This topic describes how to use DataWorks to schedule the script tasks of AnalyticDB for PostgreSQL. DataWorks allows you to develop, schedule, and maintain the tasks of AnalyticDB for PostgreSQL and manage dependencies among tasks. It enhances the extract, transform, load (ETL) capabilities of AnalyticDB for PostgreSQL.
Prerequisites
Test data is obtained from the TPCH test data set.
Data is imported to AnalyticDB for PostgreSQL. For more information, see Introduction to data migration and synchronization solutions.
Overview
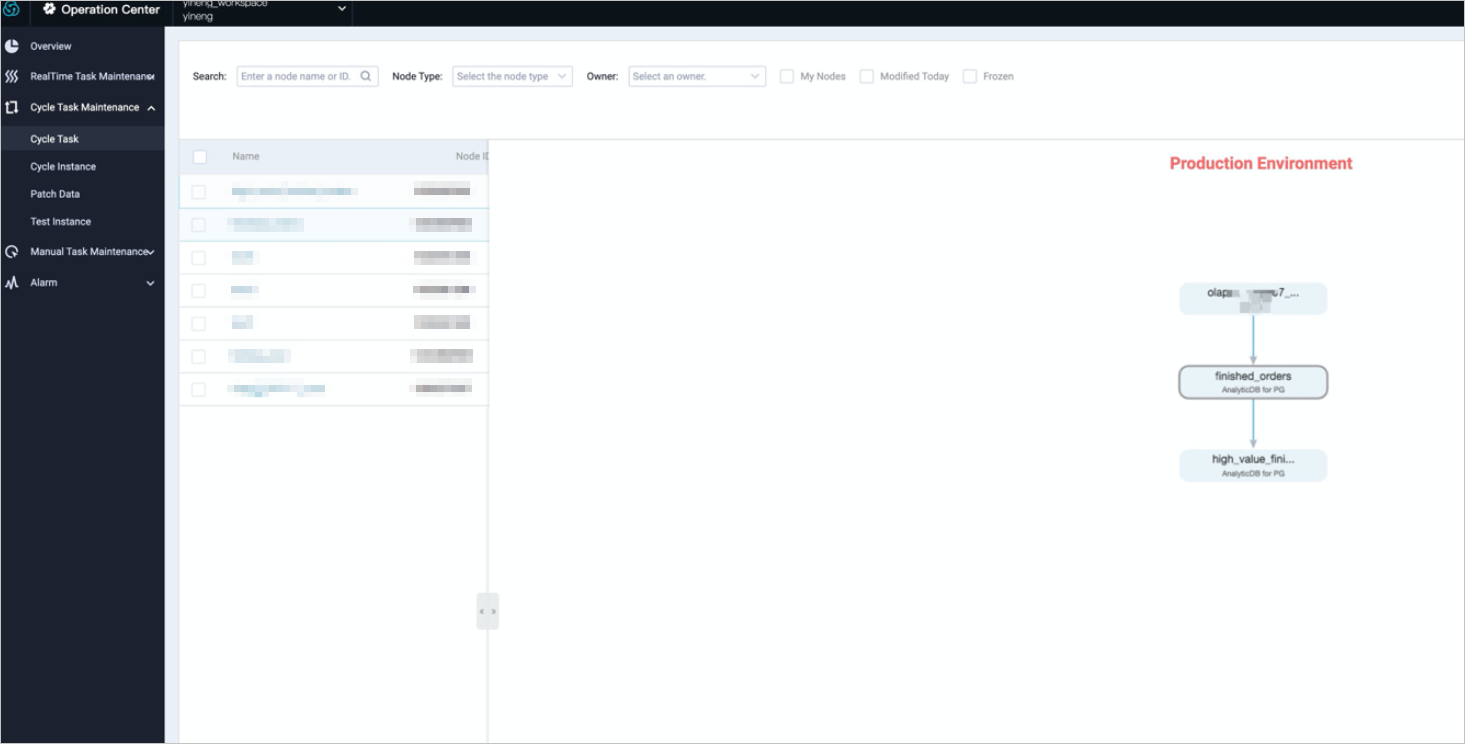
Dependencies among tasks are important for task scheduling. For example, the relationships between two AnalyticDB for PostgreSQL tasks created in DataWorks and AnalyticDB for PostgreSQL tables are shown in the following figure.
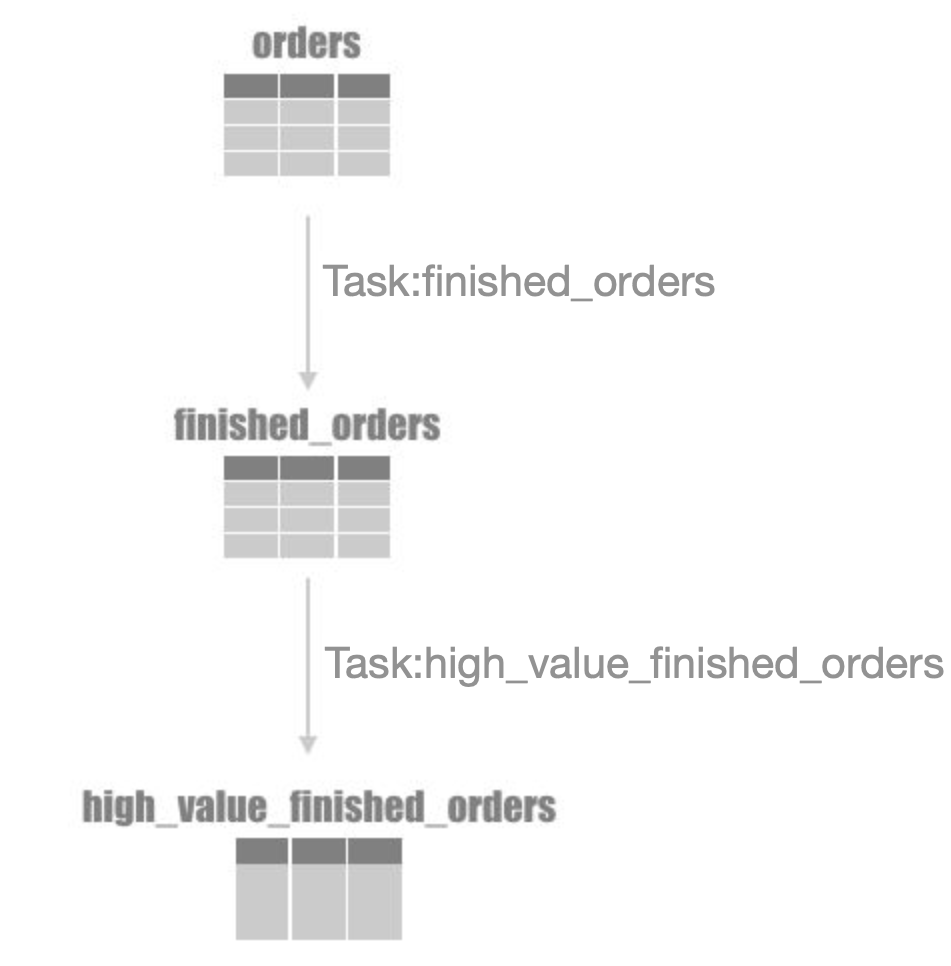
Task: finished_orders
AnalyticDB for PostgreSQL uses
o_orderstatus = 'F'to filter finished orders in the orders table and then writes the orders into the finished_orders table.Task: high_value_finished_orders
AnalyticDB for PostgreSQL uses
o_totalprice > 10000to filter orders whose total price is greater than 10,000 from the finished_orders table and writes the orders into the high_value_finished_orders table.
Create tasks
For more information, visit AnalyticDB for PostgreSQL node.
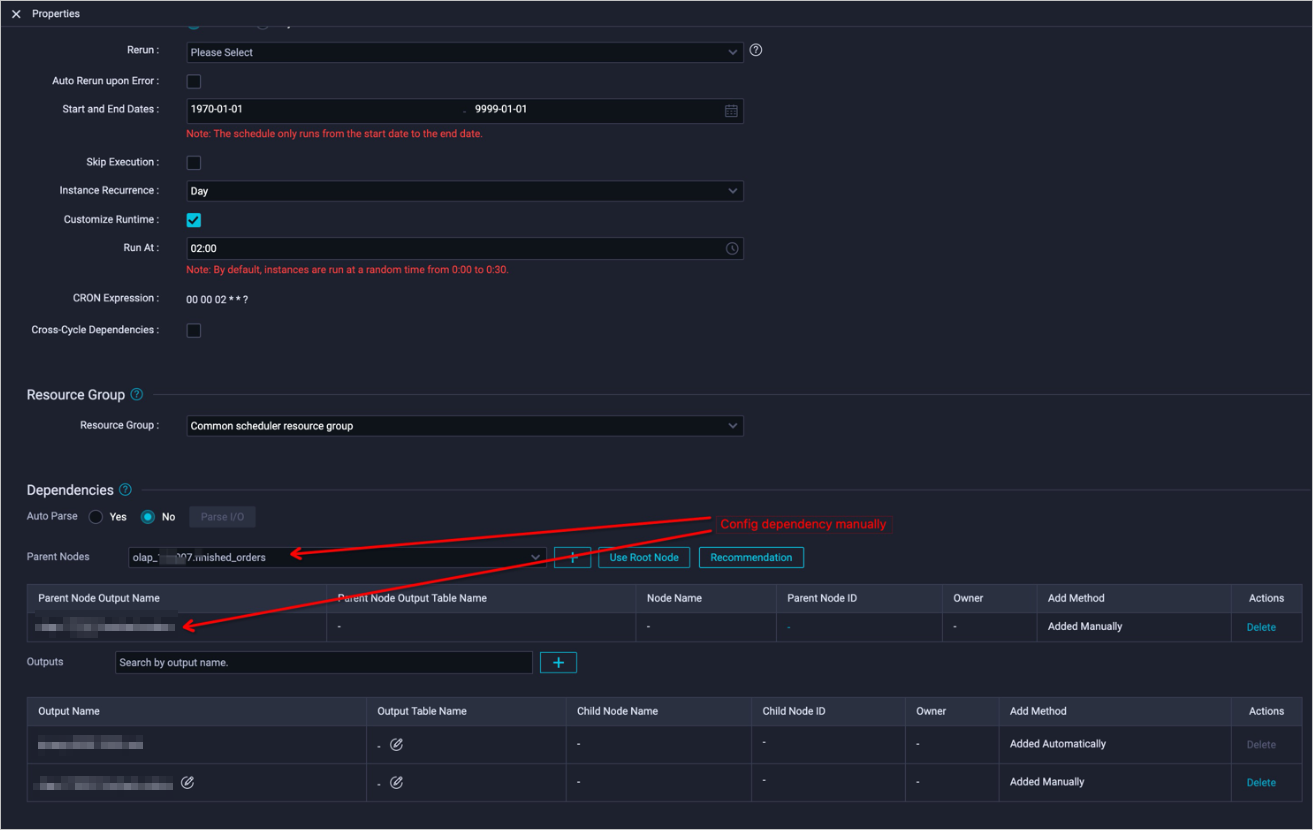
Configure dependencies among tasks
The core of task scheduling is that multiple tasks run at a specific time based on specified dependencies.
For example, the finished_orders task runs at 02:00 every day, and the high_value_finished_orders task runs after the finished_orders task succeeds. To configure a dependency between the two tasks, follow these steps:
Set the runtime of the
finished_orderstask.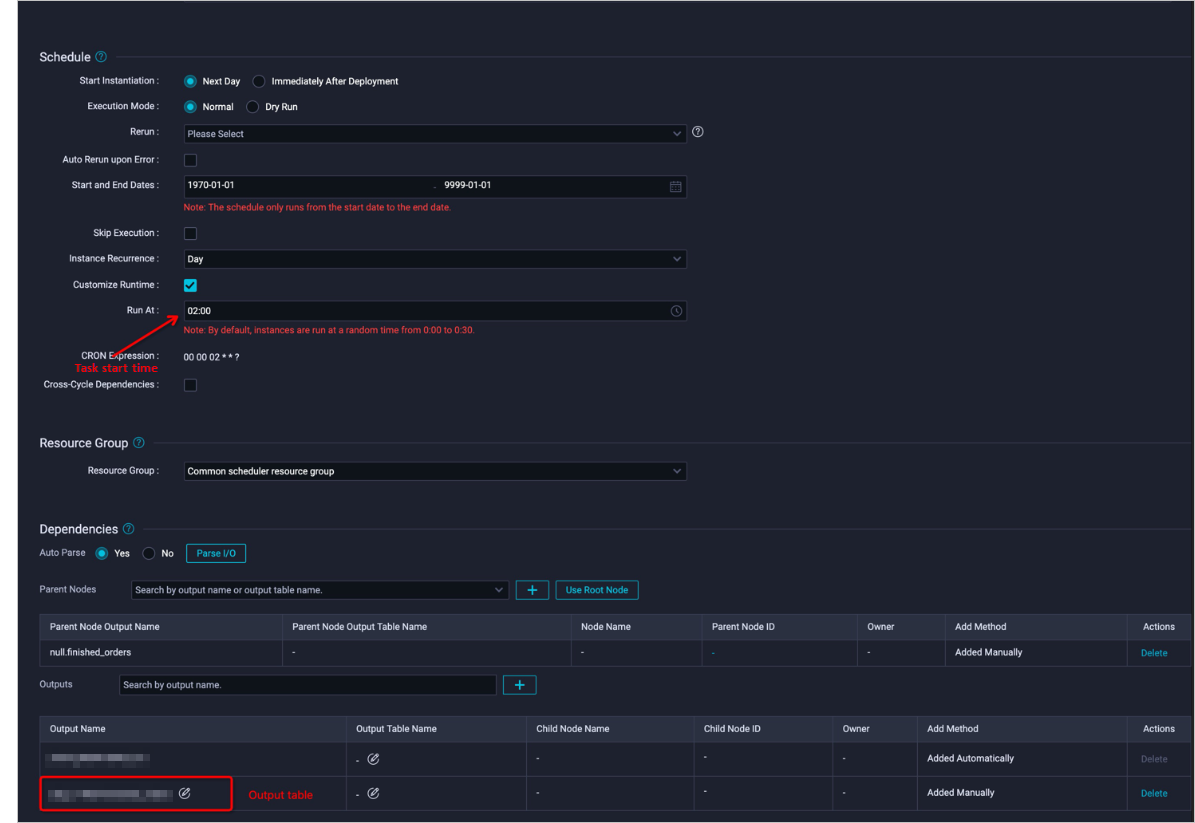
Configure a dependency for the
high_value_finished_orderstask.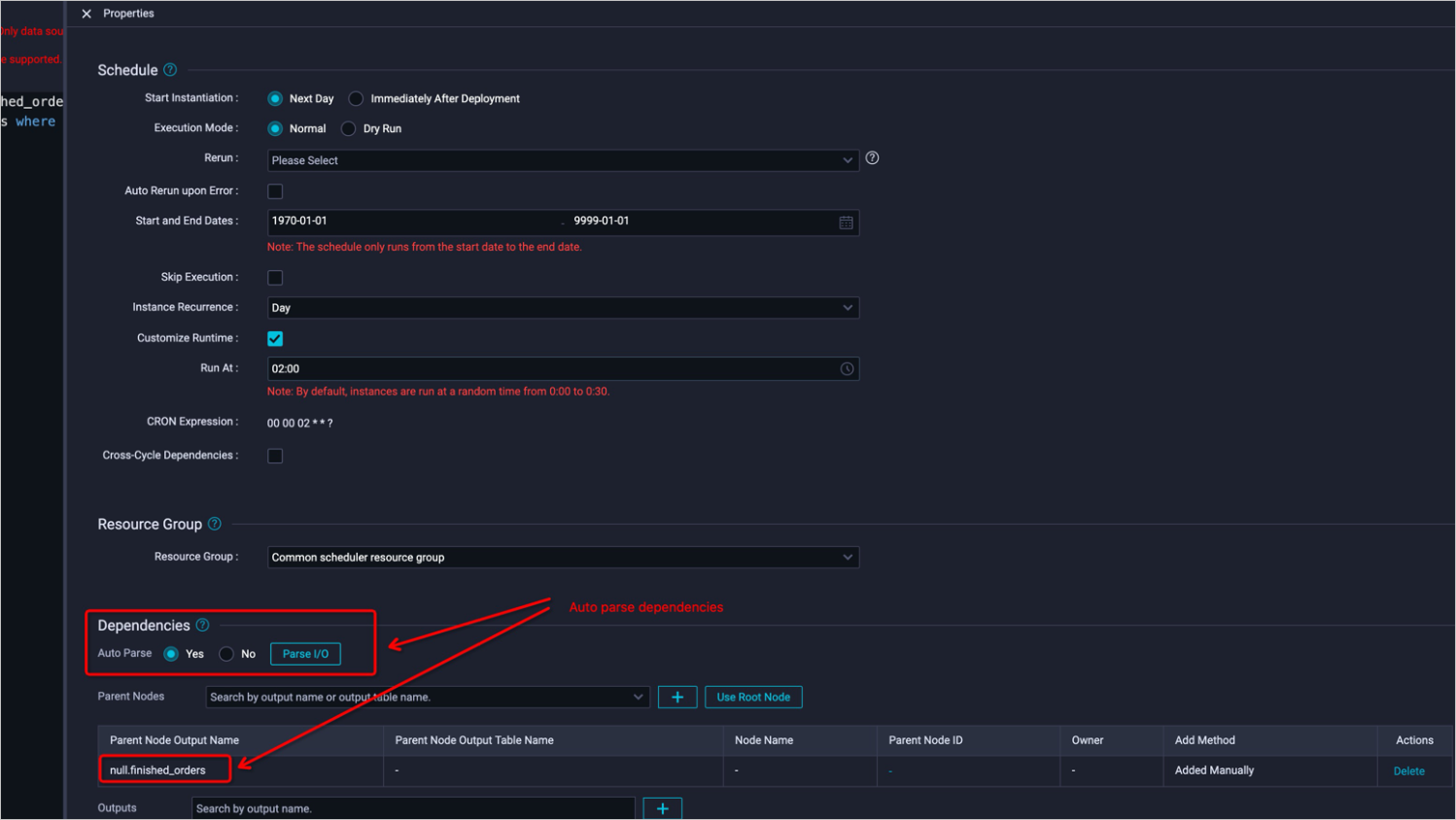
If a task dependency is not parsed automatically, you must manually specify an upper-level dependent node first.
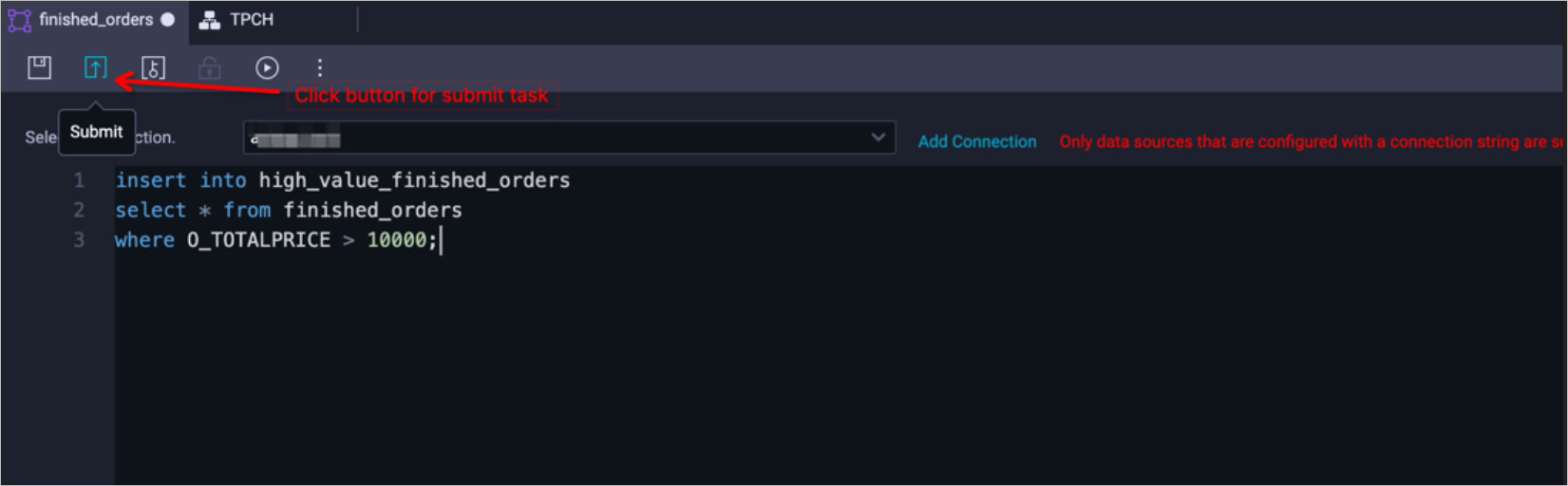
Publish tasks
Select the submitted tasks and click the publish icon.
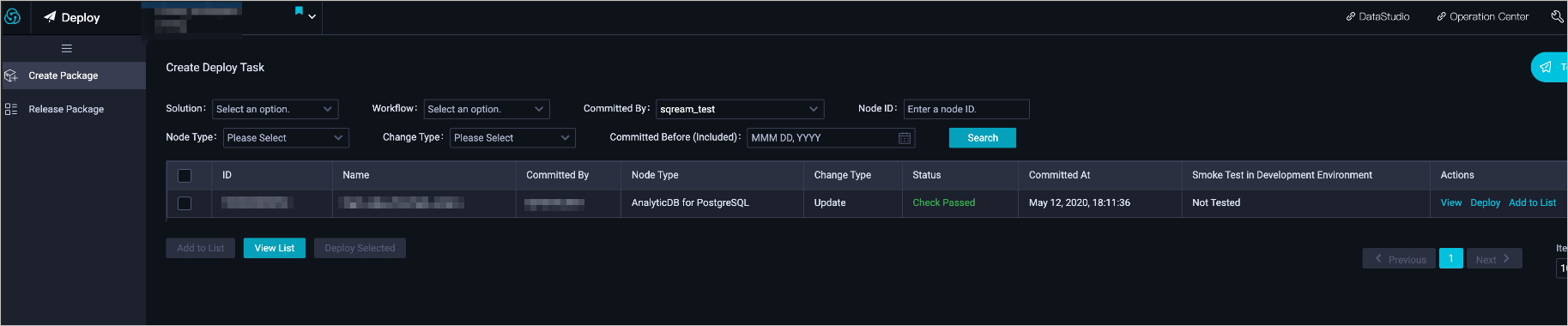
You can view published tasks on the published task list page.
After the tasks are published, you can maintain them on the task O&M page.