ApsaraMQ for Kafka serves as the streaming data backbone for real-time analytics, log pipelines, stream extract, transform, and load (ETL), and cross-system data distribution.
When to use ApsaraMQ for Kafka
| Scenario | Problem it solves |
|---|---|
| Website activity tracking | Capture user actions (sign-ins, purchases, payments) in real time and route them to analytics or data warehouse systems |
| Log aggregation | Collect logs from distributed hosts and applications into a single pipeline for real-time and offline analysis |
| Stream ETL | Process high-volume data in flight instead of landing it in a database first, then analyze or redistribute the results |
| Data routing hub | Fan out a single dataset to multiple downstream systems (search, OLAP, time-series databases) through one pipeline |
Website activity tracking
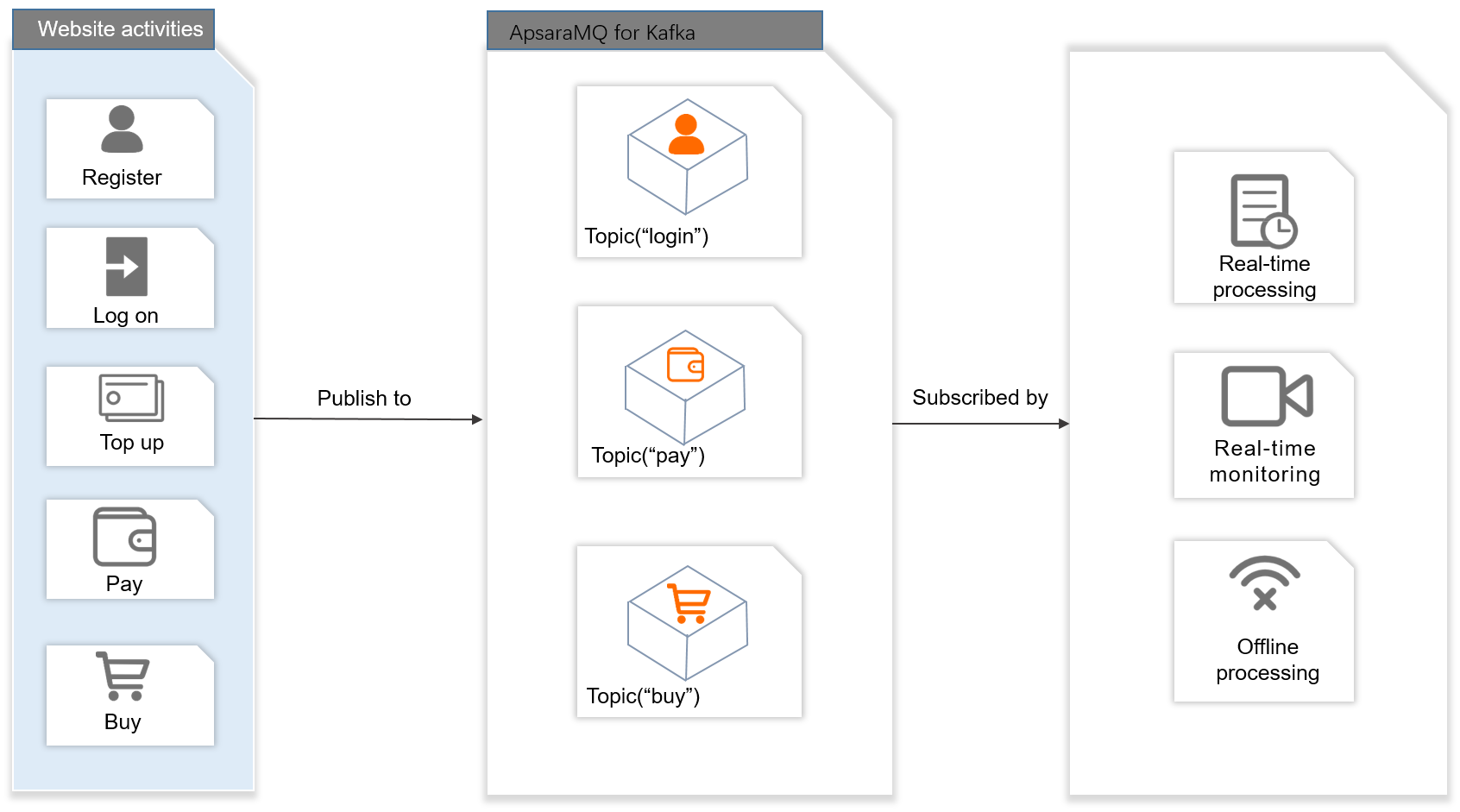
ApsaraMQ for Kafka provides a publish-subscribe pipeline that captures user behavior data as it happens and routes it to analytics systems.
Data flow
Publish user action events (sign-in, logon, top-up, payment, purchase) to different topics based on business data types.
Subscribers consume the message streams in real time for live dashboards and monitoring.
Load the same streams into offline data warehouse systems such as Hadoop and MaxCompute for batch analysis.
Advantages for this scenario
High throughput -- Handles the volume of user action data that production websites generate at peak traffic.
Auto scaling -- During promotions or flash sales, brokers can be scaled out based on your requirements to absorb traffic spikes.
Big data integration -- Connects to real-time engines (Storm, Spark) and offline data warehouse systems (Hadoop, MaxCompute).
Log aggregation
Many platforms, such as Taobao and Tmall, generate large volumes of logs every day. In most cases, these logs are streaming data, such as page views and queries. Compared to log-centric tools like Scribe and Flume, ApsaraMQ for Kafka delivers higher performance, stronger data persistence, and lower end-to-end latency, making it a natural fit for centralized log collection.
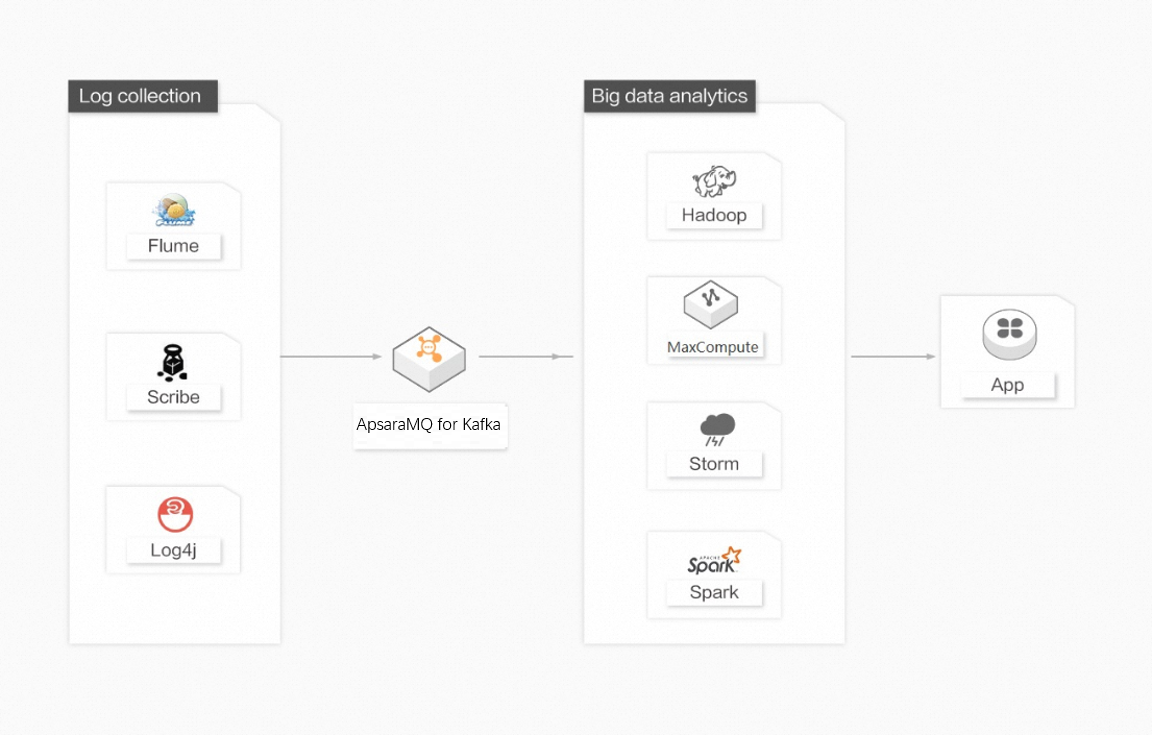
Data flow
Abstract logs from multiple hosts and applications into unified message streams. In ApsaraMQ for Kafka, file details are ignored.
Send those streams asynchronously to an ApsaraMQ for Kafka cluster. Clients can batch and compress messages to keep producer overhead low.
Consumers read the streams and route them to offline warehouse systems (Hadoop, MaxCompute) for batch analytics or to real-time engines (Storm, Spark) for live analysis.
Advantages for this scenario
System decoupling -- Acts as a buffer between application systems and analytics systems, decoupling the two types of systems.
Horizontal scalability -- Add nodes to rapidly scale out as log volume grows.
Online and offline analysis -- Feeds both real-time engines and offline systems like Hadoop from the same pipeline.
Stream ETL
In domains like stock market analysis, weather monitoring, and user behavior analytics, data arrives continuously and in high volume. Storing everything in a database before processing is impractical, and traditional ETL architectures cannot keep up. ApsaraMQ for Kafka, paired with stream processing engines (Storm, Samza, Spark), processes data in flight instead.
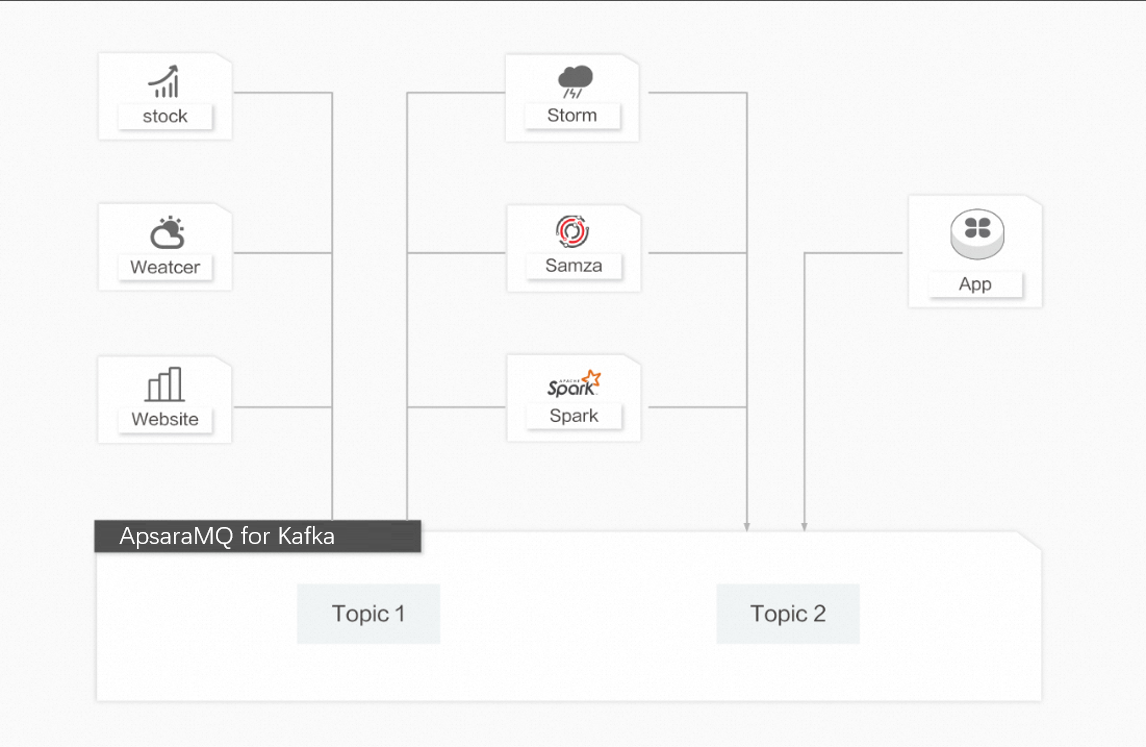
Data flow
Ingest raw data into ApsaraMQ for Kafka topics as it is generated.
A stream processing engine reads from the topics, transforms the data in real time, and runs analytics based on your business logic.
Save processed results to downstream storage or distribute them to other components.
Advantages for this scenario
In-flight processing -- Captures and transforms data during transit rather than after storage.
High scalability -- Scales horizontally to handle real-time data volumes that traditional ETL cannot.
Broad engine support -- Integrates with open-source engines (Storm, Samza, Spark) and Alibaba Cloud services (E-MapReduce, Blink, Realtime Compute).
Data routing hub
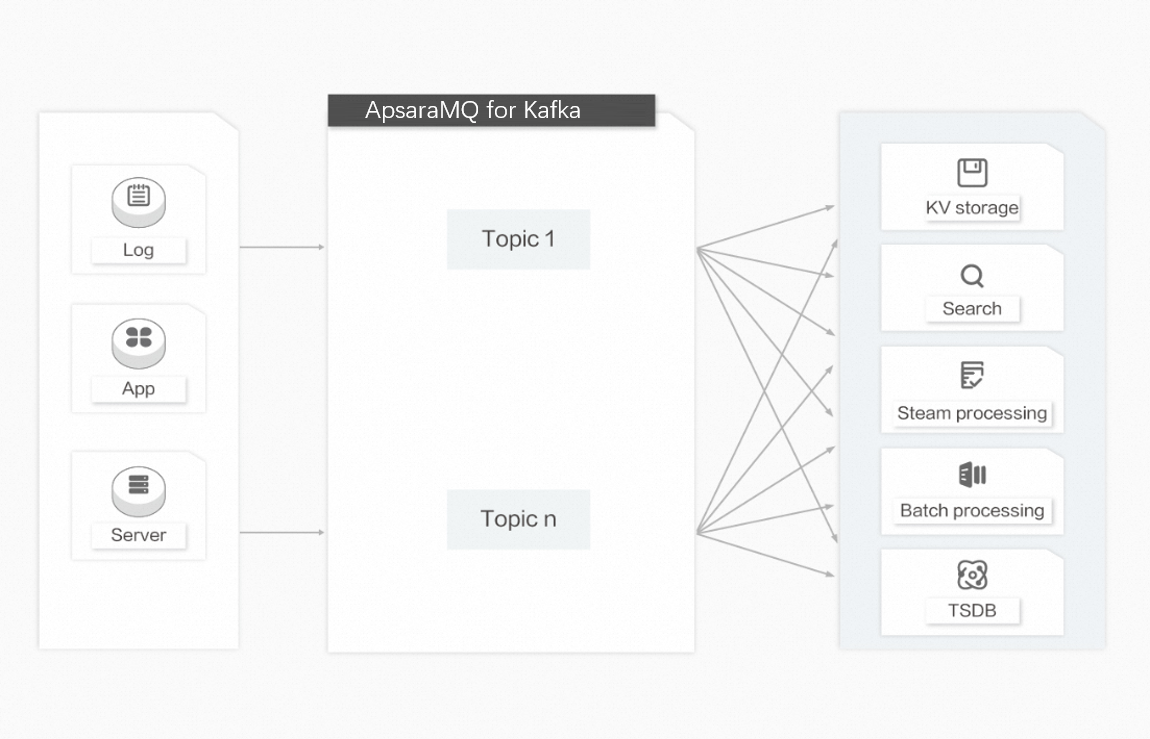
Over the past 10 years, modern architectures have come to rely on purpose-built systems for specific workloads: HBase for key-value storage, Elasticsearch for search, Storm/Spark/Samza for stream processing, and OpenTSDB for time-series data. Each system is designed for a single goal, and the simplicity of these systems makes it easier and more cost-efficient to build distributed systems on commercial hardware. However, the same dataset often needs to reach multiple systems. For example, application logs may be used for offline analysis while also requiring the ability to search for a single log. Building a separate ingestion pipeline for each system is impractical.
ApsaraMQ for Kafka acts as a centralized data routing hub: ingest data once and fan it out to every downstream system that needs it.
Advantages for this scenario
High-capacity storage -- Stores large volumes of data on commercial hardware and supports horizontally scalable distributed architectures.
One-to-many consumption -- The publish-subscribe model lets multiple consumers independently read the same dataset without interference.
Real-time and batch processing -- Supports local data persistence and page cache, delivering messages for both real-time and batch workloads simultaneously with no performance penalty.