AnalyticDB for PostgreSQL is a cloud native massively parallel processing (MPP) data warehouse built on the Alibaba Cloud ecosystem, designed for large-scale analytics on petabytes of data.
With AnalyticDB for PostgreSQL, you can:
-
Run real-time interactive analysis, extract, transform, load (ETL) and extract, load, transform (ELT) operations, and business intelligence (BI) report visualization on petabytes of data
-
Write data in real time and import data in batches with high throughput
-
Get atomicity, consistency, isolation, and durability (ACID) guarantees and standard transaction isolation
SQL compatibility and protocol support
AnalyticDB for PostgreSQL supports JDBC and ODBC connections and is fully compatible with the SQL:2003 syntax standard, PostgreSQL, and Greenplum, and partially compatible with Oracle syntax. AnalyticDB for PostgreSQL provides PL/pgSQL stored procedures, Apache MADLib for machine learning, and PostGIS for geometry analysis.
Use standard SQL to perform hybrid analysis across all three data types:
-
Structured data: tables, relational schemas
-
Semi-structured data: JSON and JSONB format
-
Unstructured data: images, audio files
Deployment options
| Deployment | Details |
|---|---|
| Alibaba Cloud public cloud | Pay-as-you-go pricing; supports vertical and horizontal scaling; supports separate online storage scaling |
| Hybrid cloud | Apsara Stack Enterprise and Apsara Stack Agility, deployed using DBStack |
| Platform support | x86 and ARM platforms |
Performance benchmarks
AnalyticDB for PostgreSQL ranks first in the TPC Benchmark-H (TPC-H) 30 TB cost-effectiveness list. It also passes both the TPC Benchmark-C (TPC-C) transactional performance test and the TPC Benchmark-DS (TPC-DS) 100 TB 640-node analytical performance test, both organized by the China Academy of Information and Communications Technology (CAICT).
Architecture
AnalyticDB for PostgreSQL uses a two-tier architecture: coordinator nodes handle query planning and transaction management, while compute nodes handle query execution and data storage. The nodes are interconnected for data transmission.
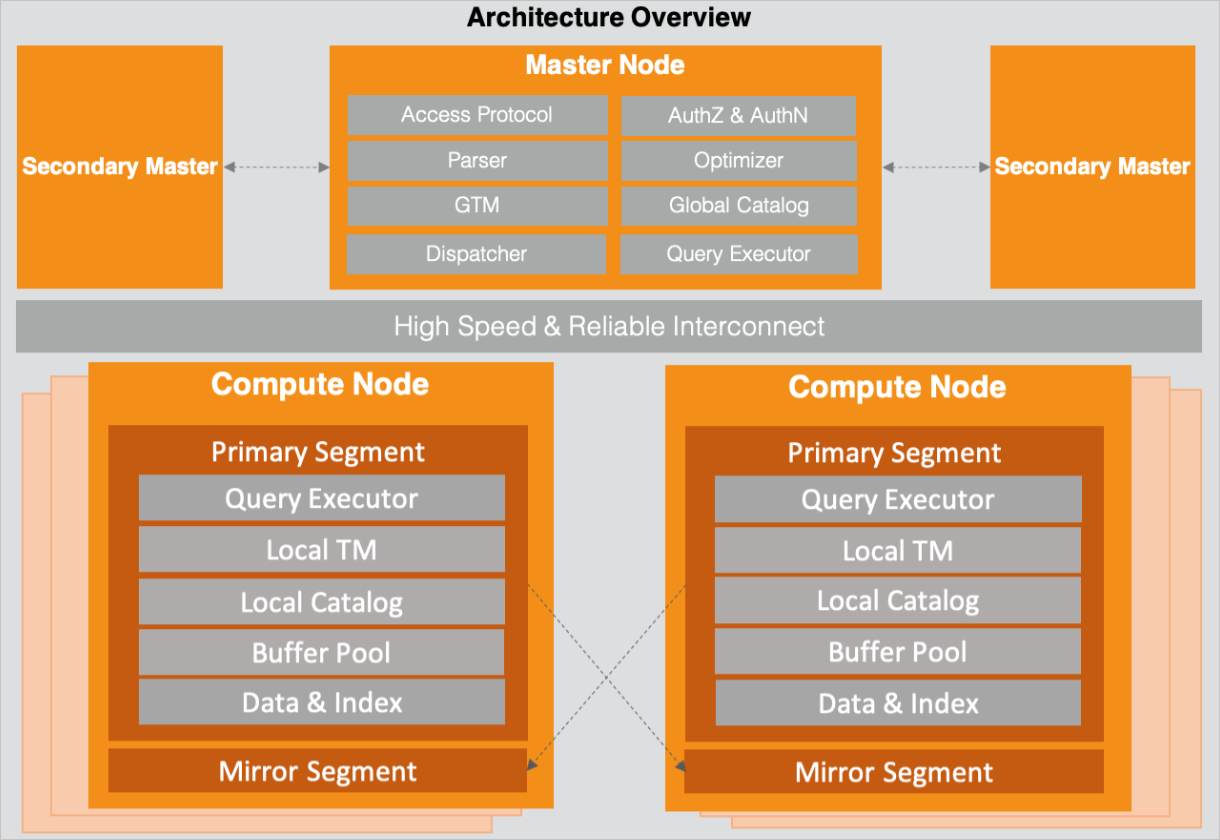
Both coordinator nodes and compute nodes maintain multiple replicas for high availability and data reliability. Scale out either node type to increase the concurrency and throughput of read and write queries.
Components
Coordinator node — query planning and transaction management
Coordinator nodes are the entry point for all client connections. They handle authentication and authorization, then act as parsers, rewriters, optimizers, and dispatchers for incoming queries.
Coordinator nodes also serve as the global transaction manager (GTM): generating snapshots and global transaction IDs, managing distributed transactions, and maintaining the global catalog that records metadata for all database objects — users, databases, tables, views, indexes, and distributed partitions.
Compute node — query execution and local storage
A compute node is a set of segments running on a physical machine, virtual machine (VM), or container.
Segment — the execution unit
Each segment handles SQL execution and data storage. To minimize round-trips to coordinator nodes, the segment's local catalog stays synchronized with the global catalog. A local transaction manager coordinates transactions within the segment, and a buffer pool caches reads and writes to improve I/O performance.
The query executor uses a vectorized execution engine and just-in-time (JIT) compilation, improving calculation performance by multiple times compared with the row-by-row volcano model.
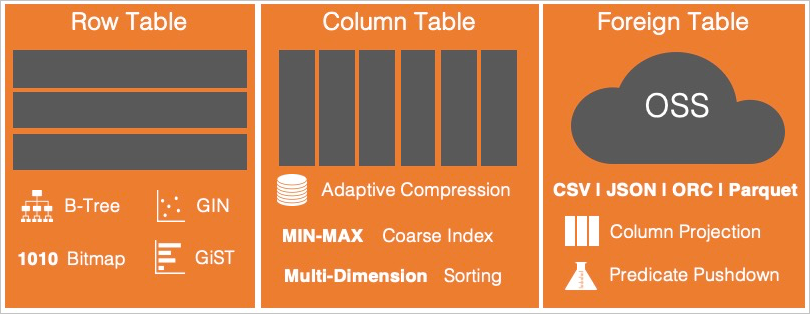
Storage types
Choose the storage type based on your workload:
-
Row store tables: Optimized for live write, update, and delete operations, point queries, and range queries. Data is stored by row, orderable by primary key. Supports B-tree, bitmap, and GIN indexes. Transactions are managed using Multi-Version Concurrency Control (MVCC).
-
Column store tables: Optimized for batch analytical queries where updates and deletes are infrequent. Data is stored by column with high compression. Supports B-tree indexes for point queries and lightweight block range indexes using min/max values. Multi-column sorting enables efficient composite condition filtering.
-
External tables: Query metadata stored in local system tables, and data stored in Object Storage Service (OSS), Hadoop Distributed File System (HDFS), or Apache Hive without loading it into the database. Supports ORC, Parquet, CSV, and JSON formats. ORC and Parquet files support column filtering and predicate pushdown for faster analytical queries. External tables are partitionable.
Partitioned tables can mix storage types across partitions. For example, use row store for the current month's partition (frequent writes), column store for archived months (batch reads), and OSS external tables for older partitions with low query volume.
Data distribution
When creating a table, choose a data distribution strategy to control how rows are spread across compute nodes. Even distribution maximizes I/O performance, storage utilization, and query efficiency.
| Strategy | When to use |
|---|---|
| Hash distribution (default) | Most tables. Rows are distributed based on a hash column you specify. |
| Replication distribution | Small tables on which associated queries are frequently performed. Each compute node holds a full copy, so no data broadcast or redistribution is needed at query time. |
| Random distribution | Large tables where no suitable hash column exists — for example, when any candidate key would cause data skew across nodes. |
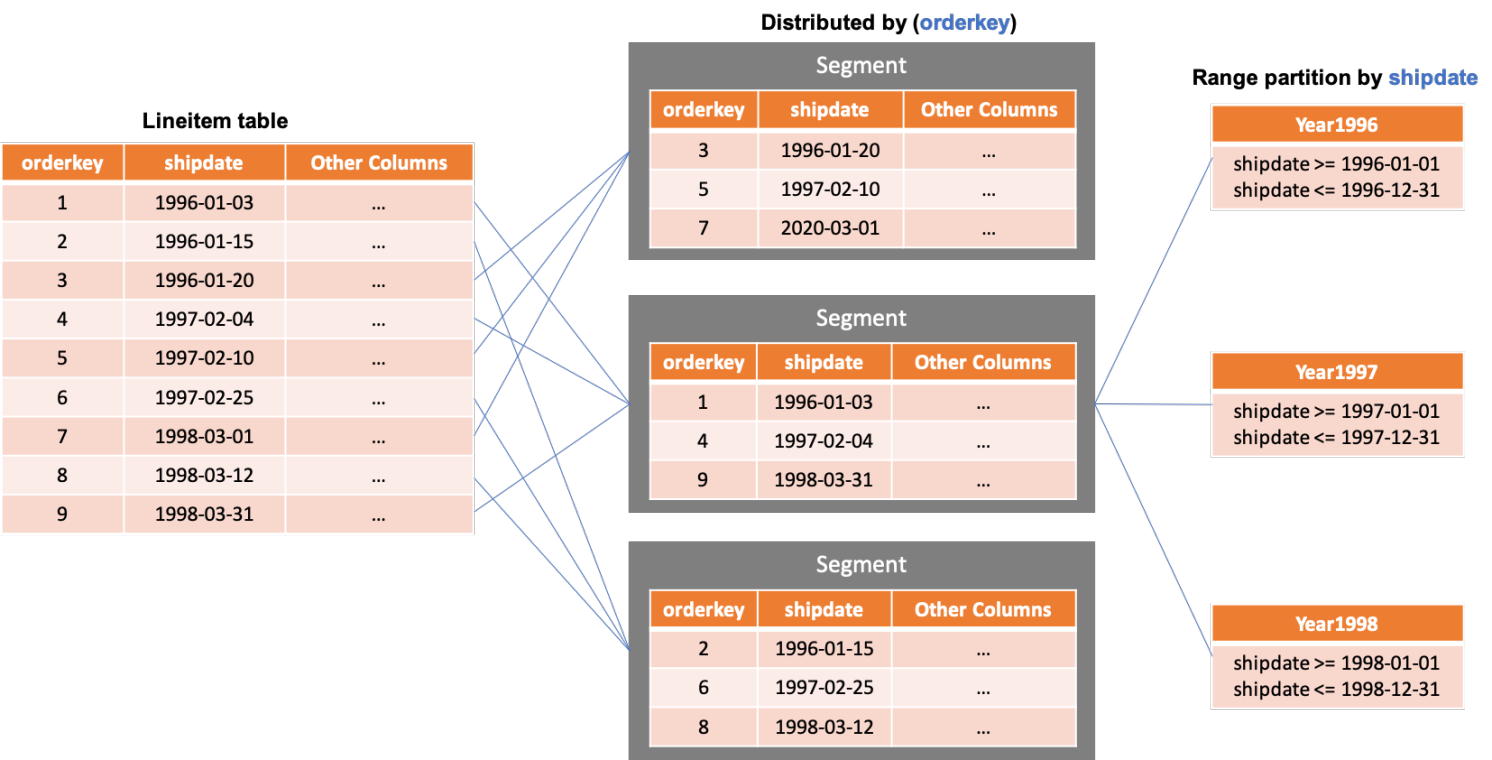
After distributing data across compute nodes, partition the data on each node to narrow the scope of specific queries. AnalyticDB for PostgreSQL supports range and list partitioning, and multi-level partitions. In the following figure, a hash table is distributed across three nodes on the id column. Range partitioning is then applied on the date column, followed by list partitioning on the city column. Each partition stores its own data and indexes.
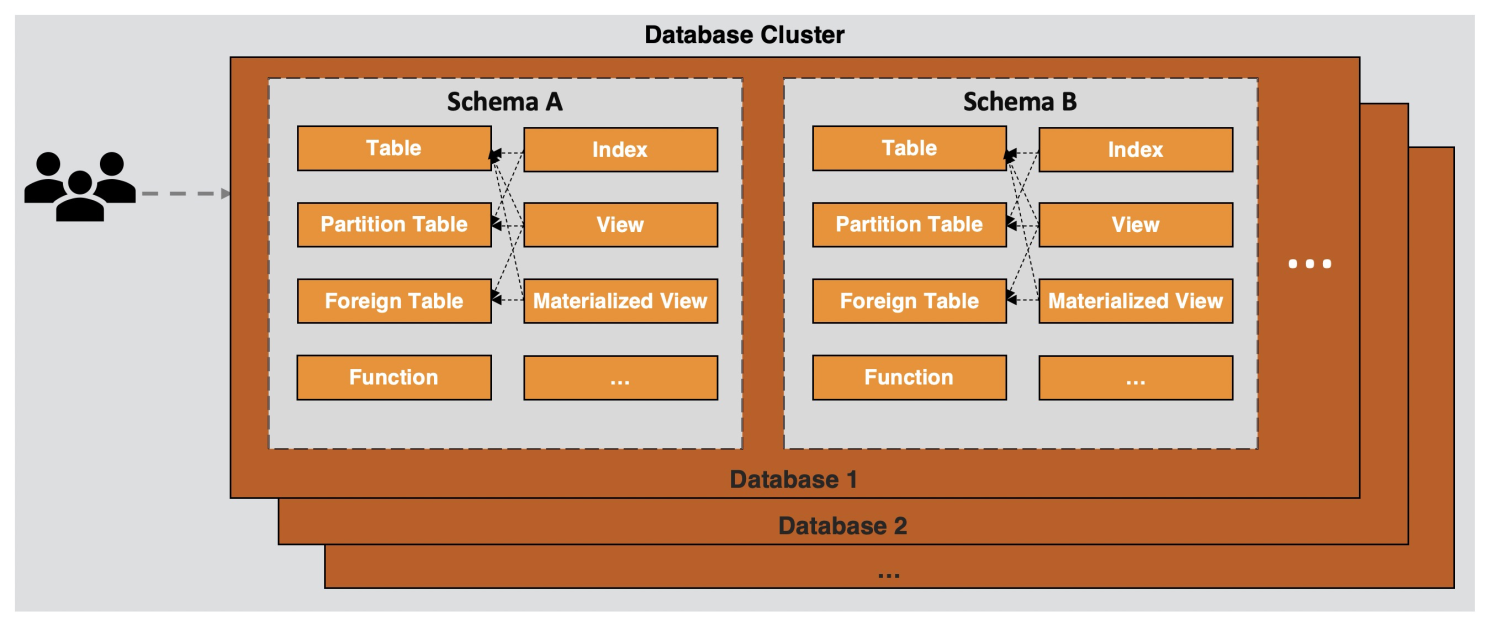
Database objects
AnalyticDB for PostgreSQL is an object-relational database. Customize objects and their properties — data types, functions, operators, domains, and indexes — to model complex data structures.
Database objects include tables, views, functions, sequences, indexes, partitioned child tables, and external tables. Objects are organized into schemas:
-
Schema: A logical namespace within a database. After a database is created, a
publicschema is created by default. All users and roles can accesspublic, and objects created without an explicit schema are placed there. -
Database: A physical collection of database objects. To connect to a database (for example, through the Data Management (DMS) console), a user must specify which database to connect to.
-
Users and roles: Control instance-level permissions and manage access to all objects. By default, a user cannot view objects they don't own. Grant the required permissions to allow access to objects in other schemas. Every user has permission to create objects in the
publicschema by default.
AnalyticDB for PostgreSQL stores all objects as system metadata on both coordinator and compute node servers.