Apache Spark is an open source distributed processing system that is used to process big data workloads. Apache Spark supports SQL and allows you to write DataFrames in multiple programming languages. This makes Apache Spark flexible and easy to use. The Spark engine can provide capabilities such as SQL, batch processing, stream processing, machine learning, and graph computing.
AnalyticDB for MySQL Serverless Spark is a big data analysis and computing service that is developed by the AnalyticDB for MySQL team on top of Apache Spark. After you create an AnalyticDB for MySQL cluster, you can configure simple settings to submit Spark jobs without the need for Spark cluster deployment. The following figure shows the architecture of AnalyticDB for MySQL Serverless Spark.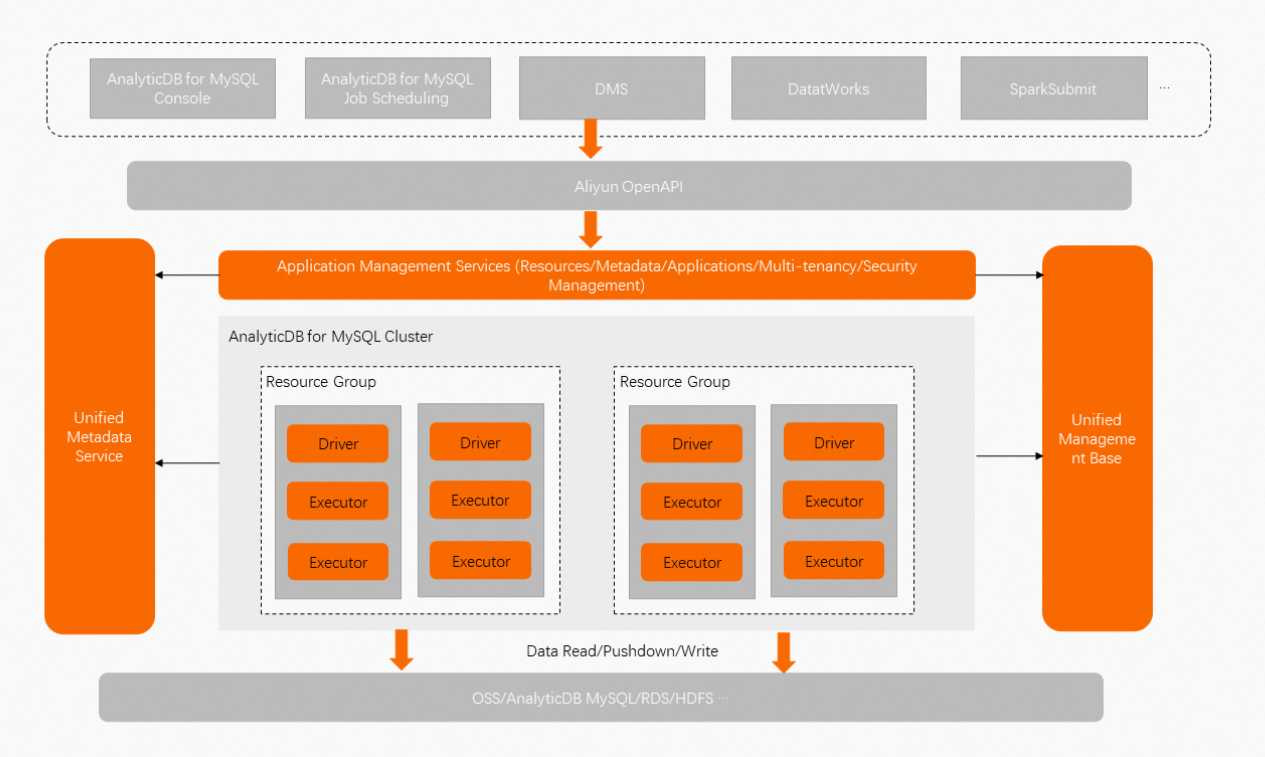
Serverless Spark is an in-depth integration of Spark, Serverless, and cloud-native technologies. Compared with Apache Spark, Serverless Spark has the following advantages:
Ease of use
Serverless Spark provides simple APIs, scripts, and console operations to help you perform big data development in the same way as you use Apache Spark without the need to configure underlying components.
O&M-free
AnalyticDB for MySQL Serverless Spark helps you manage Spark jobs without the need for server configurations, Hadoop configurations, or resource scaling.
Job-level scalability
Serverless Spark allows you to purchase resources for the driver and executor processes of each job. You can pull up resources within seconds to quickly respond to resource requirements.
Reduced costs
You can scale up resources on demand to perform Spark jobs without the need to retain reserved resources. You are charged for the scaled resources. If no resources are used, no fees are generated.
Enhanced performance
The AnalyticDB for MySQL team performs in-depth customization and optimization on the Spark engine, and integrates Apache Spark with AnalyticDB for MySQL data warehouses. In typical scenarios, the performance of accessing Object Storage Service (OSS) data is up to five times that of Apache Spark, and the connection performance is up to six times that of a Java Database Connectivity (JDBC) connection. In addition, a zero-ETL solution is provided on top of AnalyticDB for MySQL and Apache Spark.