ApsaraMQ for RocketMQ distributes messages across multiple queues to prevent hot spots and performance bottlenecks. The message type determines which load balancing policy applies: unordered messages use round robin, and ordered messages use MessageGroupHash.
Understanding these policies helps you:
Plan disaster recovery: Know how messages are rerouted when a node fails.
Guarantee message ordering: Understand how ApsaraMQ for RocketMQ maintains strict FIFO delivery for ordered messages.
Scale throughput: Design effective traffic distribution and queue scaling strategies.
Policy comparison
| Policy | Message type | Algorithm | Ordering guarantee | Version support |
|---|---|---|---|---|
| Round robin | Unordered (normal, scheduled, transactional) | Cyclic distribution across all queues | None | 5.x, 4.x, 3.x |
| MessageGroupHash | Ordered | SipHash-based hash on message group | FIFO within the same message group | 5.x only |
Round robin
Round robin is the default and only load balancing policy for unordered messages, including normal, scheduled, and transactional messages.
How it works
The producer cycles through all queues in a topic, distributing one message per queue before moving to the next. This keeps the load evenly balanced across queues and maximizes topic throughput.
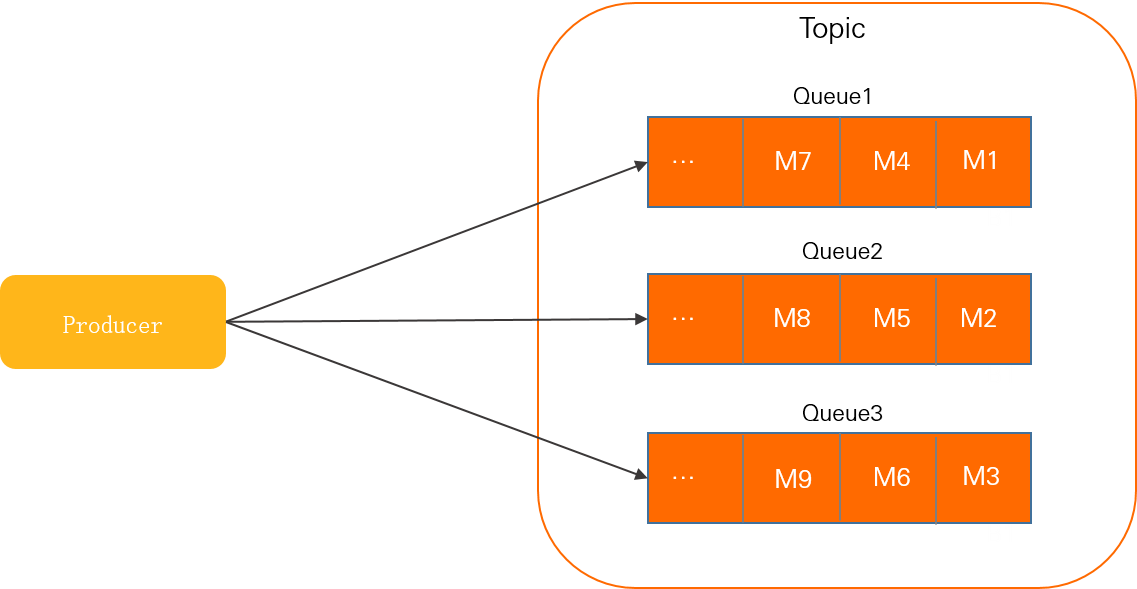
In this diagram, Queue 1, Queue 2, and Queue 3 are queues in the topic. The producer sends M1 to Queue 1, M2 to Queue 2, and M3 to Queue 3, then starts the cycle again for the next messages.
Fault isolation
If a message fails to send, ApsaraMQ for RocketMQ evaluates the failure cause and may temporarily skip the affected node when selecting the next destination queue. This automatic fault isolation reroutes later messages to healthy queues without manual intervention.
Code example
Round robin is enabled by default for unordered messages. No additional configuration is required.
// Round robin is the default policy for normal messages.
// The SDK automatically distributes messages across all queues.
MessageBuilder messageBuilder = null;
for (int i = 0; i < 10; i++) {
Message message = messageBuilder.setTopic("normalTopic")
// Set the message index key for accurate message lookup.
.setKeys("messageKey")
// Set the message tag for consumer-side filtering.
.setTag("messageTag")
// Set the message body.
.setBody("messageBody".getBytes())
.build();
try {
SendReceipt sendReceipt = producer.send(message);
System.out.println(sendReceipt.getMessageId());
} catch (ClientException e) {
e.printStackTrace();
}
}MessageGroupHash
MessageGroupHash is the default and only load balancing policy for ordered messages. It guarantees FIFO (first-in, first-out) delivery within each message group.
How it works
The producer hashes each message's group identifier using the SipHash algorithm and maps the result to a specific queue. All messages in the same message group are routed to the same queue and stored in send order.
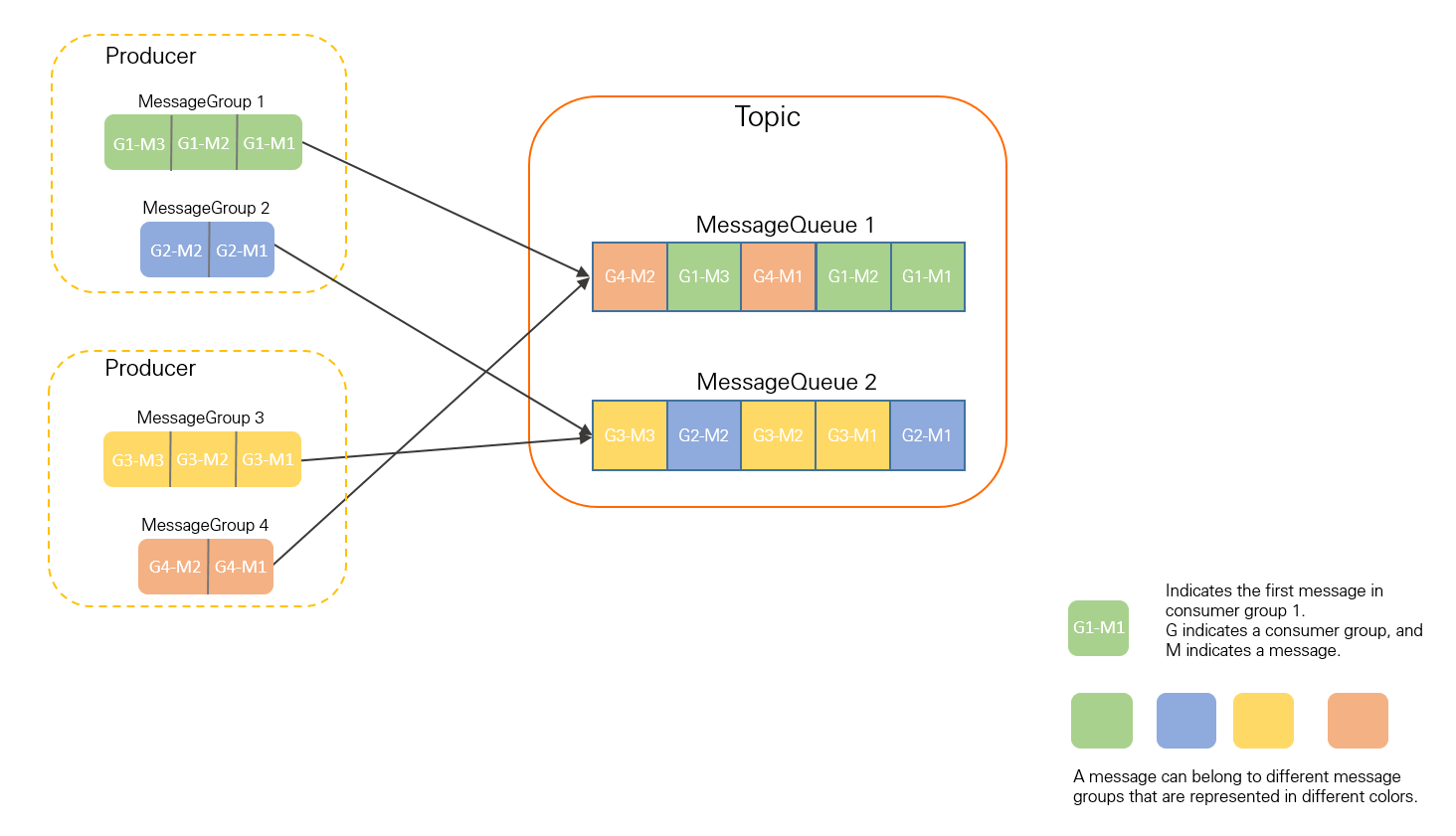
In this diagram, G1-M1, G1-M2, and G1-M3 all belong to MessageGroup 1. The SipHash algorithm maps them to MessageQueue 1, where they are stored in the order they were sent.
Uneven distribution risk
Because MessageGroupHash maps each group to a fixed queue, uneven message volumes across groups can concentrate load on a small number of queues. If most messages belong to a few groups, those queues become hot spots, increasing storage pressure and limiting the ability to scale.
To mitigate this, design message groups at a fine-grained level. For example, in an e-commerce system, use order IDs or user IDs as message group keys. This distributes messages across many groups while preserving per-order or per-user ordering.
Code example
MessageGroupHash is enabled by default for ordered messages. Specify the message group with setMessageGroup().
// MessageGroupHash is the default policy for ordered messages.
// Messages in the same group go to the same queue, in send order.
for (int i = 0; i < 10; i++) {
Message message = messageBuilder.setTopic("fifoTopic")
// Set the message index key for accurate message lookup.
.setKeys("messageKey")
// Set the message tag for consumer-side filtering.
.setTag("messageTag")
// Set the message group. Messages with the same group
// are routed to the same queue via the SipHash algorithm.
.setMessageGroup("fifoGroupA")
// Set the message body.
.setBody("messageBody".getBytes())
.build();
try {
SendReceipt sendReceipt = producer.send(message);
System.out.println(sendReceipt.getMessageId());
} catch (ClientException e) {
e.printStackTrace();
}
}Version compatibility
| Policy | 5.x | 4.x | 3.x |
|---|---|---|---|
| Round robin | Supported | Supported | Supported |
| MessageGroupHash | Supported | Not supported | Not supported |
If you upgrade from server version 4.x or 3.x to 5.x, the ordered message delivery mechanism changes from the legacy approach to MessageGroupHash. To prevent message reordering during the transition, consume all existing messages in the topic before switching to version 5.x.
Round robin is supported across all server versions and requires no migration steps.
Best practices
Distribute messages across multiple groups
In MessageGroupHash mode, all messages in the same group go to the same queue. If your business logic concentrates messages into a few groups, those queues become overloaded.
Choose granular group keys that spread messages evenly. For example:
| Scenario | Recommended group key | Benefit |
|---|---|---|
| Order processing | Order ID | One queue per order; orders are distributed across queues |
| User activity tracking | User ID | Per-user ordering with even cross-user distribution |
| Device telemetry | Device ID | Per-device ordering without hot spots |
Use more than one queue per topic
Regardless of the load balancing policy, a topic with a single queue cannot distribute load. All messages go to that one queue, creating a performance bottleneck and eliminating disaster recovery capability.
Always configure multiple queues per topic to enable load distribution and failover.