-managed ClickHouse clusters are hard to scale, costly to maintain, and lack enterprise-grade disaster recovery. This topic explains how to migrate your data to an ApsaraDB for ClickHouse Community-Compatible Edition cluster.
Choose a migration method
| Method | Pros | Cons | Use when |
|---|---|---|---|
| Console migration | Guided interface. No manual metadata migration. | Migrates only the entire cluster — no per-database, per-table, or historical data selection. | Migrating an entire cluster within data volume limits. |
| Manual migration | Full control over which databases and tables to migrate. | Complex operations. Metadata migration is manual. | Migrating specific databases or tables; cold data exceeds 1 TB; hot data exceeds 10 TB; or cluster does not meet console migration requirements. |
Prerequisites
Before you begin, make sure that you have:
A destination ApsaraDB for ClickHouse Community-Compatible Edition cluster with an account that has the highest permissions. See Account management for Community-Compatible Edition clusters and Modify permissions
A self-managed ClickHouse cluster account with read permissions on databases and tables, and permissions to run SYSTEM commands
Network connectivity between the destination cluster and the self-managed cluster
Same Virtual Private Cloud (VPC): Add the IP addresses of all destination cluster nodes and the IPv4 CIDR Block of its vSwitch ID to the self-managed cluster's whitelist.
To view node IP addresses:
SELECT * FROM system.clusters;To get the vSwitch ID: go to the Cluster Information page of the destination cluster and find the Network Information section in the ApsaraDB for ClickHouse console
To view the IPv4 CIDR Block: search by vSwitch ID in the vSwitch list
To configure the whitelist: see Configure an IP address whitelist
Different VPCs, local data center, or another cloud: Resolve network connectivity before migrating. See How do I establish a network connection between a destination cluster and a data source?
Validate in a test environment first
Before migrating production data, run the full migration procedure in a test environment to verify business compatibility and performance. This identifies problems before they affect production.
Create a migration task using the steps in the Console migration or Manual migration section.
Analyze compatibility and performance. See Analysis and solutions for compatibility and performance bottlenecks in migrating self-managed ClickHouse to the cloud.
Console migration
Console migration provides a guided interface and handles metadata automatically, but has the following constraints.
Limitations
The destination cluster version must be 21.8 or later.
Supports only full and incremental migration of the entire cluster. Individual databases, tables, or historical data snapshots cannot be selected.
Data volume limits
| Data type | Limit | Behavior when exceeded |
|---|---|---|
| Cold data | Recommended total ≤ 1 TB | Slow migration; high risk of task failure |
| Hot data | ≤ 10 TB | High probability of failure |
If your data volume exceeds these limits, use Manual migration instead.
What gets migrated
Migrated:
Databases, data dictionaries, and materialized views
Table schemas for all table engines except Kafka and RabbitMQ
Data from MergeTree family tables (incremental migration)
Not migrated:
Kafka and RabbitMQ table schemas and their data
Data in non-MergeTree tables (external tables, Log tables)
Handle unsupported content manually during the migration process. Steps are included in the procedure below.
Potential impacts
Self-managed cluster:
Increased CPU and memory usage from read operations
DDL operations are blocked
Destination cluster:
Increased CPU and memory usage from write operations
DDL operations are blocked
DDL operations are blocked on migrated databases and tables (this restriction does not apply to other databases and tables)
Merges are paused on migrated databases and tables (merges on other databases and tables are not affected)
The cluster restarts at the start and end of the migration task
After migration completes, the cluster runs high-frequency merges, which increases I/O usage and request latency. Calculate the expected merge duration using Calculate post-migration merge time.
If migration takes too long, metadata accumulates in the destination cluster. Complete the migration within 5 days of creating the task.
Procedure
Step 1: Enable system tables in the self-managed cluster
Console migration requires system.part_log and system.query_log to be enabled and correctly configured in the self-managed cluster's config.xml.
Logs not enabled
If `system.part_log` and `system.query_log` are not enabled, add the following blocks to config.xml:
system.part_log
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>system.query_log
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>Logs enabled
If `system.part_log` and `system.query_log` are already enabled, compare the existing configuration with the blocks above. If they differ, update them to match, then drop and recreate the tables:
system.part_log
system.query_log
DROP TABLE system.part_log;
DROP TABLE system.query_log;The tables are recreated automatically on the next data insert.
Step 2: Set compatibility on the destination cluster
Configure the destination cluster to use the same compatibility level as the self-managed cluster. This minimizes changes required after migration.
Check the version of both clusters:
SELECT version();If the versions differ, set the compatibility parameter on the destination cluster to match the self-managed cluster version. For example:
SET GLOBAL compatibility = '22.8';
Step 3 (Optional): Enable the MaterializedMySQL engine
If the self-managed cluster has tables using the MaterializedMySQL engine, run the following on the destination cluster:
SET GLOBAL allow_experimental_database_materialized_mysql = 1;The ClickHouse community no longer maintains the MaterializedMySQL engine. After migration, use Data Transmission Service (DTS) to synchronize MySQL data with ReplacingMergeTree tables instead. See Use seamless integration to synchronize data from ApsaraDB RDS for MySQL to an ApsaraDB for ClickHouse cluster and Synchronize data from ApsaraDB RDS for MySQL to an ApsaraDB for ClickHouse cluster.
Step 4: Create a migration task
Log in to the ApsaraDB for ClickHouse console.
On the Clusters page, select Clusters of Community-compatible Edition and click the destination cluster ID.
In the left navigation pane, click Data Migration and Synchronization > Migrate from ClickHouse.
Click Create Migration Task.
Configure the source cluster connection settings: To get IP addresses and ports for the source cluster:
replica_num = 1selects the first replica set. You can select other replica sets as needed.Cross-account or cross-region migration
Cross-account or cross-region Alibaba Cloud ClickHouse instance: ``
sql SELECT shard_num, replica_num, host_address AS ip, port FROM system.clusters WHERE cluster = 'default' AND replica_num = 1;``Non-Alibaba Cloud instance migration
Non-Alibaba Cloud ClickHouse instance: ``
sql SELECT shard_num, replica_num, host_address AS ip, port FROM system.clusters WHERE cluster = '<cluster_name>' AND replica_num = 1;``Source cluster parameters
Source cluster settings:
Field Description Example Source Access Method Select Express Connect, VPN Gateway, Smart Access Gateway, or Self-managed ClickHouse Clusters on an ECS Instance. — Cluster Name A name for the source cluster. Digits and lowercase letters only. sourceSource Cluster Name The internal cluster name from SELECT * FROM system.clusters;.defaultVPC IP Address TCP IP:PORT pairs for each shard, comma-separated. Do not use VPC domain names or SLB addresses. Format: IP:PORT,IP:PORT,...192.168.0.5:9000,192.168.0.6:9000Database Account Account for the source cluster. testDatabase Password Password for the source cluster account. — Destination cluster parameters
Destination cluster settings:
Field Description Database Account Account for the destination cluster. Database Password Password for the destination cluster account. 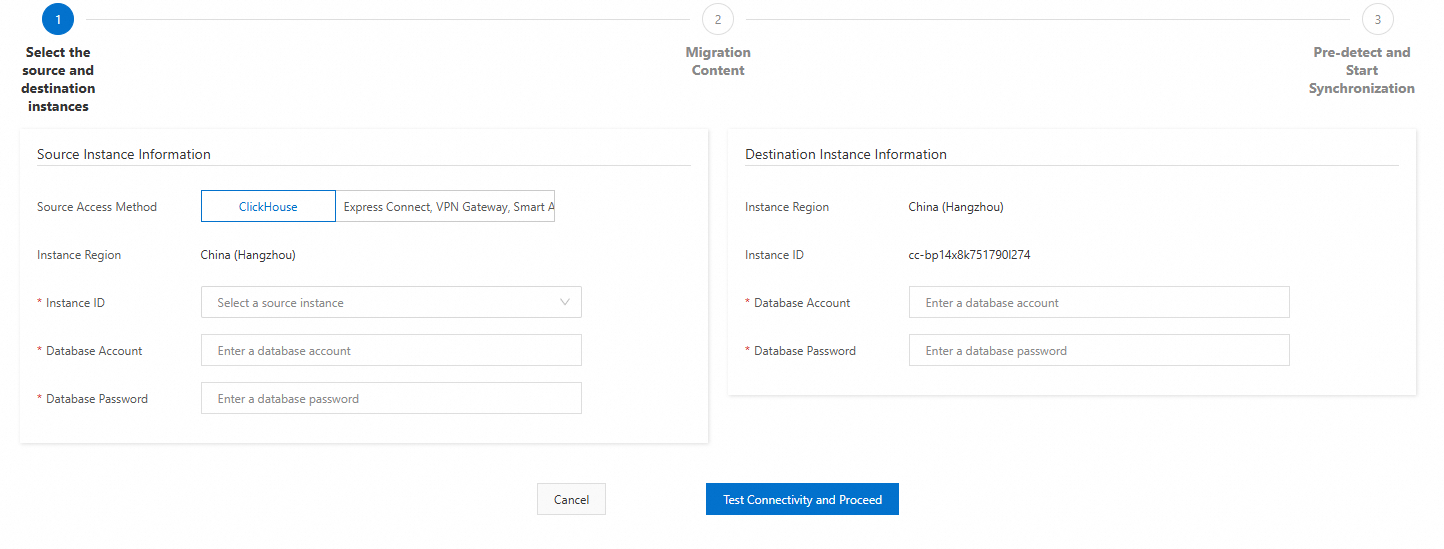
Click Test Connection and Proceed. If the test fails, fix the connection settings and try again.
Review the migration content and click Next: Pre-detect and Start Synchronization.
The system runs three pre-checks. If all checks pass: If a check fails, follow the error guidance in Pre-check error messages and solutions.
Read the impact prompts carefully.
Click Completed to create and start the task.
Check item Requirement Instance Status Detection No running management tasks (scale-out, upgrade, or downgrade) on either cluster. Storage Space Detection Destination cluster storage ≥ 1.2× the used space of the self-managed cluster. Local Table and Distributed Table Detection Each local table in the self-managed cluster must have exactly one corresponding distributed table. 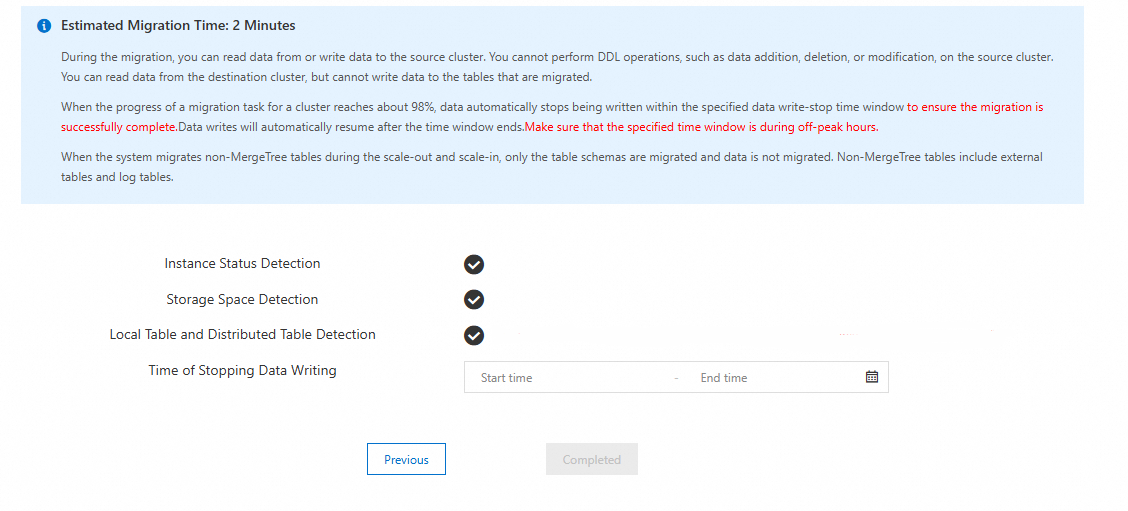
Step 5: Assess whether the migration can complete
Skip this step if the source cluster write speed is less than 20 MB/s.
If the source cluster write speed exceeds 20 MB/s, check that the destination cluster can keep up:
View the Disk throughput metric on the destination cluster. See View cluster monitoring information.
Compare write speeds:
Destination write speed > source write speed: migration is likely to succeed. Continue to Step 6.
Destination write speed < source write speed: migration is likely to fail. Cancel the task and use Manual migration instead.
Step 6: Monitor the migration task
Log in to the ApsaraDB for ClickHouse console.
On the Clusters page, select Clusters of Community-compatible Edition and click the destination cluster ID.
In the left navigation pane, click Data Migration and Synchronization > Migrate from ClickHouse.
Monitor the task status and Running Information column.
Track the estimated remaining time shown in the Running Information column. When the task is nearing completion, follow Step 7 to stop writes and handle Kafka and RabbitMQ tables.
To view task details, click View Details in the Actions column. The details page shows migrated table schemas, database structures, and any error messages.
After the task ends (status: Completed or Canceled), the View Details page is cleared. To view migrated table schemas afterward, run:
SELECT `database`, `name`, `engine_full`
FROM `system`.`tables`
WHERE `database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema');Task statuses:
| Status | Description |
|---|---|
| Running | Preparing environment and resources. |
| Initialization | Initializing the migration task. |
| Configuration Migration | Migrating cluster configuration. |
| Schema Migration | Migrating databases, MergeTree family tables, and distributed tables. |
| Data Migration | Incrementally migrating data from MergeTree family tables. |
| Other Schema Migration | Migrating materialized views and non-MergeTree table schemas. |
| Data Check | Verifying that data volume in the destination matches the self-managed cluster. |
| Post-configuration | Cleaning up the migration environment and re-enabling writes to the source cluster. |
| Completed | Migration is complete. |
| Canceled | Migration was canceled. |
Step 7: Stop writes and handle Kafka and RabbitMQ tables
Before switching business traffic to the destination cluster, stop all writes to the self-managed cluster and manually create Kafka and RabbitMQ tables on the destination.
On the self-managed cluster, identify the tables to process:
SELECT * FROM system.tables WHERE engine IN ('RabbitMQ', 'Kafka');Get the DDL for each table:
SHOW CREATE TABLE <target_table_name>;On the destination cluster, run the DDL statements to create the tables. See Connect to a ClickHouse cluster using DMS for connection instructions.
On the self-managed cluster, delete the Kafka and RabbitMQ tables.
When deleting a Kafka table, also delete all materialized views that reference it. Leaving them in place causes the migration task to fail.
Step 8: Complete the migration
After writes to the self-managed cluster are stopped, finalize the migration. This migrates remaining data, runs a data volume check, and migrates any outstanding database and table schemas.
Complete this within 5 days of creating the migration task. Longer-running tasks accumulate excessive metadata in the destination cluster, which slows migration. If the data volume check fails, cancel the task and create a new one.
Log in to the ApsaraDB for ClickHouse console.
On the Clusters page, select Clusters of Community-compatible Edition and click the destination cluster ID.
In the left navigation pane, click Data Migration and Synchronization > Migrate from ClickHouse.
In the Actions column for the task, click Complete Migration.
In the dialog box, click OK.
Step 9: Migrate data for non-MergeTree tables
The migration task copies table schemas for non-MergeTree tables (external tables, Log tables) but not their data. Migrate the data manually.
On the self-managed cluster, identify tables that need manual data migration:
SELECT `database` AS database_name, `name` AS table_name, `engine` FROM `system`.`tables` WHERE (`engine` NOT LIKE '%MergeTree%') AND (`engine` != 'Distributed') AND (`engine` != 'MaterializedView') AND (`engine` NOT IN ('Kafka', 'RabbitMQ')) AND (`database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema')) AND (`database` NOT IN ( SELECT `name` FROM `system`.`databases` WHERE `engine` IN ('MySQL', 'MaterializedMySQL', 'MaterializeMySQL', 'Lazy', 'PostgreSQL', 'MaterializedPostgreSQL', 'SQLite') ))On the destination cluster, migrate the data using the
remotefunction. See Migrate data using the remote function in the Manual migration section.
Other operations
When a migration task completes, its status changes to Completed, but the list may not refresh immediately. Refresh the page to see the latest status.
| Operation | What it does | Impact | Use when |
|---|---|---|---|
| Stop Migration | Stops data migration immediately. Skips the data volume check and migrates remaining schemas. | Destination cluster restarts. | Migrating a portion of data for testing without stopping writes to the self-managed cluster. |
| Cancel Migration | Forcibly cancels the task. Skips the data volume check and does not migrate remaining schemas. | Destination cluster restarts. Database and table schemas may be incomplete. Clear migrated data from the destination before retrying. | Migration is affecting the self-managed cluster and you need to stop immediately and re-enable writes. |
Stop migration
Stop migration:
Log in to the ApsaraDB for ClickHouse console.
On the Clusters page, select Clusters of Community-compatible Edition and click the destination cluster ID.
In the left navigation pane, click Data Migration and Synchronization > Migrate from ClickHouse.
In the Actions column, click Stop Migration and confirm.
Cancel migration
Cancel migration:
Log in to the ApsaraDB for ClickHouse console.
On the Clusters page, select Clusters of Community-compatible Edition and click the destination cluster ID.
In the left navigation pane, click Data Migration and Synchronization > Migrate from ClickHouse.
In the Actions column, click Cancel Migration and confirm.
Manual migration
Use manual migration when you need granular control: choosing specific databases or tables, migrating large cold or hot data volumes, or handling a cluster that cannot use the console migration tool.
Method 1: BACKUP and RESTORE commands
See Use the BACKUP and RESTORE commands to back up and restore data.
Method 2: INSERT INTO SELECT with the remote function
This two-step method migrates table schemas first, then data.
Step 1: Migrate table schemas (DDL)
Install clickhouse-client at the same version as the destination ApsaraDB for ClickHouse cluster. See clickhouse-client for download instructions.
List databases in the self-managed cluster:
clickhouse-client \ --host="<old_host>" --port="<old_port>" \ --user="<old_username>" --password="<old_password>" \ --query="SHOW databases" > database.listThe
systemdatabase does not need to be migrated.List tables in the self-managed cluster. Use either approach:
Tables with names starting with
.inner.are internal representations of materialized views and do not need to be migrated.clickhouse-client \ --host="<old_host>" --port="<old_port>" \ --user="<old_username>" --password="<old_password>" \ --query="SHOW tables from <database_name>" > table.listOr query all databases and tables at once:
SELECT DISTINCT database, name FROM system.tables WHERE database != 'system';Export the DDL for all tables in a database:
clickhouse-client \ --host="<old_host>" --port="<old_port>" \ --user="<old_username>" --password="<old_password>" \ --query="SELECT concat(create_table_query, ';') FROM system.tables WHERE database='<database_name>' FORMAT TabSeparatedRaw" > tables.sqlCreate the target database on the destination cluster, then import the DDL:
Parameter Description Address of the self-managed cluster. Port of the self-managed cluster. Account with DML read/write, settings, and DDL permissions. Password for the account. <new_host>Address of the destination ApsaraDB for ClickHouse cluster. <new_port>Port of the destination ApsaraDB for ClickHouse cluster. <new_username>Account with DML read/write, settings, and DDL permissions. <new_password>Password for the account. clickhouse-client \ --host="<new_host>" --port="<new_port>" \ --user="<new_username>" --password="<new_password>" \ -d '<database_name>' --multiquery < tables.sql
Step 2: Migrate data
Three options are available. Use the remote function (Option A) when possible, as it supports partition-level migration and reduces resource usage.
Option A: Migrate data using the remote function
Run the following on the destination cluster:
(Optional) Reduce network traffic by enabling ZSTD compression:
SET network_compression_method = 'ZSTD';To check the current setting:
SELECT * FROM system.settings WHERE name = 'network_compression_method';Migrate data table by table, optionally filtering by partition:
For version 20.8, try
remoteRawfirst. If migration fails, request a minor version upgrade. ``sql INSERT INTO <new_database>.<new_table> SELECT * FROM remoteRaw('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0;``ImportantAlways use the VPC internal endpoint, not the public endpoint.
Parameters:
Parameter Description <new_database>Target database name on the destination cluster. <new_table>Target table name on the destination cluster. Source endpoint (see formats below). Source database name. Source table name. <username>Source cluster account. <password>Source cluster password. max_execution_timeMaximum query run time. 0= no limit.max_bytes_to_readMaximum bytes read from source. 0= no limit.log_query_threadsLog thread info for queries. 0= disabled.max_result_rowsMaximum rows in result. 0= no limit._partition_idPartition ID to filter. Filtering by partition reduces resource usage (recommended). Endpoint formats for `<old_endpoint>`:
Self-managed ClickHouse
ApsaraDB for ClickHouse
Use the VPC endpoint of the source instance, not the public endpoint.
ImportantThe ports 3306 and 9000 are fixed values.
-
Community-compatible Edition instance:
-
Endpoint format:
VPC internal address:3306 -
Example:
cc-2zeqhh5v7y6q*****.clickhouse.ads.aliyuncs.com:3306
-
-
Enterprise Edition instance:
-
Endpoint format:
VPC internal address:9000 -
Example:
cc-bp1anv7jo84ta*****clickhouse.clickhouseserver.rds.aliyuncs.com:9000
-
Source type Format Example Self-managed ClickHouse IP:TCP_port192.168.0.5:9000ApsaraDB for ClickHouse Community-Compatible Edition VPC_internal_address:3306cc-2zeqhh5v7y6q*****.clickhouse.ads.aliyuncs.com:3306ApsaraDB for ClickHouse Enterprise VPC_internal_address:9000cc-bp1anv7jo84ta*****clickhouse.clickhouseserver.rds.aliyuncs.com:9000INSERT INTO <new_database>.<new_table> SELECT * FROM remote('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0;To look up partition IDs and part counts:
SELECT partition_id, count(*) AS part_count FROM clusterAllReplicas(default, system, parts) WHERE `database` = '<old_database>' AND `table` = '<old_table>' GROUP BY partition_id;-
File export and import
Option B: Export and import via CSV files
Export from the self-managed cluster:
clickhouse-client \
--host="<old_host>" --port="<old_port>" \
--user="<old_username>" --password="<old_password>" \
--query="SELECT * FROM <database_name>.<table_name> FORMAT CSV" > table.csvImport to the destination cluster:
clickhouse-client \
--host="<new_host>" --port="<new_port>" \
--user="<new_username>" --password="<new_password>" \
--query="INSERT INTO <database_name>.<table_name> FORMAT CSV" < table.csvOption C: Stream via Linux pipe
Pipe export and import in a single command without intermediate files:
clickhouse-client \
--host="<old_host>" --port="<old_port>" \
--user="<username>" --password="<password>" \
--query="SELECT * FROM <database_name>.<table_name> FORMAT CSV" | \
clickhouse-client \
--host="<new_host>" --port="<new_port>" \
--user="<username>" --password="<password>" \
--query="INSERT INTO <database_name>.<table_name> FORMAT CSV"Pre-check error messages and solutions
| Error message | Cause | Solution |
|---|---|---|
| Missing unique distributed table or sharding_key not set. | A local table in the self-managed cluster has no corresponding distributed table. | Create a distributed table for the local table before migrating. |
| The corresponding distributed table is not unique. | A local table has multiple distributed tables. | Delete the extra distributed tables, keeping only one. |
| MergeTree table on multiple replica cluster. | The self-managed cluster is a multi-replica cluster with non-replicated tables. | See Non-replicated tables in multi-replica clusters in the FAQ section. |
| Data reserved table on destination cluster. | The destination already has data in the corresponding table. | Delete the corresponding table from the destination cluster. |
| Columns of distributed table and local table conflict. | Column definitions in the distributed table and local table do not match. | Rebuild the distributed table to match the local table. |
| Storage is not enough. | Insufficient storage space on the destination cluster. | Upgrade the destination cluster disk. Destination total space must be ≥ 1.2× the self-managed cluster's used space. See Upgrade/Downgrade and scale-out/scale-in of community-compatible clusters. |
| Missing system table. | A required system table is missing in the self-managed cluster. | Update config.xml to enable the required system tables. See Step 1: Enable system tables. |
| The table is incomplete across different nodes. | A table is missing on some shards. | Create the table on all shards. For materialized view inner tables, rename the inner table and rebuild the materialized view. See The inner table of a materialized view is inconsistent across shards. |
Calculate post-migration merge time
After migration, the destination cluster runs high-frequency merges. This increases I/O usage and request latency. If your workload is latency-sensitive, consider upgrading the instance type or ESSD performance level to shorten this period. See Vertical scaling, scale-out, and scale-in of community-compatible clusters.
This formula applies to both single-replica and master-replica clusters:
Total merge time = MAX(hot data merge time, cold data merge time)
Hot data merge time =
hot data per node × 2 ÷ MIN(instance type bandwidth, disk bandwidth × n)Cold data merge time =
(cold data ÷ nodes) ÷ MIN(instance type bandwidth, OSS read bandwidth) + (cold data ÷ nodes) ÷ MIN(instance type bandwidth, OSS write bandwidth)
How to get each value:
| Value | How to obtain |
|---|---|
| Hot data per node | Disk Usage - Single-Node Statistics in View cluster monitoring information. |
| Cold data | Cold storage usage in View cluster monitoring information. |
| Number of nodes | SELECT count() FROM system.clusters WHERE cluster = 'default' AND replica_num = 1; |
| n (disks per node) | SELECT count() FROM system.disks WHERE type = 'local'; |
| Disk bandwidth | Maximum throughput per disk (MB/s) in the ESSD performance level table. |
| OSS read bandwidth | Total Intranet and Internet Download Bandwidth in the OSS bandwidth table. |
| OSS write bandwidth | Total Intranet and Internet Upload Bandwidth in the OSS bandwidth table. |
Instance type bandwidth reference (minimum values):
| Specification | Bandwidth (MB/s) |
|---|---|
| Standard 8-core 32 GB | 250 |
| Standard 16-core 64 GB | 375 |
| Standard 24-core 96 GB | 500 |
| Standard 32-core 128 GB | 625 |
| Standard 64-core 256 GB | 1,250 |
| Standard 80-core 384 GB | 2,000 |
| Standard 104-core 384 GB | 2,000 |
Actual bandwidth varies by machine type. These values are minimum references.
FAQ
Too many partitions for single INSERT block
Error: Too many partitions for single INSERT block (more than 100)
Each INSERT creates data parts across partitions. When a single INSERT writes to more than max_partitions_per_insert_block partitions (default: 100), ClickHouse rejects the operation to prevent performance degradation during merges and queries.
Fix this by reducing the number of partitions per INSERT, or increase the limit if unavoidable:
SET GLOBAL ON CLUSTER DEFAULT max_partitions_per_insert_block = <value>;Keep this value as low as possible. The default of 100 is the community recommendation. Restore the default after the batch import completes.
Connection from destination to self-managed cluster fails
The self-managed cluster likely has a firewall or whitelist configured. Add the IPv4 CIDR Block of the destination cluster's vSwitch ID to the self-managed cluster's whitelist. For instructions on finding the CIDR block, see the Prerequisites section.
Non-replicated tables in multi-replica clusters
Why non-replicated tables are blocked: In multi-replica clusters, the migration tool picks one replica as the data source. If non-replicated MergeTree tables exist, each replica may hold different data — migrating from a single replica causes data loss.
For example: if replica r0 holds rows 1, 2, and 3, and replica r1 holds rows 4 and 5, migrating from r0 loses rows 4 and 5.
