AnalyticDB for PostgreSQL supports static partition pruning and dynamic partition pruning. If partition pruning is enabled for a query on a partitioned table, the system skips unnecessary partitions based on the partition constraints and definitions. This reduces the amount of data that needs to be scanned and improves query performance.
AnalyticDB for PostgreSQL supports column-based partitioning. A fact table can be split into multiple partitions. The system scans only the partitions that meet specified query conditions. This improves query performance. Partition pruning is a performance optimization method commonly used for partitioned tables.
Limits
Partition pruning is applicable only to partitioned tables.
Partition pruning supports only the range, equation, and IN predicates on range or list partition columns. AnalyticDB for PostgreSQL V7.0 supports hash partitions. Hash partitions can be pruned only by using equivalence conditions.
Dynamic partition pruning supports only equivalence conditions such as
=andINon partition columns.The effect of partition pruning is related to the distribution of data. If partition constraints fail to effectively prune partitions, the performance degrades and the entire table is scanned.
Static partition pruning
Overview
If the partition constraint is a definite expression, you can use the partition constraint expression to exclude unnecessary partitions from the execution plan before query execution. This method is called static partition pruning.
AnalyticDB for PostgreSQL uses static predicates to determine the time when to perform static partition pruning. The following static predicates are supported: =, >, >=, <, <=, and IN.
You can obtain the result of static partition pruning from the response of an EXPLAIN statement.
Examples
Example 1: Use the
=predicate to perform partition pruning-- Create a partitioned table. CREATE TABLE sales (id int, year int, month int, day int, region text) DISTRIBUTED BY (id) PARTITION BY RANGE (month) SUBPARTITION BY LIST (region) SUBPARTITION TEMPLATE ( SUBPARTITION usa VALUES ('usa'), SUBPARTITION europe VALUES ('europe'), SUBPARTITION asia VALUES ('asia'), DEFAULT SUBPARTITION other_regions) (START (1) END (13) EVERY (1), DEFAULT PARTITION other_months ); -- Perform partition pruning. EXPLAIN SELECT * FROM sales WHERE year = 2008 AND month = 1 AND day = 3 AND region = 'usa';The query conditions fall on the level-2 partition
'usa'of the level-1 partition 1. Therefore, only the data in the level-2 partition 'usa' is scanned during the query. The response of the EXPLAIN statement shows that only one of the 52 level-2 partitions is scanned (Partitions selected: 1).Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=24) -> Sequence (cost=0.00..431.00 rows=1 width=24) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) Partitions selected: 1 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24) Filter: ((year = 2008) AND (month = 1) AND (day = 3) AND (region = 'usa'::text))Example 2: Use the
>=andINpredicates to perform partition pruningEXPLAIN SELECT * FROM sales WHERE month in (1,5) AND region >= 'usa'; QUERY PLAN ----------------------------------------------------------------------------------------------------- Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=24) -> Sequence (cost=0.00..431.00 rows=1 width=24) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) Partitions selected: 6 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24) Filter: ((month = ANY ('{1,5}'::integer[])) AND (region >= 'usa'::text))
Static partition pruning does not support operators such as LIKE and <>. For example, if you change the WHERE condition to region LIKE 'usa', partition pruning cannot be performed.
EXPLAIN
SELECT * FROM sales
WHERE region LIKE 'usa';
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=24)
-> Sequence (cost=0.00..431.00 rows=1 width=24)
-> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4)
Partitions selected: 52 (out of 52)
-> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24)
Filter: (region ~~ 'usa'::text)Dynamic partition pruning
Overview
For PREPARE-EXECUTE scenarios in which the partition constraint expression contains subqueries, the partition constraint cannot be obtained from the execution plan before query execution. You must use external parameters and subquery responses to perform partition pruning during query execution. This method is called dynamic partition pruning.
You can obtain the result of dynamic partition pruning from the response of an EXPLAIN ANALYZE statement.
Use dynamic partition pruning to optimize JOIN operations
For data warehousing scenarios in which you want to join fact tables and dimension tables, AnalyticDB for PostgreSQL allows you to optimize JOIN operations on partitioned fact tables by using dynamic partition pruning.
In most cases, fact tables are large and dimension tables are small. If a join key is used as the partition key of a fact table (large table), AnalyticDB for PostgreSQL dynamically generates a partition constraint for the large table based on the data of a dimension table (small table). This way, the system skips unnecessary partitions to reduce the amount of data that the JOIN operators involve.
Dynamic partition pruning uses the data of the internal table of a JOIN operator to dynamically generate a partition filter for the external table (partitioned table). This helps skip unnecessary partitions. The following figure shows the process of joining a partitioned large table and a small table without dynamic partition pruning.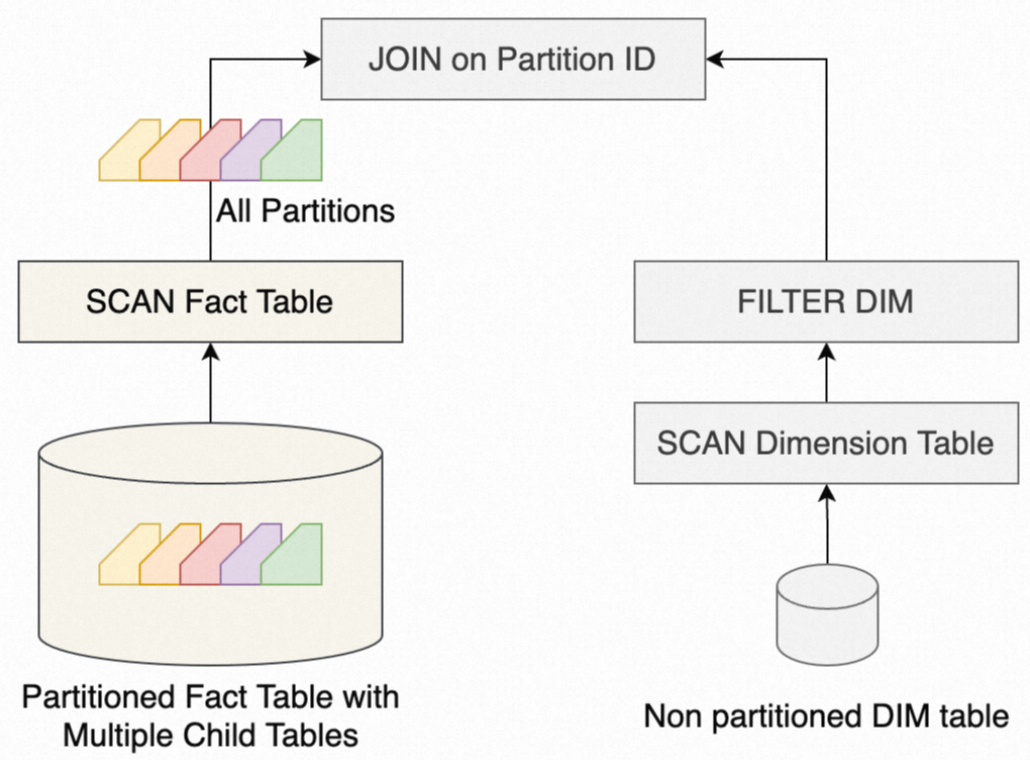
If the join key is used as the partition key, all partitions in the partitioned table need to be scanned before they are joined with the small table. If dynamical partition pruning is enabled, the system first scans the small table, generates a partition filter, and then sends the partition filter to the SCAN operator of the large table. This way, only some partitions are scanned and sent to the JOIN operator. The following figure shows the process of joining a partitioned large table and a small table with dynamic partition pruning.
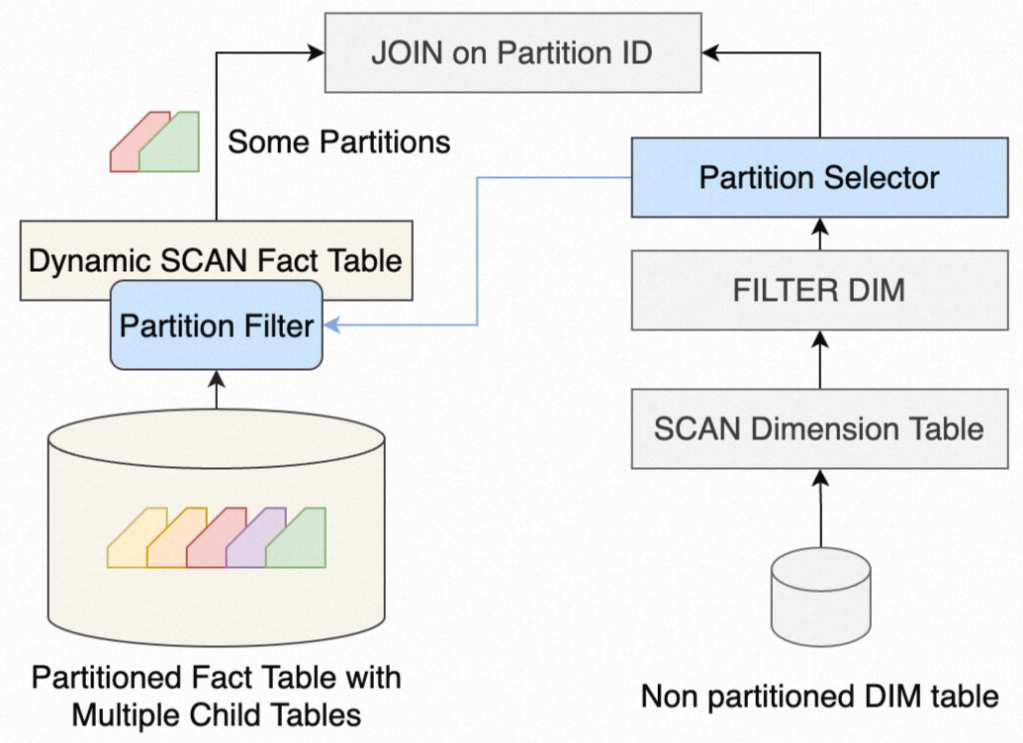
We recommend that you use dynamic partition pruning to accelerate joins of large tables and small tables based on partitioned large tables.
Examples
Example 1: Perform dynamic partition pruning if the WHERE clause contains a subquery
CREATE TABLE t1 (a int, b int); INSERT INTO t1 VALUES (3,3), (5,5); EXPLAIN ANALYZE SELECT * FROM sales WHERE month = ( SELECT MIN(a) FROM t1 );The WHERE clause contains a subquery whose response is unavailable from the execution plan before query execution. You can obtain the partition constraint only during query execution. The INSERT INTO VALUES statement shows that the value of
MIN(a)is 3. In this case, only four partitions whose value of themonthcolumn is 3 are scanned from thesalestable. This result can be verified from the response of the EXPLAIN ANALYZE statement (Partitions scanned: Avg 4.0).Gather Motion 3:1 (slice3; segments: 3) (cost=0.00..862.00 rows=1 width=24) (actual time=5.134..5.134 rows=0 loops=1) -> Hash Join (cost=0.00..862.00 rows=1 width=24) (never executed) Hash Cond: (sales.month = (min((min(t1.a))))) -> Sequence (cost=0.00..431.00 rows=1 width=24) (never executed) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) (never executed) Partitions selected: 52 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (cost=0.00..431.00 rows=1 width=24) (never executed) Partitions scanned: Avg 4.0 (out of 52) x 3 workers. Max 4 parts (seg0). -> Hash (cost=100.00..100.00 rows=34 width=4) (actual time=0.821..0.821 rows=1 loops=1) -> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=34 width=4) (actual time=0.817..0.817 rows=1 loops=1) -> Broadcast Motion 1:3 (slice2) (cost=0.00..431.00 rows=3 width=4) (actual time=0.612..0.612 rows=1 loops=1) -> Aggregate (cost=0.00..431.00 rows=1 width=4) (actual time=1.204..1.205 rows=1 loops=1) -> Gather Motion 3:1 (slice1; segments: 3) (cost=0.00..431.00 rows=1 width=4) (actual time=1.047..1.196 rows=3 loops=1) -> Aggregate (cost=0.00..431.00 rows=1 width=4) (actual time=0.012..0.012 rows=1 loops=1) -> Seq Scan on t1 (cost=0.00..431.00 rows=1 width=4) (actual time=0.005..0.005 rows=2 loops=1)Example 2: Use dynamic partition pruning to optimize JOIN operations
EXPLAIN SELECT * FROM sales JOIN t1 ON sales.month = t1.a WHERE sales.region = 'usa';The
t1table contains only two records:(3,3)and(5,5). If the t1 table is joined with thesalestable based on the partition keymonth, dynamic partition pruning scans only the partitions whose values of themonthcolumn are 3 and 5. The sample statement shows that the value of theregioncolumns is set to'usa'. In this case, only two partitions are scanned. This result can be verified from the response of the EXPLAIN ANALYZE statement (Partitions scanned: Avg 2.0).QUERY PLAN --------------------------------------------------------------------------------------------------------------- Gather Motion 3:1 (slice2; segments: 3) (actual time=3.204..16.022 rows=6144 loops=1) -> Hash Join (actual time=2.212..11.938 rows=6144 loops=1) Hash Cond: (sales.month = t1.a) Extra Text: (seg1) Hash chain length 1.0 avg, 1 max, using 2 of 524288 buckets. -> Sequence (actual time=0.317..4.197 rows=6144 loops=1) -> Partition Selector for sales (dynamic scan id: 1) (never executed) Partitions selected: 13 (out of 52) -> Dynamic Seq Scan on sales (dynamic scan id: 1) (actual time=0.311..3.391 rows=6144 loops=1) Filter: (region = 'usa'::text) Partitions scanned: Avg 2.0 (out of 52) x 3 workers. Max 2 parts (seg0). -> Hash (actual time=0.316..0.316 rows=2 loops=1) -> Partition Selector for sales (dynamic scan id: 1) (actual time=0.208..0.310 rows=2 loops=1) -> Broadcast Motion 3:3 (slice1; segments: 3) (actual time=0.008..0.012 rows=2 loops=1) -> Seq Scan on t1 (actual time=0.004..0.004 rows=1 loops=1)
FAQ
Q: How do I check whether partition pruning is performed on my query?
A: You can execute an EXPLAIN statement and view the response of the statement. If
Partition Selectoris displayed, partition pruning takes effect.Q: Is partition pruning supported for both the native PostgreSQL optimizer and ORCA?
A: Yes, both the planner and ORCA support static or dynamic partition pruning. Their execution plans are slightly different.
Q: Why did my partition pruning fail?
A: Partition pruning requires filtering or joining data based on the partition key. For static partition pruning, only
=,>,>=,<,<=, and IN are supported. For dynamic partition pruning, only equivalence conditions are supported.