This topic describes how to create an Object Storage Service (OSS) sink connector to synchronize data from a topic in ApsaraMQ for Kafka to an object in OSS.
Prerequisites
For information about the prerequisites, see Prerequisites.
Step 1: Create OSS resources
Create a bucket in the OSS console. For more information, see Create buckets.
In this topic, a bucket named oss-sink-connector-bucket is created.
Step 2: Create and start an OSS sink connector
Log on to the ApsaraMQ for Kafka console. In the Resource Distribution section of the Overview page, select the region where the ApsaraMQ for Kafka instance that you want to manage resides.
- In the left-side navigation pane, choose .
- On the Message Outflow page, click Create Task.
In the Basic Information step, specify a task name in the Task Name field and select OSS from the Message Outflow Task Type drop-down list.
In the Resource Settings step, configure the parameters. The following tables describe the parameters.
Table 1. Parameters configured for ApsaraMQ for Kafka
Parameter
Description
Example
Region
Select the region where the Message Queue for Apache Kafka instance resides.
China (Hangzhou)
Message Queue for Apache Kafka Instance
The ID of the Message Queue for Apache Kafka instance.
alikafka_post-cn-9hdsbdhd****
Topic
The source topic in the Message Queue for Apache Kafka instance.
guide-sink-topic
Group ID
The ID of the group in the Message Queue for Apache Kafka instance.
Quickly Create: The system automatically creates a group whose ID is in the GID_EVENTBRIDGE_xxx format.
Use Existing Group: Select the ID of an existing group that is not being used. If you select an existing group that is being used, the publishing and subscription of existing messages are affected.
Use Existing Group
Concurrency Quota (Consumers)
The number of threads that concurrently consume data in the topic. The following items describe the mapping between threads and partitions in a topic:
If the number of partitions in a topic is equal to the number of threads that concurrently consume data in the topic, one thread consumes data in one partition. We recommend that you use this configuration.
If the number of partitions in a topic is greater than the number of threads that concurrently consume data in the topic, the threads evenly consume data in all partitions.
If the number of partitions in a topic is smaller than the number of threads that concurrently consume data in the topic, one thread consumes data in one partition. The additional threads do not consume data.
2
Consumer Offset
Latest Offset: Consume messages from the most recent offset.
Earliest Offset: Consume messages from the earliest offset.
Latest Offset
Network Configuration
If cross-border data transmission is required, select Internet. In other cases, select Default Network.
Default Network
Table 1. Parameters configured for OSS
Parameter
Description
Example
OSS Bucket
The OSS bucket that you created.
oss-sink-connector-bucket
Storage Path
No Subdirectory Required: The data storage path is in the {Kafka Instance ID}/{Topic Name} format.
Time-based subdirectories:
YYYY/MM/dd/HH: The generated subdirectories are in the {Kafka Instance ID}/{Topic Name}/YYYY/MM/dd/HH format.
YYYY/MM/dd/HH: The generated subdirectories are in the {Kafka Instance ID}/{Topic Name}/YYYY/MM/dd format.
YYYYMMddHH: The generated subdirectories are in the {Kafka Instance ID}/{Topic Name}/YYYYMMddHH format.
YYYYMMdd: The generated subdirectories are in the {Kafka Instance ID}/{Topic Name}/YYYYMMdd format.
NoteIn the preceding values, YYYY specifies year, MM specifies month, dd specifies day, and HH specifies hour.
alikafka_post-cn-9dhsaassdd****/guide-oss-sink-topic/YYYY/MM/dd/HH
Advanced Settings
If the condition that is specified by the Batch Aggregation Object Size parameter or the Batch Aggregation Time Window parameter is met by the messages in the backlog, new messages are written to new objects.
None
Batch Aggregation Object Size
Specify the size of the objects to be aggregated. Valid values: 1 to 128. Unit: MiB.
5
Batch Aggregation Time Window
Specify the time window for aggregation. Unit: minutes.
1
After you perform the preceding operations, go to the Message Outflow page, find the OSS sink connector that you created, and then click Start in the Actions column. If the status in the Status column changes from Starting to Running, the connector is created.
Step 3: Test the OSS sink connector
On the Message Outflow page, find the OSS sink connector that you created and click the source topic in the Event Source column.
- On the Topic Details page, click Send Message.
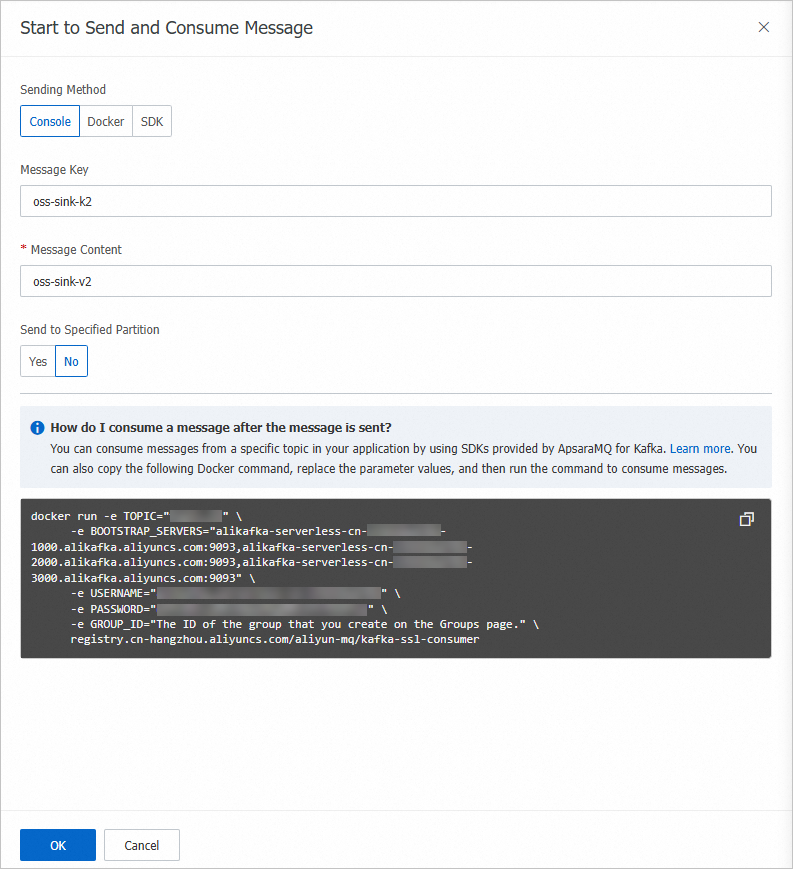
In the Start to Send and Consume Message panel, configure the parameters based on the following figure and click OK.
On the Message Outflow page, find the OSS sink connector that you created and click the destination bucket in the Event Target column.
In the left-side navigation pane of the bucket details page, choose . On the page that appears, enter the deepest path of the bucket.
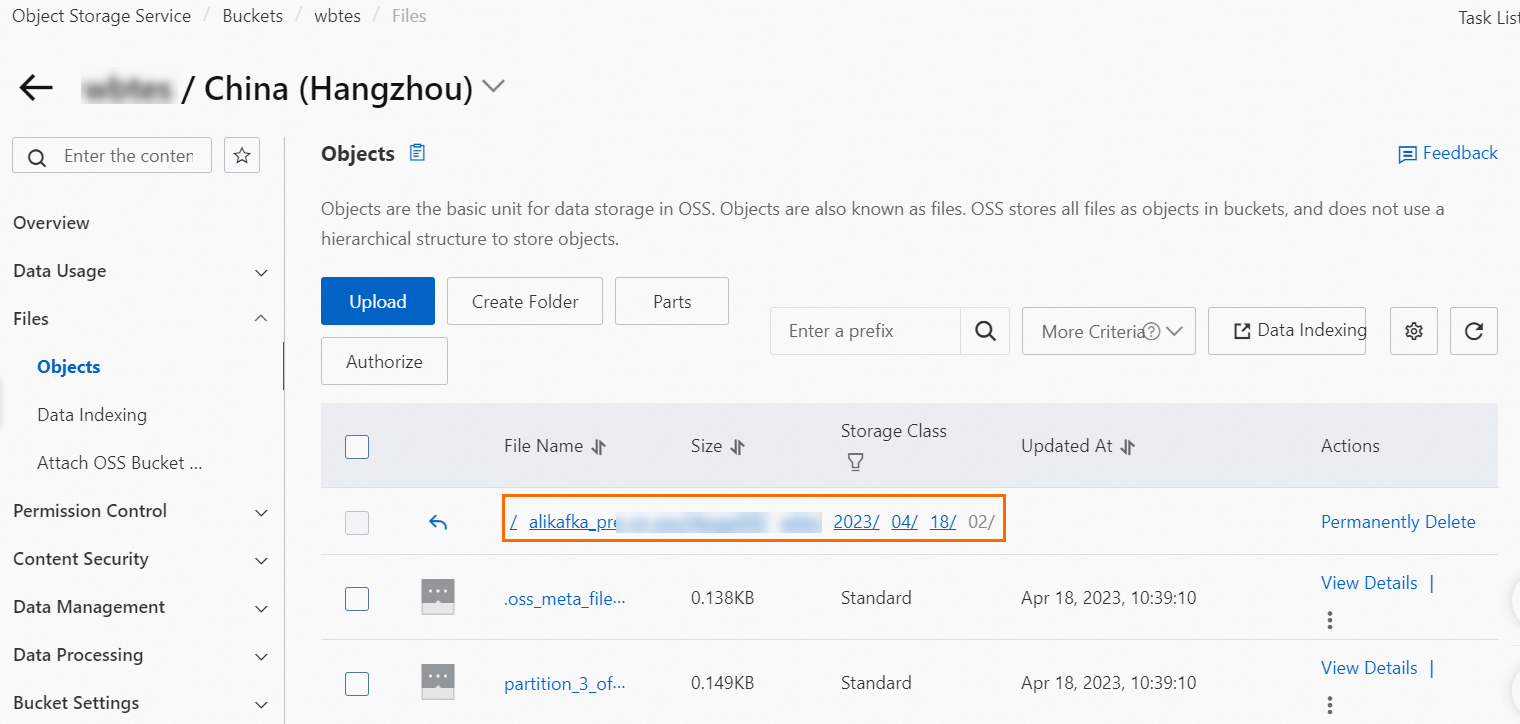
You can find the following types of objects in this path:
System metaobjects: The names of system metaobjects are in the oss_meta_file_partition_{partitionID} format. The number of the objects is the same as the number of partitions in the upstream topic. System metaobjects are used to record batch information. You can ignore system metaobjects.
Data objects: The names of data objects are in the partition_{partitionID}_offset_{offset}_{an 8-bit random string} format. If multiple messages of a partition are aggregated in an object, the value of {offset} in the object name is the minimum offset among the messages.
Find the object that you want to manage and choose
 > Download in the Actions column.
> Download in the Actions column. Open the downloaded object to view the details of the messages.

The preceding figure provides an example of message details. Multiple messages are separated with line feeds.